Introduction
기존 Speech-Text Foundation Model은 독립적 요소들의 파이프라인에 의존함. 하지만 이러한 기존 방식은 실제 대화를 모방하기에는 한참 뒤쳐지고 있음
→ 이를 극복한 모델 “Moshi”
Speech-to-Speech 생성 방식 비교: 기존 모델 vs Moshi
- 기존 Speech-Text Foundation Model
- 과정: 음성 → (ASR) → 텍스트 → (텍스트 대화 모델) → 텍스트 → (TTS) → 음성
- 구조: ==여러 독립적인 모듈==로 구성된 파이프라인
- 이러한 기존 Speech-Text Foundation Model은 진짜 리얼한 대화를 가능케 하기에는 몇 가지 문제점이 있음
- 높은 지연시간: 각 모듈의 처리 지연이 누적되어 수 초 단위의 응답 지연 발생
- 정보 손실: 감정, 억양, 말투 등 음성 특성 정보가 텍스트 변환 과정에서 소실
- 턴 기반 한계: 사용자 간 대화가 끝난 이후 대화를 이어가야 하는, 턴 기반 방식의 한계점 → 대화 중첩, 끼어들기 등 자연스러운 대화 동역학 처리 불가
- 최적화 어려움: 모듈별 오류가 전체 성능에 영향 → 통합 최적화가 복잡
- Moshi
- 해결책
- ==Speech-to-Speech== 생성으로 음성 대화를 재정의
- 기존 speech-text foundation model
- 음성 입력 → ASR(음성 인식) → 텍스트 → NLP(텍스트 처리) → 텍스트 → TTS(음성 합성) → 음성 출력
- 각 과정마다 별개 모델·시스템을 써서 지연 발생 및 비언어적 정보(억양, 감정, 끊김 등) 손실
- Moshi
- 음성 입력 → ==곧바로(End-to-End) 음성 출력==
- 중간 텍스트 변환 과정 없음 → 입력 음성을 바로 출력 음성으로 생성
- 기존 speech-text foundation model
- Multi-Stream 아키텍처 → 사용자와 시스템 음성을 ==병렬 스트림으로 분리==
- 기존 문제점
- 턴(순서) 기반 대화 → 한 명이 완전히 끝나야 다음이 발화(실제 대화와 다름)
- 겹치는 발화·동시 말하기(“네, 그런데요-아 네네…”) 같은 실제 대화의 동역학을 제대로 모델링하지 못함
- Moshi의 Multi-Stream
- 참여자(사용자/AI)별로 ==서로 다른 음성 스트림을 병렬==로 모델링/처리
- 시스템 입장에선 항상 듣고, 항상 말할 수 있음
- 즉, full-duplex 대화 가능: 동시에 듣고 말하는 현실 대화
- ex) 사용자가 말하는 도중 AI가 “네, 그 부분은-” 같이 끼어들기/동시 발화 가능
- 기존 문제점
- Inner Monologue
- 모델 내부에서 먼저 텍스트 수준의 독백을 생성 → 이를 기반으로 음성 출력 생성
- Moshi의 Inner Monologue → 단순한 음성→음성 변환이 아님 / ==시간 정렬된 텍스트 토큰을 오디오 토큰의 접두어로 예측== 1) 음성 입력 → 내부적으로 시간 정렬된 텍스트 토큰 시퀀스(Inner Monologue) 생성 - ex : “내일 오후 비옵니다”라는 텍스트를, 실제 발화 타이밍(프레임)에 맞게 토큰별로 정렬 2) 이 텍스트를 오디오(음성) 토큰 생성의 접두사(prefix)로 삼아 ‘무엇을, 언제’ 말할지를 결정 - 각 시간 프레임(예: 80ms 단위)마다 → 이전까지 생성된(혹은 들은) 텍스트 토큰들만을 보고 → 다음(해당 시점)의 오디오(음성) 토큰을 예측 - 예: (PAD, 내, 일, 오, 후, 비, 옵, 니, 다, PAD, PAD…) - PAD는 아무 말도 안 하는 빈시간 - 실제 “내일”이 발화되는 순간 → “내” 토큰, 다음에는 “일” 토큰 형태 3) 각각의 시간 프레임(80ms 단위 등)마다, 해당 시점에 맞는 텍스트 토큰을 접두어로 붙임 → 그 다음 예측할 오디오 토큰 생성 - ex) 가장 처음 프레임의 토큰은 PAD - 첫번째 시간 프레임: (PAD) → 해당 구간의 오디오 토큰 예측 - 두번째 시간 프레임: (내) → 해당 구간의 오디오 토큰 예측 - 세번째 시간 프레임: (일)… - PAD/EPAD 토큰으로 “말 없는 구간도” 구분 → 정확한 타이밍 구현 4) 최종적으로 자연스러운 음성(오디오) 출력
- Inner Monologue가 Moshi에서 중요한 역할 수행
- 과정 중간에 텍스트/언어 정보를 명시적으로 활용하면,
- 질문-답변, 정보성 대화 등에서 ==언어적 정확성과 일관성==이 크게 상승
- 내부적인 텍스트 정렬로 ==음성-텍스트 경계가 명확==해져 품질 개선
- 과정 중간에 텍스트/언어 정보를 명시적으로 활용하면,
- ==Speech-to-Speech== 생성으로 음성 대화를 재정의
- 과정
- 음성 입력 → (내부적으로 시간 정렬 텍스트 토큰(Inner Monologue) 생성) → 해당 텍스트를 오디오 토큰의 접두어로 활용 → 최종 음성 출력
- 외관상 ‘음성→음성’, 내부적으로는 ==’음성→텍스트(내적 독백)→음성’== 구조가 섞여 있음
- 구조
- 통합된 end-to-end multi-stream 모델, 사용자와 시스템 음성을 병렬 처리
- 내부적으로 Inner Monologue를 명시적으로 활용
- 장점:
- 초저지연 처리(이론적 160ms, 실제 200ms, 거의 실시간 대화 가능)
- 비언어적 정보 보존: 감정, 억양, 끼어들기, 대화겹침 등
- 동시 발화 등 자연스러운 대화 동역학(Full-Duplex) 지원
- Inner Monologue 메커니즘 → 모델 내부에서 텍스트 표현을 생성하여 음성 품질과 사실성 향상
- 단일 통합 구조 → 오류 전파 최소화, 최적화 용이
- 해결책
Model
Overview
Moshi는 4개의 주요 컴포넌트로 구성된 통합 아키텍처
- Helium : 텍스트 언어 모델 백본 - 추론·지식 담당
- Mimi : 신경 오디오 코덱 - 음성↔토큰 변환 담당
- RQ-Transformer : 계층적 오디오 토큰 생성 - 시간·깊이 처리 담당
- Multi-Stream + Inner Monologue : 전이중(full-duplex) 대화 + 내적독백 - 실시간 대화 담당
Moshi 통합구조
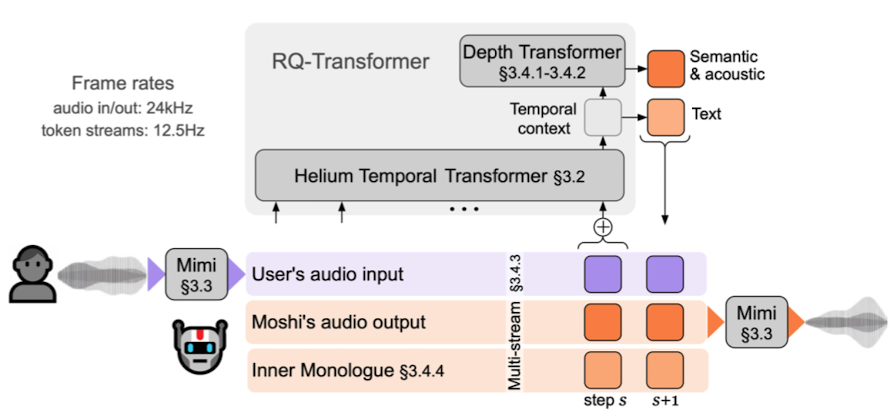
사용자와 Moshi 간 상호작용 과정
- 음성 입력 처리
- By Mimi encoder → 음성을 숫자로 바꿔줌 / 매 80ms 별 8개의 정수 토큰으로 압축
- 사용자로부터 음성 파형이 입력되면, Mimi 인코더를 거쳐 오디오 토큰 시퀀스로 변환
- 이렇게 변환된 오디오 토큰 시퀀스는 아래와 같은 두 부분에 동시 입력됨
- Multi-Stream의 “User’s audio input”에 저장
- 시간 순서대로 기록되어 차곡차곡 쌓임
- 후속 처리, 대화 이력 복기 등에 활용
- Helium Temporal Transformer(즉, RQ-Transformer 전체)의 입력(Context)
- 매 시점(step)마다 현재까지의 사용자 오디오 토큰 시퀀스 전체를 입력받음
- Context(AI(모델)가 무엇을 어떻게 반응해야 할지 추론)의 용도로 적극 활용
- Multi-Stream의 “User’s audio input”에 저장
- ex) 사용자가 “내일 날씨 어때?”라고 말하는 상황

- Multi-Stream
- 실제 데이터가 시간의 흐름(Stream)대로 “실시간으로” 차곡차곡 쌓이는 구간
- 크게 3가지 정보가 저장
- User’s audio input (보라색 칸)
- 사용자의 입력 오디오 토큰
- ex) 사용자가 “안녕” 말하면, 그 사운드가 Mimi 인코더에 의해 토큰 시퀀스로 변환되어 여기에 쌓임
- Moshi’s audio output (주황색 칸):
- AI가 만들어낼 오디오 토큰(답변, 반응 등)
- ex) 모델이 이 상황을 판단해 “네, 안녕하세요”라고 응답하려면, 해당 응답 오디오를 토큰화해서 이 칸에 만듦
- Inner Monologue (주황 테두리 칸)
- AI가 내부적으로 시간에 맞게 생성하는 텍스트(내적 독백, 비유하면 AI가 혼자 생각해두는 부분) 토큰
- ex) Moshi가 응답을 준비하며 “이번엔 인사해야지” 같은 텍스트를, 발화 타이밍에 맞춰 프레임단위로 생성
- User’s audio input (보라색 칸)
- Inner Monologue
- Depth Transformer의 첫 번째 Step에 끼어들어, 모델 자체적으로 내적 독백 텍스트 토큰을 생성
- Multi-Stream → RQ-Transformer 전송 데이터
- Helium에서 Multi-Stream의 전체 맥락을 요약하기 위한 여러가지 정보를 입력받음
- RQ-Transformer
- Multi-Stream 영역에 쌓인 데이터를 받아서, 이해하고, AI 토큰을 생성
- 사용자의 신호를 받아서 AI가 어떻게 반응할지 결정하는 역할
- 2단계 계층 구조로 구성
- Helium Temporal Transformer (7B) → “시간 흐름 이해”
- 앞선 3가지 Multi-Stream의 전체 맥락을 고차원 벡터로 요약
- 각 step 별로, “지금까지의 대화 상황”을 계산하여 다음 행동 결정
- Depth Transformer(세부 토큰 생성)
- Helium이 제공한 맥락 정보(Temporal context)를 바탕으로, 아래 정보들을 순차적으로 생성
- Inner Monologue(텍스트)
- Semantic/acoustic 토큰(AI 응답용 오디오 토큰)
- 즉, 실제 “지금 시점에 무슨 말을 해야하지?”, “어떤 음성으로 내보내지?”와 같은 결정을 시간별로 정리
- Helium이 제공한 맥락 정보(Temporal context)를 바탕으로, 아래 정보들을 순차적으로 생성
- Helium Temporal Transformer (7B) → “시간 흐름 이해”
- 사용자 오디오 토큰을 보고 → AI가 응답할 오디오 토큰들을 새로 생성
- RQ-Transformer → Multi-Stream 전송 데이터
- 실제로 아래 칸(스트림)에 들어가는 토큰들은 위 Transformer에서 만드는 것!
- 매 스텝/프레임마다 Helium+Depth Transformer가 데이터(토큰들)를 계산해서 아래칸에 채워줌
- 음성 출력 생성
Mimi Encoder
사용자 음성을 받아서 사용자 오디오 토큰으로 변환시켜주는 인코더
기능
- 24kHz로 연속 음성 파형 생성 → 이산적 정수 토큰 시퀀스로 변환
- 실시간 스트리밍 호환 (80ms 단위로 처리 가능)
- 의미 정보와 음향 정보를 모두 보존하면서 압축
전체 아키텍처 구조(Decoder까지)
- 음성 파형 샘플링(24kHz)
- SeaNet 인코더 → Latent representation 생성(512차원, 12.5Hz)
- Transformer 후처리 → SeaNet 인코더의 출력 결과에 맥락 보강
- Split RVQ 양자화 → 최종 토큰 8개로 압축(의미 VQ 1개, 음향 RVQ 7개)
과정 상세
- 음성 파형 샘플링(24kHz)
- 16kHz보다 풍부한 발음 품질
- 16kHz(ASR, TTS 등에서 자주 사용)만으로도 사람 목소리의 기본 정보는 충분
- 세부 묘사를 위한 더 정밀한 억양, 감정, 입모양·마찰음·소리끝 노이즈 등의 표현은 24kHz가 훨씬 자연스럽고 선명
- 고품질 음성 생성 필요
- 고급 TTS/ASR/대화형 AI의 최신 표준으로 24kHz를 많이 활용
- 계산 효율·압축의 균형
- 32kHz 이상을 사용하면 파일 크기·계산량이 급증 → 24kHz가 실시간 처리에 가장 효율이 최적화됨
- 16kHz보다 풍부한 발음 품질
- SeaNet 인코더
- 역할
- 매우 긴 “연속 오디오 데이터”를 → 훨씬 짧고 압축된 “유의미한 벡터 시퀀스”로
- 전체 구조
- 24kHz의 PCM 음파 입력
- 여러 개의 Conv. 블록을 거치며 시간적으로 점점 압축(짧은 길이로, 더 높은 차원으로)
- 모두 거치고 나면 결과적으로 12.5Hz의 프레임 시퀀스 출력(각 프레임 별 512차원)
- Convolution 구조 채택 이유
- 인접 구간(=여러 샘플)을 조금씩 겹치게 관찰 → 그 안의 특징(발음, 주파수, 소리의 변화)을 집약/추출
- Conv 레이어의 스택을 쌓으면 → 초기에는 짧은 구간의 특징, 뒤로 갈수록 장기적인 맥락 파악 가능
- 초반에는 빠른 변화(입술 터치/자음 등)
- 후반에는 느린 변화(문장 억양, 리듬 등)
- Convolution Stack의 압축 과정 상세

- Conv 4단계 통과한 후, 마지막 1D Conv로 최종 12.5Hz로 압축
- 80ms마다 오디오 특성이 하나의 벡터(512차원)로 정리
- 기타 적용 기술
- 인과적 Convolution
- “현 시점까지 정보만 반영” → 미래 정보 없이 처리 가능 → 실시간 대화에 딱 맞음
- 잔여 연결(Residual)
- 각 블록 입력을 다음 블록으로 직접 더해줌 → 정보 손실 최소화/학습 쉬움
- Dilated Convolution
- 두 칸씩 건너뛰며 컨볼루션 → 더 넓은 시간 길이도 “한 번에” 관찰 가능 → 장기 맥락 학습에 유리
ex) 한 칸씩 건너뛴 Conv
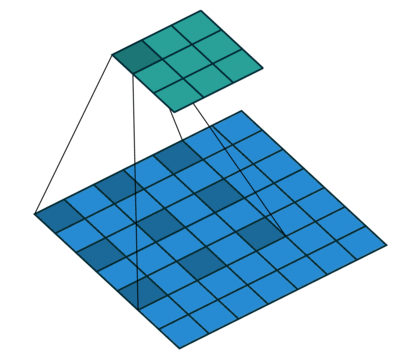
- 두 칸씩 건너뛰며 컨볼루션 → 더 넓은 시간 길이도 “한 번에” 관찰 가능 → 장기 맥락 학습에 유리
- ELU 활성화
- 음성 신호의 특성에 알맞는 활성함수
- 오디오(음성) 신호의 “음수~양수 전체 진동”을 자연스럽게, 정보 손실 없이 잘 처리하기 위한 선택
- 음성 신호의 특성에 알맞는 활성함수
- Weight Normalization
- 각 층의 가중치가 “너무 커지거나 작아지지 않게” 컨트롤 → 훈련 안정, 수렴 빨라짐
- 인과적 Convolution
- 역할
- Transformer 후처리
- SeaNet 인코더는 각 단어를 개별적으로 이해하는 단계였다면,
- Transformer 후처리를 통해 문장 전체를 보며 각 단어의 진짜 의미를 파악하는 단계
- 후처리 목적
- SeaNet 인코더는 각 80ms 구간을 개별 처리함 → 실제 음성은 앞뒤 맥락이 중요
- Transformer를 통해 여러 시점을 함께 보여주며 맥락을 보강해줌
- 후처리 과정
- 입력: 각 80ms 구간들의 512차원 벡터들
- Transformer에 입력
- 각 시점 별, 주변 250프레임(20초분량)을 참고하여 해당 시점에서 진짜 중요한 정보가 무엇인지 다시 계산
- 이를 통해, “지금 이 소리”와 관련깊은 앞뒤 구간에 더 집중
- 출력: 맥락이 보강된 512차원 벡터
- Transformer 후처리에 이은 추가 조치: 256차원으로 투영
- 다음 양자화 단계에서 처리하기에는 계산 효율성 측면에서 부담
- 어떻게? → 단순 Linear Transform(256x512)
- Split RVQ 양자화
- 기본 아이디어: “의미”와 “소리” 분리
- 실제 음성에는 2가지 정보가 담겨있음
- 의미 정보 → “뭐라고 말했는지”
- ex) “안녕” → 단어의 의미
- 음향 정보 → “어떻게 소리났는지”
- ex) 목소리 톤, 발음 방식 등
- 의미 정보 → “뭐라고 말했는지”
- 이 두가지 정보를 분리하고자 함이 Split RVQ의 핵심
- 실제 음성에는 2가지 정보가 담겨있음
- Split RVQ 구조
- 입력: 256차원의 벡터
- 입력받은 256차원 벡터는 다음과 같이 분리됨
- 의미 VQ 1개 토큰
- 음향 RVQ 7개 토큰
- 의미 VQ(1개 토큰)
- “뭐라고 했는지” 토큰화하는 과정
- 말의 내용 자체를 숫자로 표현
- WavLM 지식 증류 활용
- WavLM: 이미 잘 훈련된 “음성 이해” 모델
- WavLM이 “이 음성의 의미는 이거야”라고 알려주는 정보를 활용
- 256차원 벡터가 WavLM의 판단과 비슷해지도록 학습
- 양자화 과정
- 256차원 벡터 → 2048개 후보 중 가장 비슷한 것 선택 → 1개 토큰
- 2048개의 “의미 코드북”이 있고
- 현재 벡터와 가장 비슷한 코드를 찾아서 그 번호(토큰)를 출력
- 256차원 벡터 → 2048개 후보 중 가장 비슷한 것 선택 → 1개 토큰
- 음향 RVQ(7개 토큰)
- “어떻게 소리났는지” 토큰화하는 과정(누가, 어떤 감정으로, 어떤 톤으로 말했는지 등)
- 7단계 Residual Quantization 과정
- 입력: 256차원
- 1차 양자화 → 토큰1 (큰 특징) → 오차 계산
- 2차 양자화 → 토큰2 (1차에서 놓친 부분) → 오차 계산
- 3차 양자화 → 토큰3 (2차에서 놓친 부분) → 오차 계산
- 4, 5, …
- 7차 양자화 → 토큰7 (최종 세부사항)
- 7단계 Residual Quantization 예시 → 각 단계마다 이전 단계에서 표현 못한 세부사항을 추가로 잡아냄
- 1차: “남성 목소리네”
- 2차: “좀 낮은 톤이네”
- 3차: “약간 쉰 목소리네”
- 4차: “끝이 올라가네”
- …
- 7차: “아주 미세한 떨림이 있네”
- 최종 출력
- 8개의 사용자 오디오 토큰
- 1개의 의미 토큰
- 7개의 음향 토큰
- ex) 원래 음성 “안녕하세요” (80ms, 24kHz) → 8개 정수 토큰으로 압축 (1045, 234, 567, 891, 445, 778, 334, 556)
- 토큰의 의미
- 첫 번째 토큰(1045): “안녕하세요”라는 의미
- 나머지 7개 토큰: 이 “안녕하세요”가 어떤 소리로 발화되었는지
- 토큰의 의미
- 8개의 사용자 오디오 토큰
- 기본 아이디어: “의미”와 “소리” 분리
Mimi Encoder의 정보 저장 이후 전달하는 과정
- Mimi Encoder의 출력 결과: 8개 오디오 토큰 출력
- 1개 의미토큰
- 7개 음향토큰
- Multi-Stream에 기록
- 8개의 오디오 토큰은 Mimi Encoder에서 출력되는 즉시 Multi-Stream의 User’s audio input에 저장
- Multi-Stream 구성
- User’s audio input($U$)
- Moshi’s audio output($A$)
- Inner Monologue (텍스트, $W$)
- Helium의 맥락정보로 입력
- Multi-Stream에 저장되는 동시에, Helium의 입력으로도 사용
- Multi-Stream에 그동안 쌓여온 세 개의 스트림(User’s audio input, Moshi’s audio output, Inner Monologue) 토큰들을 모두 받아 입력으로 넣어줌
- 입력 벡터 준비 과정
1) 임베딩(Embedding)
- 각 토큰($U, A, W$)을 고정 크기 벡터로 변환
- ex) $U_i$ → 512차원, $A_i$ → 512차원, $W$ → 512차원 (모두 같은 차원)
2) 포지션 인코딩(Position Encoding)
- 시간 순서를 Helium이 인식하도록, 각 토큰 벡터에 위치 정보 더해줌
3) 스트림 구분 토큰(Stream ID Embedding)
- User/Audios/Inner Monologue 각각을 구분하기 위해, 어떤 Stream인지 구분해주는 작은 벡터 더해줌
RQ-Transformer
개요
- Moshi에서 실제 “대화”의 두뇌 역할을 담당하는 핵심 파트
- RQ란? → “Residual-Quantized”의 약자
전체 구조(크게 두 부분)
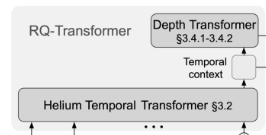
- Helium Temporal Transformer(H. lium)
- 긴 시간 흐름 속에서 “지금까지 대화 맥락(문맥)이 어떻게 이어졌나?”를 파악하는 대규모 뇌
- 마치, 대화 전체 수십 초의 흐름, 주제를 지키는 “인간의 뇌, 장기기억”의 역할
- 역할 → 지금까지의 모든 대화·음성·내적 텍스트 흐름을 ==하나의 큰 맥락 벡터==($z_s$)로 요약
- Depth Transformer
- 이 맥락정보(zₛ)를 받아, “실제로 무슨 말을, 어떤 소리로, 어떻게 만들지?” 를 한 시점(80ms) 단위로 생성하는 손과 입
- 마치, 그 순간순간 적절히 표현해주는 입/목소리/혀
- 역할 → Helium에서 맥락벡터를 받아, 한 시점(80ms)마다 어떤 텍스트(Inner Monologue)를 내고 어떤 의미-음향 토큰을 낼 지 결정
Helium Text Language Model in Moshi(Temporal Transformer)
- 개요
- 논문에서 별도로 훈련된 대규모 텍스트 언어 모델(7B 파라미터)
- Moshi 시스템에 맞게 몇 가지 핵심 구조를 반영한 셋업
- Moshi에 최적화된 Helium 아키텍처의 특성
- RMS 정규화
- 기존 LayerNorm을 대체하는 더 안정적인 정규화
- RoPE(회전 위치 임베딩)
- Transformer가 긴 시퀀스에서 위치 정보를 더 잘 보존하도록 하는 임베딩
- FlashAttention 사용
- Attention 계산에 있어서, 메모리 및 속도 측면에서 개선
- 활성함수: GLU(Gated Linear Units) + SiLU
- FeedForward 블록에서 더 풍부하고 부드러운 Non-Linearity 제공
- 32,000개 토큰 SentencePiece 토크나이저 (주로 영어 대상)
- RMS 정규화
- Moshi에서의 Helium 활용도
- Moshi에는 Helium 모델을 별도 사전학습 시켜 적용
- 연속 시계열 정보를 시간축으로 처리하는 시간 맥락 처리기(Temporal Transformer)로서 RQ-Transformer의 구성요소로 활용
- 기존 Helium 모델에, 구조적/알고리즘 디테일만 Moshi의 목적에 맞춰줌
RQ-Transformer모델 아키텍처
- Helium Temporal Transformer
- Moshi의 텍스트 언어 모델의 심장부와 같은 역할
- 개요
- Moshi의 언어적 추론 능력을 제공하는 텍스트 LLM
- 7B 파라미터 Transformer 모델
- GPT와 유사, Moshi의 특수 요구사항에 맞춰 설계된 모델
- 핵심 역할
- 전체 대화 맥락을 이해
- 각 스텝에서 ‘다음에 AI는 어떤 역할을 해야 하나?’ 결정
- 실행 과정 1) 앞서 준비한 Multi-Stream 입력벡터 받음 2) Self-Attention - 입력된 벡터들이 서로 “서로 어떤 관계?”인지 계산 - 예: “지금 토큰이 ‘날씨’라면, 50ms 전 토큰 ‘내일’과 얼마나 관련 있나?” 3) Feed-Forward - 어텐션 결과를 비선형으로 변환해 더 풍부한 표현 만들기 4) LayerNorm + Residual - 원래 입력과 출력을 섞어(잔여 연결) - 각 층이 안정적으로 학습할 수 있게 정규화 5) 이 과정을 N번(예: 32번) 반복 - “더 깊게” 대화 맥락을 이해 6) 출력 - 모든 입력 토큰 흐름을 ==하나의 맥락 벡터(context vector, zₛ)==로 요약 → 지금까지의 대화 의도 및 상황을 압축한 정보 덩어리
- Depth Transformer
- 개요
- “Helium이 파악한 전체 맥락($z_s$)를 바탕으로, ==AI가 실제로 생각(텍스트)하고 말(음성)하는 토큰==을 순서대로 뽑아냄
- 순차적으로 생성하는 이유 → 텍스트를 먼저 정해야, 어떤 소리를 낼지(음성 토큰)를 정확히 결정할 수 있기 때문
- 기본 원리 → “AutoRegressive Generation”
- 한 번에 하나씩, 이전까지 만든 것들을 참고해서 다음 토큰을 예측하는 방식
- 마치 사람이 말할 때 “앞에서 한 말을 기억하면서 다음 단어를 정하는” 것과 같음
- 실행 과정 1) Inner Monologue 텍스트($W$) 예측 - 입력: Helium에서 나온 맥락 벡터($z_s$) + 이전 스텝까지 기록된 Multi-Stream(Context) - 작동 - “지금 이 상황에서 Moshi가 어떤 내용을 말해야 자연스러울까?” 고민 - ex) “내일 날씨가 맑을 거예요”라는 텍스트를 결정 - 처리 과정 → Vanilla Transformer 인코더 통과(보통 6개 블럭) - Self-Attention - 맥락 벡터 $z_s$에서 ==텍스트 생성에 가장 중요한== 부분을 찾아냄 - ex) $z_s$에 “사용자가 날씨를 물어봤다”, “지금은 오후다”, “친근한 톤이었다” 등이 섞여 있으면 → “날씨 질문에 답해야 한다”가 가장 중요하다고 판단 - Feed-Forward - Self-Attention 결과를 받아서, ==구체적으로 무슨 단어들로 답할까?==를 계산 - LayerNorm/Residual - 값이 튀거나 무너지지 않게 안정화 - 출력: 텍스트 토큰 $W^$ (실제 단어들을 숫자 ID로 바꾼 것) 2) 의미 오디오 토큰($A_1$) 예측 - 입력: $z_s + W^$ - 맥락($z_s$) + 지금 생각한 텍스트($W^$) - 작동 - “지금 말할 텍스트의 의미를 음성으로 어떻게 시작할지” 결정 - ex) “내”라는 글자를 음성으로 어떻게 낼지 숫자로 표현 - 처리 과정 - 맥락 벡터 $z_s$와 $W^$를 Concat / Add - Inner Monologue처럼 또 다시 Depth Transformer 블록 여러 개 통과 - 마지막에 가장 그럴듯한 의미 토큰(실질적으로는 숫자 하나) 예측 - 출력: 의미 토큰 $A_1^$ (의미를 담은 음성 조각, 첫 번째 오디오 토큰) 3) 나머지 음향 토큰($A_2 \ldots A_8$) 순차 예측 - 입력: $z_s + W^ + A_1^* + \ldots + A_i^$ (앞서 예측한 것들 모두) - 작동 - “다음 조각은 어떻게 낼까?”를 하나씩 반복 - ex) “일”, “날”, “씨”…. 80ms 전체 발화를 8조각으로 나눠서 하나씩 만들어냄 - 처리 과정 - 앞선 방식과 동일하게, Depth Transformer 블록 여러 개 통과 - 한 개씩 순차적으로 각각 예측 - 매 Block마다, 방금까지 만든 모든 토큰(특히 직전 음향토큰까지 포함)을 Depth Transformer에 집어넣고, 그 다음 음향토큰을 하나씩 예측해서 이걸 또 입력에 추가해서 다음 토큰을 만듦 - 출력: $A_2^ + \ldots + A_8^$ (총 7개) 4) 결과 - 1개의 텍스트 토큰: $W^$ - 8개의 오디오 토큰: $A_1^{\ast} , \ldots , A_8^{\ast}$ - 이들이 모여 80ms 동안 Moshi의 응답 음성을 구성
- 개요
- Multi-Stream 기록 및 다음 사이클 준비
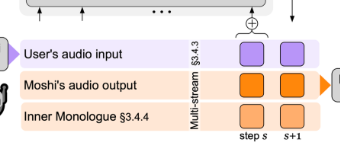
- 위에서 기록된 토큰들은 ==다음 스텝의 Helium이 이어서 대화==를 해나가는 필수 정보
- 기록 과정
- Inner Monologue 행에 $W^*$ 추가
- Moshi’s audio output에 $A_1^{\ast} , \ldots , A_8^{\ast}$ 추가 → 실제 음성 조각을 나타내는 토큰들
- 저장 방식: concat
- 각 스텝의 토큰 정보를 정확히 시간 순으로 남겨서, 다음 Helium이 ==이전 대화 흐름 전체를 그대로 올바르게 참고==할 수 있도록 해주기 위함
- 다음 사이클(80ms 단위) 반복
- 이렇게 Multi-Stream에 업데이트되어 기록된 $W, A$는 80ms 단위로 끊김 없이 Helium에 입력되어 실시간 대화 이루어짐
- 과정
- 사용자 음성이 → Mimi 인코더 → 새로운 $U_1’ \ldots U_8’$ 로 기록
- 다시 Helium Temporal Transformer가 전체 행 내용을 보고
- Depth Transformer가 → $W^{\ast}$ (새로운 W), $A_1^{\ast} , \ldots , A_8^{\ast}$ (새로운 A) 토큰을 생성
Mimi Decoder
RQ-Transformer에서 생성된 AI 오디오 토큰들($A_1^{\ast} , \ldots , A_8^{\ast}$)이 Mimi 디코더를 통해 실제 24kHz 음성 파형으로 변환되어 사용자가 들을 수 있도록 전달
앞서 사용자 음성을 입력받는 Mimi Encoder의 역과정 → AI가 이해한 바를 다시 사람에게 전달하기 위함
아키텍처 구조 개요
- 토큰을 벡터로 복원
- 현재 상태 → RQ-Transformer가 만든 8개 정수 토큰
- 이것들은 아직 숫자 ID일 뿐, 음성으로 바로 변환 불가
- Transformer 전처리
- 토큰에서 복원한 벡터들이 개별적으로 “뚝뚝 끊어져” 보일 수 있음
- 실제 음성은 부드럽게 연결되어야 자연스러움
- SeaNet 디코더
- 본격적 음성 생성 단계
- 음성 압축 단계(Mimi Encoder) 역과정
- 최종 음성 복원/출력 (24kHz)
아키텍처 과정 상세
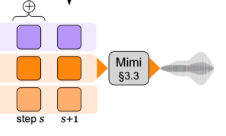
- 토큰을 벡터로 복원
- 현재 상태: 8개의 정수
- 디코딩 목표: 이 정수들을 다시 음성을 만들 수 있는 벡터로 바꿔줘야 함
- 복원 과정
- 의미 토큰 1개 복원
- 토큰 1045 → (의미 코드북에서 1045번 찾기) → 256차원의 의미 벡터 생성
- 훈련 때 만든 2048개 의미 코드북에서 1045번째를 찾아옴
- 해당 벡터는 “안녕하세요”라는 의미 정보를 담고 있음
- 토큰 1045 → (의미 코드북에서 1045번 찾기) → 256차원의 의미 벡터 생성
- 음향 토큰 7개 복원
- 토큰 (234, 567, 891, 445, 778, 334, 556) → 각각을 음향 코드북에서 찾아서 벡터로 변환 → 7개 벡터를 차례로 더해서 → 종합 음향 벡터 생성
- 최종 복원된 256차원 벡터: 의미 벡터 + 종합 음향 벡터
- 의미 토큰 1개 복원
- Transformer 전처리
- 앞서 복원된 벡터는 80ms 구간별로 따로따로 만들어짐 → 실제 음성은 부드럽게 연결되어야 자연스러움
- 복원된 각 벡터들을 부드럽게 연결시켜주기 위함
- 복원 과정
- 여러 시점(80ms씩 분리되어 있는)의 256차원 벡터들 → (Transformer: 8레이어, 8헤드) → 시간적으로 매끄럽게 연결된 벡터들
- 세부 사항
- 어텐션으로 앞뒤 맥락 참고 → “이 시점 앞뒤로 어떤 소리가 나고 있지?”
- 자연스러운 연결 만들기 → “갑자기 끊기지 않고 부드럽게 이어지도록”
- 일관성 보장 → “같은 사람 목소리로 계속 들리도록”
- SeaNet 디코더→ 음성 복원 (24kHz)
- 목표
- 256차원 벡터(12.5Hz) → 24kHz 실제 음성 파형으로 변환
- SeaNet 인코더의 정반대(확장 과정)
- 과정 → SeaNet 인코더의 역과정

- 1D Conv (첫 번째)
- 256차원 → 512차원으로 정보량 늘리기
- 12.5Hz → 25Hz로 시간 해상도 2배 증가
- Block 1~4: 점진적 확장
- Block 1: “대략적인 파형 모양 만들기”
- Block 2: “중간 주파수 성분 추가”
- Block 3: “고주파 디테일 넣기”
- Block 4: “최종 24kHz 파형 완성”
- 1D Conv (첫 번째)
- 기술적 특징들 → Encoder와 동일, 역과정
- 전치 컨볼루션 (Transposed Convolution)
- 일반 컨볼루션의 반대: “확장” 역할
- stride=4 → “4배로 늘리기”
- 잔여 연결 (Residual Connections)
- 각 블록에서 입력을 출력에 더해줌
- 정보 손실 방지: “중요한 정보가 사라지지 않도록”
- ELU 활성화
- 음성의 음수/양수 진동을 자연스럽게 처리
- 전치 컨볼루션 (Transposed Convolution)
- 최종 음성 파형 출력
- 결과
- 24kHz 음성 파형 (1920개 샘플, 80ms 분량)
- 음질 검증
- 원본과 거의 구분 불가: 1.1kbps로 압축했지만 고품질 유지
- 실시간 처리: 80ms마다 실시간으로 복원 가능
- 자연스러운 연결: 각 구간이 매끄럽게 이어짐
- 결과
- 목표
chat_bubble 댓글남기기
댓글남기기