SALMONN: Speech Audio Language Music Open Neural Network
노타의 “오디오 언어모델의 경량화 레서피 작성” 해커톤 수행에 앞서, 베이스라인 모델로 주어진 SALMONN 모델에 대해 리뷰하였다.
최근 트렌드인 Visual-Language Model과 함께 SALMONN과 같은 Audio-Language Model이 발표되는 것을 보면, 확실히 ChatGPT 이후 LLM이 대세인듯 하다.
0 ABSTRACT
General audio information: 적어도 세 가지 타입의 사운드를 포함(speech, audio events, music)
SALMONN: “Speech 인코더 + Audio 인코더” → Multi-modal로 결합된 pretrained model ⇒ training에 사용되는 왠만한 speech 및 audio task에 우수한 성능을 보임
1 INTRODUCTION
최근 LLM이 인간에 준하는 성능을 보이는 가운데, Instruction Tuning이라는 패러다임이 등장
- LLM이 제약없이 사용자의 Instruction을 수행할 수 있도록
- 이를 활용하여 multi-modal perception을 활용한 LLM에 관한 연구가 급성장 중
- 최근 연구는 LLM에 한가지 추가 인코더를 연결(image, silent video, audio events etc)하는 형식에 대한 연구에 집중.
SALMONN → “A Single audio-text multimodal LLM”
- 3가지 종류의 사운드를 인식 (speech, audio events, music)
- Speech 데이터와 Non-speech 데이터 모두에 대해 증강시키기 위해 Dual Encoder 활용
- from Whisper (speech model)
- from BEATs (audio encoder)
- A window-level query Transformer(Q-former)
- 인코더가 출력한 sequence를 Vicuna LLM에 넣을 다수의 augmented audio tokens로 바꿔줌
- 오디오 입력 데이터를 처리하고, 이를 LLM과 연결 (가변 길이의 오디오 데이터 → 고정 길이의 텍스트 토큰)
- Cross-modal Emergent abilities ⇒ “훈련 중에 보지 못한 크로스모달 작업을 수행할 수 있는 능력”
- Instruction Tuning 단계에서 특정 작업에 과적합(task over-fitting)되는 문제가 발생.
- 이를 해결하기 위해 Activation Tuning 단계를 도입하여 cross-modal emergent abilities를 활성화.
2 RELATED WORK
주로 LLM의 확장성 및 Multi-modal 처리능력에 관한 연구들
- LLM의 음성 처리
- LLM은 본래 텍스트 기반 대화 모델 → 음성 입력을 직접 처리하기 위한 연구가 활발히 진행
- Frame-rate 축소 기법: 길이가 긴 음성 토큰 시퀀스 길이 줄이기 위한 목적
- 고정 속도 축소(Fathullah et al., 2023): 일정한 비율 축소
- 가변 속도 축소(Wu et al., 2023): Speech Recognition 기반 축소
- Q-former 기반 축소 기법(Yu et al., 2023): 고정된 출력 프레임 숫자를 유지
- Speech 합성: LLM의 output space에 음성 토큰을 추가하는 방법
- SpeechGPT, AudioPaLM 등
- Audio input 입력 처리
- 고정된 크기의 스펙트로그램 이미지로 변환 처리
- Produced by. Visual-language LLM(시간 정보 모델링 제외)
- Whisper의 Speech encoder는 오디오 이벤트까지 묘사하기에는 어려움이 있음
- Narisetty et al. (2022): Speech Recognition 및 Speech Captioning을 동일한 모델로 분리하여 처리하는 방법 제시
- 고정된 크기의 스펙트로그램 이미지로 변환 처리
- Music 입력 처리
- Liu et al. (2023): LLM과 함께 MERT의 Music 관련 인코더를 활용하여 음악 이해 처리 작업 수행
- AudioGPT: text-based LLM이 음성, 오디오 이벤트, 음악을 처리하고 다른 모델과 상호작용하도록 설계
- Multi-modal LLM (SALMONN 해당)
- Visual modal에서 더 다양하게 활용(Image, video, audio-visual 등)
- 이 때, Modal 간 정렬은 주로 FCN이나 어텐션 기반 모듈에서 이루어짐
- Q-former: visual modal을 위한 모델에 흔히 적용되어 있음
3 METHODOLOGY
3.1 Model Architecture
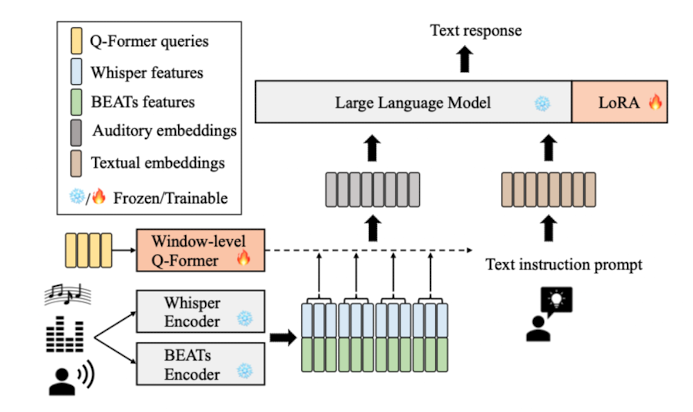
Dual Auditory Encoders
- For Speech data: Whisper Encoder
- For Non-speech data: BEATs Encoder - high level non-speech semantics information using iterative self-supervised learning
Window-level Q-former
- Whisper encoder와 BEATs encoder의 결과물 Z
- 윈도우 L의 크기로 쪼개
- 학습 가능한 쿼리 벡터 Q를 주입
- 두 단계의 Attention을 거쳐(Self-Attention, Cross-Attention)
- 각 윈도우 별 N개의 텍스트 토큰 H_l 생성
- 최종적으로, 모든 윈도우에서 생성된 최종 텍스트 토큰 결합: Vicuna에 주입
LLM and LoRA
- LLM 파라미터 파인튜닝에 가장 널리 사용되는 LoRA ⇒ SALMONN의 Vicuna에 역시 적용
3.2 Training Method
- 세 가지 주요 단계로 구성(Pre-training Stage, Instruction Tuning Stage, Activation Tuning Stage)
- 각 단계는 모델 성능 개선, 그 중에서도 Multi-modal 작업의 Cross-modal 추론 능력 강화에 초점
- Pre-training Stage
- Pre-trained 파라미터(LLM, 여러 인코더)와 무작위로 초기화된 파라미터(연결된 모듈과 어댑터) 간 격차를 줄이기 위한 단계
- 데이터: "대량의 음성 인식 + 오디오 캡션 데이터"를 활용
- 음성 / 비음성 오디오에 대한 주요 청각 정보를 포함하여 복잡한 추론 없이 데이터를 고품질로 정렬하여 학습에 도움을 줌
- Window-level Q-former 및 LoRA로 pre-train
- 데이터: "대량의 음성 인식 + 오디오 캡션 데이터"를 활용
- Pre-trained 파라미터(LLM, 여러 인코더)와 무작위로 초기화된 파라미터(연결된 모듈과 어댑터) 간 격차를 줄이기 위한 단계
- Instruction Tuning Stage
- Visual-language 및 NLP에서 사용되는 Instruction Tuning 방법과 유사
- Instruction 내용을 기반으로, Cross modal 추론 능력 강화에 초점을 맞춘 단계
- Task: 중요도 및 상황에 따른 긴요성에 따라 적절히 선택
- Prompt: 오디오 데이터에 함께 제공된 텍스트를 기반으로 생성
- 문제점: Task Over-fitting
- 특정 task(ex: 음성 인식, 오디오 캡셔닝 등)에 편향된 결과를 생성하는 현상
- 원인
- 단순한 prompt 구성: Complexity 및 Diversity 부족 ⇒ Cross-modal 작업시 과적합 발생
- 특정 task가 결정적인 Output 출력: Speech Recognition / Audio Captioning 등
- 훈련 데이터에 강하게 편향된 결과가 생성됨
- In math
- Activation Tuning Stage
- Task Over-fitting 문제 완화, 더 긴 응답 및 다양한 결과를 생성하도록 모델 tuning
- 보다 길고 다양한 텍스트 출력을 요구하는 task(storytelling 등)로 fine-tuning
- Prompt-based LLM을 활용하여 수동으로 데이터를 생성하여 training data 확장
- LoRA의 scaling factor를 줄여 zero-shot instruction만으로 길고 다양한 응답을 생성
- Task Over-fitting 문제 완화, 더 긴 응답 및 다양한 결과를 생성하도록 모델 tuning
4 EXPERIMENT SETUP
4.1 Model Specification
-
Whisper-Large-v2 ⇒ speech encoder
-
The fine-tuned BEATs encoder ⇒ Audio encoder
-
Vicuna with 13 billions
- Q-former, LoRA etc.
4.2 DATA Specification
DATA: Audio Benchmark Dataset (Audiocaps, Gigaspeech, WavCaps, Librispeech, Clotho)
-
AudioCaps / Clotho: 비음성 데이터를 대상으로 한 AAC task에 활용
-
GigaSpeech / LibriSpeech: ASR 및 관련 작업에 활용
-
WavCaps: Multi-modal 및 라벨링 기반 Training에 적합
Train stages
- First Stage: Pre-training stage
- Speech Recognition
- 960-hr Librispeech
- 1000-hr Gigaspeech M-set
- Audio Captioning
- 2880-hr Wavcaps (180초 이상의 음원 제거)
- Audiocaps
- Clotho
- Speech Recognition
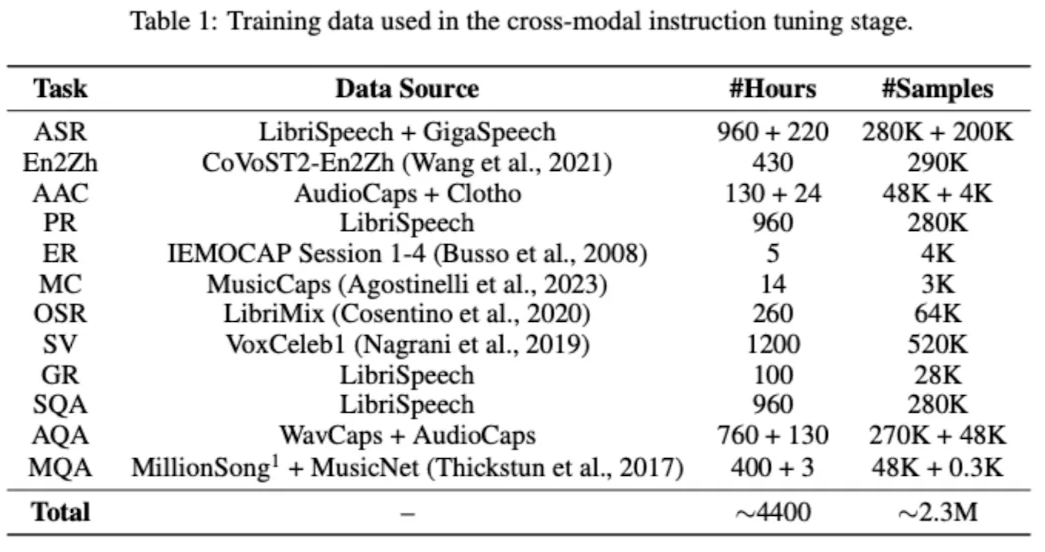
- Second Stage: Instruction Tuning stage
- Multiple tasks (ASR, En2Zh, AAC, PR, ER, MC, OSR, SV, GR, SQA, AQA, MQA)
(관련 포스트 참조)
- multiple tasks를 통해 다양한 multi-modal 능력 학습
- 목적: 모델이 특정 도메인을 이해 및 처리하는 능력 강화
- Multiple tasks (ASR, En2Zh, AAC, PR, ER, MC, OSR, SV, GR, SQA, AQA, MQA)
(관련 포스트 참조)
- Final Stage: Activation Tuning stage
- SALMONN(+reduce LoRA): 오디오 클립들을 기반으로 12개의 스토리 작성
- 12개의 각 스토리 샘플을 활용하여, 12단계에 걸쳐 teacher-forcing 방법으로 cross-entropy loss를 측정하여 훈련 (For. lightweight fine-tuning process)
4.3 Task Specification
Task Level 1
- 특징: 가장 쉬운 작업으로, Instruction Tuning 단계에서 사용된 작업들로 구성
- 작업 예시
- 음성 인식(ASR)
- 오디오 캡셔닝(AAC)
- 음악 캡셔닝(MC)
- 모델이 이미 학습한 작업들로 구성되어 있어 수행하기 가장 쉬움
Task Level 2
- 특징: 난이도 높음, 학습되지 않은 작업(Untrained Tasks)으로 구성
- 작업 예시
- Speech Keyword Extraction (KE): 음성 내용에서 키워드를 정확히 추출.
- Spoken Query-Based Question Answering (SQQA): 음성 질문에 기반한 상식 지식 응답.
- Speech Slot Filling (SF): 음성에서 특정 슬롯 값(예: 이름, 날짜 등)을 추출.
- 번역 작업(AST): 영어→독일어(En2De), 영어→일본어(En2Ja).
- 새로운 작업 포함 / 모델의 제로샷 학습 능력 평가
Task Level 3
- 특징: 가장 어려운 작업으로, 새로운 복합적 작업을 포함.
- 작업 예시
- Audio-Based Storytelling (Story): 오디오 정보를 바탕으로 스토리를 생성.
- Speech Audio Captioning (SAC): 오디오 데이터를 기반으로 설명을 생성.
- SALMONN이 오디오, 음악, 텍스트 정보를 통합적으로 이해하고 추론하는 능력을 요구하는 단계
평가 지표
- 다양한 평가 지표를 사용하여 성능 측정
- WER(Word Error Rate), BLEU4, METEOR 등
- 복잡한 작업(Level 2 및 Level 3)에 대해서는 "Following Rate (FR)" 지표 사용
- 모델이 얼마나 명령을 잘 따르는지 평가
chat_bubble 댓글남기기
댓글남기기