0. Whisper 모델 개요
- 2022년 OpenAI에서 공개한 ASR(자동 음성 인식) 모델
- 68만 시간의 대규모 다국어 음성 데이터로 학습 → 기존 ASR 모델들의 한계 극복
- Paper name: “Robust Speech Recognition via Large-Scale Weak Supervision”
- Weakly Supervised Learning을 통해 강건한 음성 인식 성능 향상 방법 제시
- Weakly Supervised Learning을 통해 강건한 음성 인식 성능 향상 방법 제시
1. Whisper 등장 배경
기존 ASR 모델들의 한계
음성 인식 분야는 Wav2Vec2.0(Baevski et al., 2020)에서 제시한 unsupervised pre-training techniques의 발전이 가속화되면서 활성화
전통적인 음성 인식 모델에서 다음과 같은 문제점을 발견
- 기존 모델들(Wav2Vec 2.0 등) → 사전 학습된 인코더는 우수하지만, 실제 사용을 위해서는 반드시 ==데이터셋별 Fine-tuning이 필요==함
- 특정 데이터셋(도메인 특화)에 맞춰진 모델 → 다른 환경에서 성능이 크게 떨어지는 문제
- 대부분의 모델들은 영어 중심 혹은 소수 언어만 지원
기존 ASR 모델의 한계 보완을 위한 핵심 아이디어
이를 보완하기 위해, Whisper는 다음과 같은 접근 방법을 내세움
- 대규모의 Weakly supervised learning
- Weakly supervised learning → “실제 세상과 유사한 환경에서 얻을 수 있는 데이터”로 훈련
- 완벽하게 정제된 데이터 대신, Real World에서 얻을 수 있는(때로는 오류도 섞인) 대량의 데이터 활용
- 훈련 환경을 실제 환경과 유사하게 맞추고자 한 시도
- 웹에서 수집한 ==68만 시간의 음성-텍스트 쌍의 데이터==를 사용하여 학습
- 다양한 언어(영어 포함 99개), 방언, 노이즈, 상황 등이 폭넓게 포함
- 불완전 정보도 적극 활용(ML 번역 스크립트 제거, 언어 일치성 검증, 중복 제거 등)
- Weakly supervised learning → “실제 세상과 유사한 환경에서 얻을 수 있는 데이터”로 훈련
- Zero-shot Learning
- 기존 ASR 모델은 새로운 애플리케이션 / 데이터셋에 적용할 때 반드시 Fine-Tuning이 필요했음
- Zero-Shot Model → 별도의 Fine-Tuning 없이도 다양한 데이터셋에서 우수한 성능
- Whisper의 Zero-Shot 성능
- Whisper는 방대한 다양의 다국어, 도메인, 음성 환경 데이터로 사전 학습 → 학습 과정에 한 번도 등장하지 않은 언어나 데이터셋에 높은 정확도를 보임
- ex) 특정 도메인(의료, 법률, 방송 등)의 음성 데이터를 별도 조정 없이 곧바로 인식 가능
- 데이터가 부족한 곳(저차원 언어, 방언 등)에서도 합리적인 결과
- Zero-shot을 Whisper에 적용함으로서 기대할 수 있는 효과
- 실제 서비스/응용에서 빠른 배포 및 확장성 제공
- 데이터 수집이 어려운 경우에도 실용적 활용 가능
- Task specifier(특수 토큰)를 활용한 Multi-task Learning
- Whisper는 ASR뿐 아니라, 다양한 음성 작업(음성 인식, 번역, 언어 식별 등)을 동시에 수행 가능하도록 ==Task specifier(특수 토큰) 기반 multi-task learning== 적용
- 동작 과정
- 입력 및 출력에 ‘Task specifier’를 사용 → Task를 지정하는 명령어를 지정
- 동일한 모델 아키텍처 및 파라미터 사용 → 사용자가 원하는 여러 작업을 자동으로 전환하며 처리
- Multi-task 예시
- ASR → 음성을 텍스트로 변환
- 음성 번역 → 다른 언어로 바로 번역
- 언어 식별 → 입력 음성의 언어 판별
- 타임스탬프 부여 → ‘텍스트-오디오’ 구간 맞춤
- 이를 통해, ==별도 모델 없이 다양한 음성 관련 문제에 적용==할 수 있도록 함
2. 데이터셋 구성 및 전처리
Whisper 훈련 데이터 구성
논문에서 강조하는 데이터셋 구성의 핵심
- 개요
- 모델의 성능은 새로운 아키텍처에서 나온 것이 아니라 ==엄청난 규모의 데이터== 및 ==우수한 전처리 전략==에서 나옴 → “Weakly Supervised Learning”
- Whisper는 인터넷에서 ==”오디오 - 텍스트 쌍”== 데이터를 수집해 훈련용 데이터셋을 만듦
- Youtube(자막 비디오), Podcast, 강연, 인터뷰 등의 콘텐츠에서 데이터 수집
- Youtube(자막 비디오), Podcast, 강연, 인터뷰 등의 콘텐츠에서 데이터 수집
- 수집한 데이터의 문제점
- 잘못된 자막
- 기계 번역된 자막
- 음성-자막 간 언어 상이
- 발화가 안 들리는 경우
- 해결책
- Whisper 논문에서는, 이를 해결하기 위해 ==”수집 → 필터링 → 세분화”==의 과정
- 기타: 데이터셋 세부 구성
- 규모 → 681,070hr의 음성 데이터
- 언어 분포
- 영어 → 65%(438,218hr)
- 다국어 음성 인식 → 17%(117,113hr)
- 번역 데이터 → 18%(125,739hr)
Whisper 데이터 전처리 과정
- Audio-Text 쌍의 데이터 수집(681,070hr 분량의 전체 데이터)
- 웹에서 수십~수백만 시간의 ==”오디오 자막” 영상 데이터== 수집함
- ex) YouTube 동영상, 대학교 강의, TED 영상, 다국어 팟캐스트 등
- 자막은 이미 포함되어 있거나 따로 스크래핑하여 수집
- 웹에서 수십~수백만 시간의 ==”오디오 자막” 영상 데이터== 수집함
- 기계 생성(Machine-generated) 번역 / 자막 데이터 필터링
- 자막같은 경우, 사람이 작성한 것이 아닌 ==자동 자막(기계 번역 또는 ASR 시스템으로 생성)==일 때가 많음
- Whisper에서는, 이런 불확실하고 낮은 품질의 script는 걸러내는 ==자동 필터링==을 수행
- ex) 모델이 소위 “엉터리 자막”에 overfitting되는 것을 방지하기 위해, 아래와 같은 자동 필터링 과정을 수행함
- 자막에 등장한 단어들이 Google Speech API의 산출과 너무 유사하면 → 제거
- 문장 길이 비정상적으로 짧거나 긴 경우 → 제거
- 텍스트 간 중복 제거(퍼지 해시(Fuzzy Hashing)기법 사용)
- 스크립트가 오디오에 비해 비정상적으로 너무 빠르거나 느린 경우 → 제거
- 언어 감지기로 오디오와 텍스트의 언어가 일치하지 않는 경우 → 제거
- Audio 데이터 분할
- ASR 모델은 긴 오디오 파일을 한 번에 읽지 못함 → “최대 30초 길이의 세그먼트”로 잘라서 처리
- 오디오가 길면 단락별로 쪼갬 (타임스탬프 기준)
- One script in One segment → 하나의 세그먼트(오디오 파일 자른 것)에는 오직 하나의 스크립트(오디오에 매칭되는 텍스트)에만 대응됨
- Whisper는 각 세그먼트에 대해 “이 안에 담긴 말을 번역 or 전사하라”는 식으로 훈련됨
- Whisper는 기본적으로 30초짜리 음성 세그먼트를 주입받음 → 그에 대한 적절한 텍스트 시퀀스 생성
- ASR 모델은 긴 오디오 파일을 한 번에 읽지 못함 → “최대 30초 길이의 세그먼트”로 잘라서 처리
- No-Speech detection(음성 유무 감지) 학습용 샘플 생성
- No-Speech detection: 음성이 있냐 없냐를 예측하는 능력
- 이를 예측하기 위한 ==No-Speech detection 전용 학습 샘플도 포함==됨
- 무음 구간이 있을 경우,
<|nospeech|>토큰을 출력하도록 학습 - 실제 환경과 유사: “지금 말하고 있는 사람 있나요?”같은 것을 판별하기 위함
- Language identification(자동 언어 감지) 기능 수행을 위한 훈련용 샘플 생성
- 훈련 데이터에는 각 오디오의 언어가 수동으로 지정되어 있지 않은 경우도 있음
- Whisper가 Text Embedding만 보고 자동 언어 감지(Language Identification)도 수행할 수 있도록 훈련
- “오디오 시퀀스를 듣고, 그것이 어떤 언어인지를 맞히는 태스크”
- ex) (한국어 오디오 파일) →
<|ko|>토큰을 출력하도록 이후, 디코더가 그 언어에 맞게 전사 혹은 번역을 수행하도록 함
- ex) (한국어 오디오 파일) →
- 훈련 데이터에는 각 오디오의 언어가 수동으로 지정되어 있지 않은 경우도 있음
- 기타 훈련 샘플
- 데이터 구성에 Voice Activity Detection(VAD) 반영
- 오디오 내 화자 중단 및 침묵 여부 반영(멈춤 시점부터 발화 시점까지 계산)
3. Whisper 모델 아키텍처 및 training 과정
개요
Whisper는 특별한 구조를 쓰기보다는, ==검증된 Transformer 기반의 인코더-디코더 구조==를 택하고, 그 위에 거대한 데이터와 멀티태스크 학습을 얹는 메커니즘을 취함
Whisper 모델 아키텍처
크게 ==”Encoder + Decoder + 특수 토큰 기반 Task Control”==로 구성함
Transformer의 Encoder-Decoder 구조를 동일하게 차용함
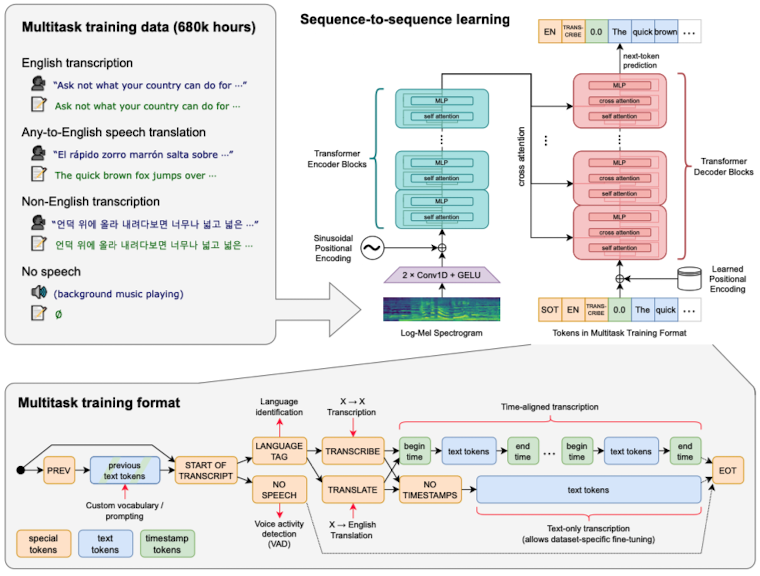
- Audio 입력 처리
- Whisper는 음성을 입력할 때, Log-Mel 스펙트로그램 형태로 입력
- Log-Mel 스펙트로그램 형태의 음성을, 다음 과정을 거쳐서 입력 처리
- 오디오를 16kHz로 샘플링
- ==STFT== 적용
- Mel 필터뱅크(80개 채널)로 필터링
- 로그 스케일로 변환 → 80-channel Log-Mel spectrogram
- STFT(Short-Time Fourier Transform, 단시간 푸리에 변환)
- 시간이 지나면서 성질이 바뀌는 신호(비정상 신호, 음악 / 음성 등)에 대해 언제, 어떤 주파수 성분이 나타나는지 알아내는 방법
- STFT 동작 원리
- 신호를 짧은 구간으로 나눔 → Sliding window
- 각 구간(window)에 Fourier Transform(DFT, FFT 등) 수행
- 결과를 ‘시간-주파수’의 2차원 형태로 표현
- X축: 시간(윈도우가 진행되는 위치)
- Y축: 주파수(각 윈도우에서 계산된 주파수 성분)
- 최종 결과 → 2차원
- 필요 이유
- 일반 푸리에 변환은 “어느 시간에 어떤 주파수가 나왔는지”를 파악할 수 없음
- 시간이 지나면서 내용이 변하는 신호(음성, 음악 등)는 ==”시간 정보와 주파수 정보”를 동시에 파악==해야 → STFT 활용
- 최종 입력값 → (80, 3000) 크기의 2D Matrix(약 30초 길이의 오디오)
-
Encoder
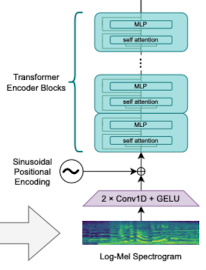
- Audio Data가 Log-Mel Spectrogram으로 입력됨
- 2 * Conv1D + GELU
- 구조
- 2개의 Conv1D → 필터 폭 3
- 두번째 Conv1D → 첫번째 Conv1D에 비해 stride 2배
- Layer 별 역할
- Conv1D
- 오디오 시간 차원을 downsampling
- GELU
- 층마다 적용(Activation Layer)
- Conv1D
- 구조
- Sinusoidal Positional Embedding
- Sequence Data(음성/텍스트 등)처럼 입력 시간이 중요한 데이터들은 Positional Embedding 필요 → 그 중 가장 대표적인 방식이 Sinusoidal Positional Embedding
- Sinusoidal Positional Embedding: 입력 시퀀스의 각 위치 $p$와 차원 $i$에 대해, 아래와 같이 ==사인, 코사인 함수를 주기로 활용==하여 임베딩 값을 만들어주는 방법
- $PE_{(p, 2i)} = sin(p/10000^{2i/d})$
- $PE_{(p, 2i+1)} = cos(p/10000^{2i/d})$
- Sinusoidal Positional Embedding: 입력 시퀀스의 각 위치 $p$와 차원 $i$에 대해, 아래와 같이 ==사인, 코사인 함수를 주기로 활용==하여 임베딩 값을 만들어주는 방법
- “2 * Conv1D + GELU”의 출력에 Sinusoidal Positional Embedding이 더해져 ⇒ N개의 Transformer Encoder 블록에 입력
- Sequence Data(음성/텍스트 등)처럼 입력 시간이 중요한 데이터들은 Positional Embedding 필요 → 그 중 가장 대표적인 방식이 Sinusoidal Positional Embedding
- N개의 Transformer Encoder Blocks
- Multi-Head Self-Attention
- Feed Forward Layer(GELU 활성화 사용)
- 서브 레이어 연결: LayerNorm 및 Residual Connection
- 출력: 오디오의 ==context vector== sequence → 의미 있는 오디오 표현 벡터 생성, Decoder의 Cross-Attention에 사용
- Decoder
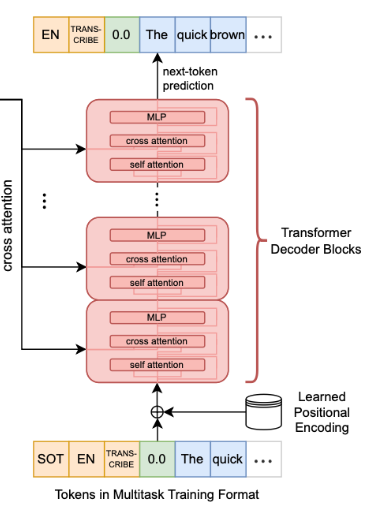
- Encoder가 추출한 Audio의 context vector를 참고하면서,
- 토큰들을 하나씩 한 방향으로 예측 → 텍스트로 바꿈
- 입력
- 텍스트 토큰(Tokens in Multitask Training Format, 예: “[transcribe]”) → 모든 task specifier가 입력에 명시, Whisper 모델에게 ==지금 수행해야 할 Task가 무엇인지== 알려줌 → 이 덕분에, Whisper가 ==하나의 모델로 다중 작업 처리를 자동으로== 할 수 있게 됨
- Audio의 context vector(Encoder 출력값) → Decoder Block의 각 Cross Attention에 입력 1. 텍스트 토큰 입력 Embedding: Learned Positional Encoding 사용
- 텍스트 토큰 고유의 임베딩 벡터 + 각 텍스트 토큰의 위치에 해당하는 임베딩 벡터 → 이 둘을 더한 결과를 Decoder의 입력으로 활용, 두개 모두 학습됨 2. N개의 Transformer Decoder Blocks
- Masked Multi-Head Self-Attention
- 디코더의 각 레이어는 먼저 자기 자신만의 토큰들끼리 Attention을 수행
- 여기서 “Masked”란, 토큰 생성의 순방향성(미래 토큰은 못 봄)을 강제하는 마스킹 처리
- 각 토큰이 지금까지 만들어진(왼쪽) 토큰들 정보만으로 자신을 업데이트함
- 이 과정을 여러 head(다중 방식)로 동시에 진행
- Cross-Attention (Encoder-Decoder Attention)
- Self-Attention으로 가공된 중간 결과에 대해
- 인코더의 Audio Context Vector(오디오 의미 벡터)에 대한 Attention을 수행
- 즉, 현재까지 생성된 텍스트 문맥이 “어떤 오디오 구간에 집중해야 할지”를 동적으로 결정
- Cross-Attention을 통해 디코더는 오디오 정보를 적극적으로 참조
- Feed Forward Network (FFN)
- 각 토큰의 벡터는 위치별(Independent)로 2층 신경망(FFN)을 거쳐 더욱 비선형적 가공이 이루어짐
- 활성화 함수(GELU 등)를 포함
- LayerNorm & Residual (정규화와 잔차 연결)
- 각 단계별로 Layer Normalization 적용
- 각 층의 입력과 출력을 더하는 Residual Connection(잔차 연결) 사용
- 이 구조가 여러 층(블록) 반복되며, 디코더 내의 정보 처리가 깊어짐
- 특수 토큰
- 음성 인식 문제의 핵심 → 해당 오디오 프레임에서 어떤 단어가 발화되었는지 보는 것
- 하지만, 이외에 완전한 기능을 갖춘 음성 인식 시스템에는 기타 많은 추가 Task가 포함됨 (voice activity detection, speaker diarization, inverse text normalization 등)
- 이를 위해, Whisper에서는 specify all task, conditioning information을 위한 sequence of input tokens 제공 → Decoder 훈련을 위한 input token으로 함께 제공됨(Special tokens)
<|startoftranscript|>: 예측의 시작을 알리는 토큰<|nospeech|>: 오디오 segment에 음성이 없는 경우 이를 예측하도록 훈련<|transcribe|>,<|translate|>: 전사 혹은 번역 Task를 지정<|notimestamps|>: 타임스탬프를 예측할지에 대한 여부 표현<|endoftranscript|>: 마지막을 알리는 토큰
Whisper 훈련과정
주요 훈련 지표
- 옵티마이저 → AdamW
- Learnig rate scheduler → 첫 2048 스텝 warmup 후 linear decay(0까지 감소)
- 배치 크기 → 256개 오디오 세그먼트(batch size=256)
- Gradient Clipping : 사용 (기울기 폭발 방지)
- 정규화/증강 → 별도 데이터 증강 없음, 대규모·다양성 데이터에 의존
- 훈련 epochs → 전체 데이터셋 2~3회 반복(총 220 updates)
- 데이터 포맷 → log-Mel 스펙트로그램(80채널, 30초 이하 세그먼트)
- 데이터 다양성 활용
- 메모리 효율성을 위해 → FP16(반정밀도) 연산, 동적 손실 스케일링, 체크포인트 저장
훈련 워크플로우
- 각 세그먼트 입력 준비
- 30초 이하 오디오(Log-Mel 스펙트로그램)
- 해당 작업 명시하는 특수 토큰 시퀀스 첨부
- 모델 학습 방식
- Transformer Encoder: 오디오→의미 벡터 시퀀스 변환
- Transformer Decoder: 특수 토큰 입력받아 순차적으로 텍스트 생성
- Self-Attention, Cross-Attention 등 표준 구조 반복
- 태스크별 동시 최적화
- 오디오와 태스크 명시 토큰이 매칭된 정답 텍스트 예측
- 타임스탬프 예측, 음성 감지, 언어 감지 등도 동시에 Loss에 포함해 훈련
4. Whisper 만의 차별점 및 강점 / 한계
1) 제로샷 성능과 일반화(Zero-Shot Performance & Robustness)
Whisper는 새로운 환경이나 데이터셋(예: 방송, 강의, 실생활 대화 등 초면 환경)에서 ==별도 파인튜닝 없이도== 기존 모델 대비 뛰어난 음성 인식 성능을 보임
ASR 모델 비교: 기존 모델 vs Whisper
기존 ASR 모델
→ 특정 데이터셋(예: LibriSpeech)에 맞춰 학습·테스트할 때만 높은 성능이 나오고, ==새로운 환경·데이터셋에서는 성능이 크게 떨어짐==
Whisper 모델
- 파인튜닝 없이도(LibriSpeech에 맞춰 추가 학습 없이) ==매우 다양한 데이터셋에서 낮은 오류율(WER)== 및 뛰어난 성능 보임
- 즉, Whisper는 단일 학습만으로도 “다른 종류의 말”을 거의 다 알아듣는다는 점이 Whisper 실험의 핵심적인 결과
실험 결과
- LibriSpeech test-clean에서 2.5% WER → 기존 SoTA 모델과 비슷
- 그러나, 여러 새로운 데이터셋에서는 기존에 비해 평균 55.2%의 오류 감소
- 가장 작은 Whisper 모델(39M 파라미터)은 LibriSpeech 전용 최고 모델에 준하는 성능을, 여러 도메인에서는 오히려 더 우수한 결과 달성
2) 범용성: 다국어 성능 & 저자원 언어(Underrepresented Languages)에 대해
Whisper는 영어 이외에 ==99개 언어에 대한 음성 인식 능력==을 갖춤 특히, 저자원 언어(언어 데이터가 적은 언어)에서도 ==제로샷 또는 소량 파인튜닝만으로 성능이 크게 향상==됨
- ex) 파슈토(Pashto), 펀자브어(Punjabi), 우르두어(Urdu) 등 남아시아 언어에서 소규모 파인튜닝 시 상당한 WER 감소
- 기본 제로샷 성능은 제한적이지만, 약간의 추가 데이터로도 급격히 개선되어, 실제 세계 저자원 언어에 실질적 효과
3) 인간 수준의 Robustness / 현실 환경에 대한 robustness
Whisper의 large 모델은 성능이 ==인간 transcriber와 거의 유사==한 견고성과 정확도에 도달함 그러나, 실제 평가에서는 표준 테스트셋만 볼 것이 아니라, 다양한 도메인/환경/언어/잡음 에서의 “제로샷” 성능이 중요하다는 점을 강조했음
- 일반화 평가에서 Whisper는 “기존 ASR 시스템은 특정한 기준에서만 좋다”는 한계를 극복한 첫 사례로 제시됨
4) 노이즈에 대한 내성 / Noise-Conditioned Mechanism
기존 대다수의 음성인식 모델은 “노이즈를 아예 제거”하는 방향으로 설계됨 → Whisper와 차이
- Whisper는 ==노이즈의 종류== 자체까지도 벡터에 같이 encode해서 “어떤 잡음 환경에서 무슨 말을 하는지”를 구별함 → Whisper가 ==실제 현실의 배경 소음(음악, 펍, 레스토랑 등)에 강한== 이유
- 즉, 단순 무잡음(invariant) 설계가 아니라, ==다양한 노이즈 환경을 함께 이해==하는 방식
- 이러한 메커니즘 덕분에, ==ASR과 오디오 태깅(음성 내에서 다른 사운드 이벤트까지 인식)을 하나의 패스로 동시에 처리==할 다양한 확장연구로 이어짐
한계와 문제점: 환각(hallucination) 및 언어/억양 차별성
- Whisper도 때로 환각(hallucination) 현상이 일부 발견됨 출처: Evaluation of Off-the-shelf Whisper Models for Speech Recognition Across Diverse Dialogue Domains
- 영어(특히 미국식)의 성능은 매우 우수하나, ==비영어/비표준 방언, 강한 억양== 등에서는 성능이 일부 떨어짐
- 실제 평가 결과, 아메리칸 영어(General American)에서 성능이 가장 높고 비원어민/다중 억양에서는 인식률이 낮아지는 경향이 보고됨 출처: Evaluating OpenAI’s Whisper ASR: Performance analysis across diverse accents and speaker traits
결론 및 실무적 의의
- Whisper는 ==데이터 다변성==과 ==대규모 멀티태스킹 학습==만으로 실제 환경에서의 범용성, 제로샷 일반화 성능, 다국어 및 노이즈 견고성을 동시에 달성
- 인간 수준의 성능 달성 외에도, 앞으로 ==음성-오디오-텍스트를 통합하는 새로운 패러다임==(앱, 서비스 구현 등)에 Whisper가 실용적이고 확장성 높은 출발점이 될 수 있음을 시사
chat_bubble 댓글남기기
댓글남기기