1. 모델 과적합(Over-fitting)
과적합
- 정의
- 훈련한 데이터에 대해서는 예측을 잘하는 반면, 검증 데이터나 새로운 데이터에 대해서는 성능이 떨어지는 현상
- 과적합 vs 과소적합
- 과소적합
- 모델 복잡도에 비해 데이터셋의 크기가 너무 큰 경우
- 데이터의 패턴을 잘 이해하기 못한 경우
- 과적합
- 데이터의 양에 비해 모델의 크기/복잡도가 너무 작은 경우
- 주어진 데이터에만 과하게 훈련된 경우
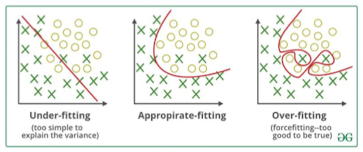
- 과소적합
- 과적합 여부를 판단할 수 있는 방법 → loss or metric 관찰
- 학습 그래프 관찰
- 학습을 진행할 수록
- train loss는 감소하지만, validation loss는 감소하지 않는 경우
- train score는 증가하지만, validation score는 증가하지 않는 경우

- 학습을 진행할 수록
- train/valid score 비교
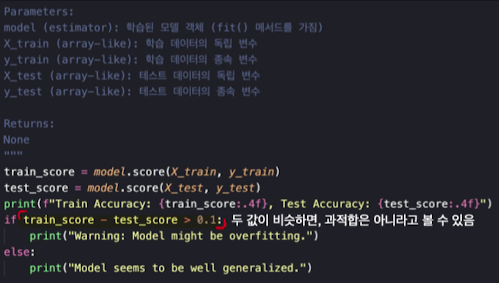

- Unseen 데이터(valid, test)에 대한 예측 양상 관찰
- 모델이 한번도 학습하지 않은 새로운 데이터를 예측할 수 있는지 관찰
- ex) 자동차 이미지 분류 문제에서, 밝고 맑은 날 촬영한 이미지만 학습한 모델은 비오고 흐린 날 촬영한 이미지에 대해서는 예측 성능이 떨어질 수 있음
- 학습 그래프 관찰
- 과적합을 방지하는 방법
- 교차 검증
- 데이터를 여러 부분으로 쪼개어, 모델을 반복 학습하고 평가하는 방법
- 과적합을 “수월하게 탐지한다” 정도
- 정규화(Regularizataion)
- 모델의 복잡성을 제어하여, 과적합을 방지하는 기법
- L1 정규화, L2 정규화 등
- 드롭아웃(Dropout)
- Deep Learning에서, 일부 노드를 무작위로 비활성화해서 과적합을 방지하는 방법
- 비활성화 후 활성화 → “학습단계에서 앙상블한다” 정도로 이해해도 무방
- 조기 종료(Early Stopping)
- Valid error가 증가할 때 학습을 멈추는 방법
- Valid error가 증가할 때 학습을 멈추는 방법
- 교차 검증
정규화
- 과적합된 모델은 모델이 갖는 가중치 값이 극단적으로 큰 경향이 있음
- 이를 예방하기 위해, loss function에 패널티항(가중치의 L1 norm, L2 norm)을 추가하여 방지해주는 것
- 종류(회귀모델)
- Lasso: Loss에 L1 norm을 더해주는 방법
- 수식:$\text{Minimize}(\sum_{i=1}^{n} (y_i - \hat{y}i)^2 + \lambda \sum{j=1}^{p} \vert \beta_j \vert)$
- L1 norm: (여기서는)회귀 계수의 절댓값의 합
- 패널티항: 회귀 계수의 절대값 합계를 최소화
- 특징
- 일부 가중치를 0으로
- 중요한 feature를 선택할 수 있는 효과
- 모델에 Sparsity(0이 많은 모델) 추가
- Feature Selection에 유용
- Ridge: Loss에 L2 norm을 더해주는 방법
- 수식:$\text{Minimize}(\sum_{i=1}^{n} (y_i - \hat{y}i)^2 + \lambda \sum{j=1}^{p} \beta_j^2)$
- L2 norm: (여기서는)회귀 계수의 제곱의 합
- 패널티항: 회귀 계수의 제곱합을 최소화
- 특징
- 큰 가중치 값을 작게
- 모델의 전반적인 복잡도 감소
- 가중치가 0이 되지는 않도록 / 모든 가중치를 균등하게 작게
- 모델 과적합 방지에 유용
- Lasso: Loss에 L1 norm을 더해주는 방법
2. 교차 검증 프로세스 이해하기
교차 검증(Cross Validation)?
- 주어진 데이터셋을 여러개로 나눠, 이를 이용해 모델 성능을 평가
- 목적: 모델의 일반화 성능 평가
- 종류: K-fold, Stratified K-fold 등
교차 검증(Cross Validation)이 필요한 이유
- 모델 일반화 능력 평가
- 과적합 위험 방지 → 새로운 데이터에 대해 얼마나 잘 일반화 되어 있는지 평가
- 평가 신뢰성 증가
- 데이터셋의 다양한 부분에 대해 테스트 가능 → 모델 평가의 신뢰성 증가 / 다양한 데이터 분할에 대한 모델 성능 확인 가능
- 효율적인 데이터 사용
- 교차검증은 데이터를 분할하여 데이터를 최대한 활용하고자 하는 목적 → 데이터셋이 작을 경우 교차 검증 유용
- 교차검증은 데이터를 분할하여 데이터를 최대한 활용하고자 하는 목적 → 데이터셋이 작을 경우 교차 검증 유용
K-fold 교차검증
- 데이터를 동일한 크기를 갖는 K개의 부분 집합으로 나누고, 그 중 1개는 valid data / 나머지는 학습 데이터로 사용하는 교차 검증 방법
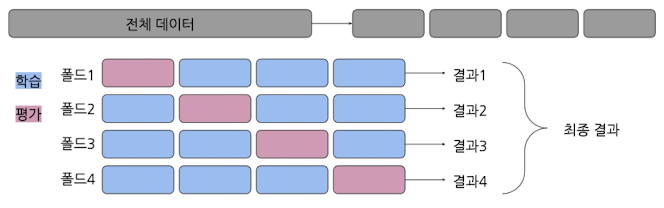
- 각 fold는 한 번씩 테스트 데이터로 활용
- 최종적으로, K번의 학습 및 테스트 수행
- 특징
- 장점
- 데이터 활용을 극대화할 수 있음
- 일반화 성능 평가 / 과적합 방지
- 단점
- 데이터의 클래스 분포가 매우 불균형할 경우, 성능 평가에 문제 → 어떤 폴드에는 특정 클래스의 데이터가 전무할 수도 있음
- 데이터가 너무 적은 상황이면, 오히려 역효과를 낼 수도
- 장점
Stratified K-fold 교차검증
- 클래스의 분포를 균등하게 유지하며 폴드를 나누는 방법
- 클래스 불균형 문제가 있는 K-fold의 단점을 보완한 방법
- 분류 문제에 특화되어 있는 교차 검증 방법 → 회귀 문제는 일반적으로 K-fold 사용 권장
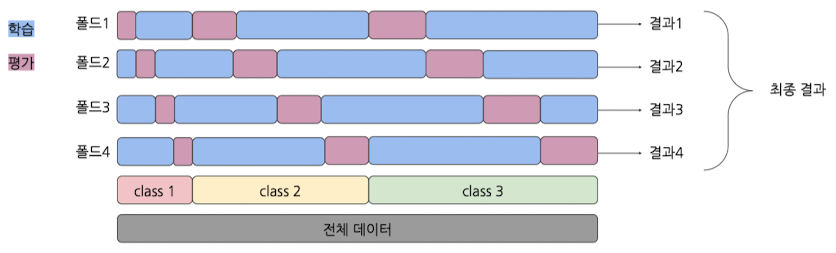
- 특징
- 장점
- 클래스 불균형 문제 해소 → 각 폴드가 전체 데이터셋 분포에 대한 표현력 상승
- 단점
- K-fold보다 계산 속도가 늦을 수 있음 → 폴드 별로 클래스 비율을 유지해야 하므로 (크게 체감될 정도는 아님)
- Stratified K-fold 역시, 데이터셋이 매우 작거나 불균형할 경우 모든 폴드에 모든 클래스를 포함시키지 못할 수 있음
- 장점
Time Series Split 교차검증
- 시계열 데이터의 특성을 고려한 교차 검증 방법
- 일반적인 K-fold 검증법을 활용하면, 미래 데이터가 과거 데이터를 예측하는 상황이 발생할 수 있음 → 이를 대비하여, 시간의 흐름을 고려한 데이터 분할 기법
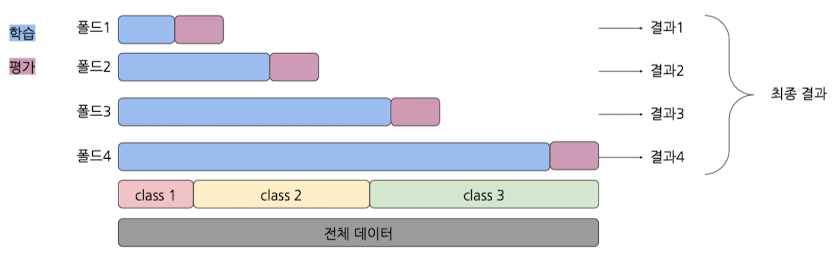
- Time Series Split의 핵심 원칙
- 데이터를 무작위로 섞지 않고, 관측된 시간 순서 유지
- 과거 → 미래의 방향으로 분할
- 학습 데이터는 항상 검증 데이터보다 이전 시점의 데이터로 구성
- 누적 학습
- 각 분할의 학습데이터는, 이전 분할의 학습 데이터를 포함하면서 점진적으로 확장됨
- Time Series Split 작동 순서
- 1번째 폴드: 첫 20% 데이터 학습 / 다음 20% 학습 데이터 검증
- 2번째 폴드: 첫 40%(20+20) 데이터 학습 / 다음 20% 학습 데이터 검증
- 3번째 폴드: 첫 60%(40+20) 데이터 학습 / 다음 20% 학습 데이터 검증
- 이와 같은 과정을 splits 횟수만큼 반복
- 특징
- 실제 상황에서 모델이 미래 데이터를 예측하는 방식과 유사하게 평가 진행
- split이 지날 수록, 훈련 데이터의 양이 점진적으로 증가 → 초기 분할에서는 훈련 데이터가 적어 모델의 성능이 낮을 수 있음
교차 검증 적용 시 고려해야 할 부분
- 시간 복잡성 증가
- 교차 검증 횟수 K가 증가함에 따라, 그 결과를 보기 위한 시간도 함께 증가
- K번의 학습과 검증 이후 결과를 내기 때문
- 컴퓨팅 자원과 시간에 따라 적절한 K값의 선택이 필요
- 데이터 전처리
- (교차 검증의 각 수행(폴드)마다) 훈련 데이터와 테스트 데이터를 분할한 후 별도로 데이터 전처리를 수행해야 함
- 각 폴드 내에서 개별적으로 데이터 전처리
- scikit-learn의
Pipeline, cross_val_score사용 → 데이터 전처리와 모델 학습 연결 가능
- (교차 검증의 각 수행(폴드)마다) 훈련 데이터와 테스트 데이터를 분할한 후 별도로 데이터 전처리를 수행해야 함
chat_bubble 댓글남기기
댓글남기기