1. 모델 앙상블
앙상블(Ensemble)
- 데이터 예측 수행 시, 단일 모델만을 사용하기 보다 여러 모델을 같이 이용하는 것이 더 좋은 예측 성능을 보일 수 있음 → 단일 알고리즘으로 적당한 알고리즘을 여러 개 조합하여, 단일 알고리즘에 비한 성능 향상을 기대하며 사용하는 기법
- 여러 개의 단일 모델들의 평균치를 내거나, 투표를 해서 다수결에 의한 결정을 하는 등 여러 모델들의 집단 지성을 활용하여 더 나은 결과를 도출해 내는 것에 주 목적이 있음
- 앙상블 관련 연구 결과
- 특정 알고리즘이 모든 문제에 대해 우월하거나 모든 문제에 대해 열등하지는 않다는 내용의 연구 결과
→ 하나의 알고리즘보다 한 가지 이상의 알고리즘을 앙상블하여 사용하는 것이 더 좋은 성능을 얻을 수 있다는 인사이트 도출
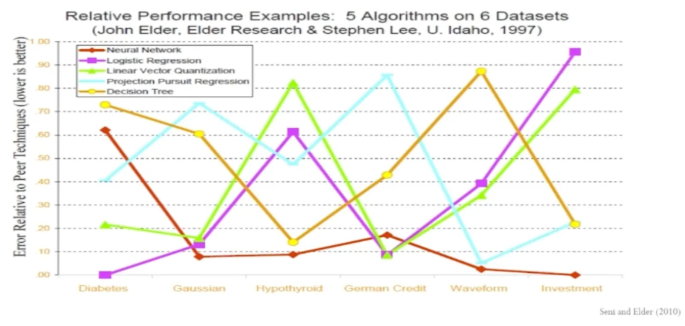
- 특정 알고리즘이 모든 문제에 대해 우월하거나 모든 문제에 대해 열등하지는 않다는 내용의 연구 결과
→ 하나의 알고리즘보다 한 가지 이상의 알고리즘을 앙상블하여 사용하는 것이 더 좋은 성능을 얻을 수 있다는 인사이트 도출
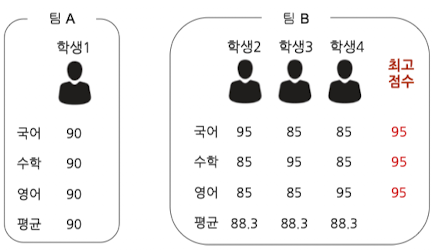
- 비유를 통한 모델 앙상블 알아보기
- 학생을 모델 / 각 시험과목을 예측 데이터로 비유
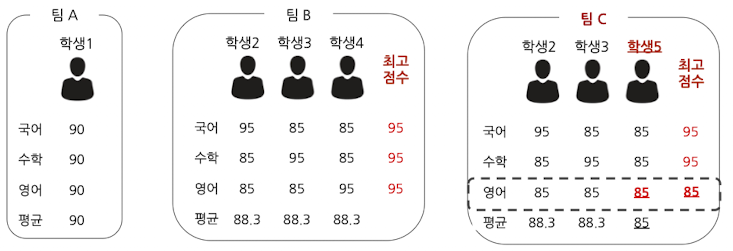
- 각자 잘 하는 과목이 있는 전교 2, 3, 4등이 뭉치면(팀 B) → 전 과목을 준수하게 잘하는 전교 1등(팀 A)을 이길 수 있음
- 하지만, 어떤 과목에 대해서는 고만고만한 학생들끼리 뭉쳐서는 전교 1등을 이길 수 없음
모델의 분산과 편향
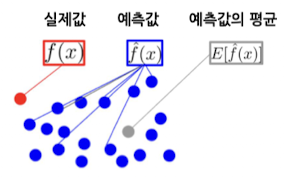
- 편향 - 얼마나 예측값이 실제값과 다른지

- 분산 - 모델이 출력하는 예측값이, 같은 샘플들에 대해 얼마나 달라질 수 있는지

2. 앙상블 기법
Bagging(배깅, bootstrap aggregating)
- 다양한 데이터 부분집합(bootstrap sample)으로 훈련된 모델들을 통합하여 예측 정확도를 향상시키는 앙상블 기법
- bootstrap aggregating → 샘플을 다양하게 생성 / 훈련 데이터 세트에 중복을 허용하여(복원추출) sampling하는 방식
- 최적화 방법 → 모델의 분산 감소 / 과적합을 방지하기 위해 설계된 기법
- Bagging 과정
- Bootstrap Sampling
- 복원 추출을 통해 원본 데이터셋에서 동일한 크기의 부분집합 생성
- 각 Sample은 63.2%의 고유 데이터 포함(일부 중복 허용) → 수학적 증명에 기반한 결과
- 각 모델 병렬 훈련
- 각 모델들은 샘플링된 각 bootstrap sample에 의해 추출된 데이터셋으로 각각 독립적으로 훈련
- 여기서 활용하는 모델은, 여러 개의 동일한 유형(알고리즘)의 모델을 활용해야 함
- 예측 통합
- 각 모델이 개별적으로 예측한 값을 통합하여 하나의 결과 도출
- 회귀 문제: 개별 모델 예측값의 (산술)평균(soft voting)
- 모델 간 상관관계가 낮을 수록, 분산 감소 효과 증대
- 분류 문제: 각 모델의 예측값 중 가장 높은 값(다수결 투표, hard voting)
- 회귀 문제: 개별 모델 예측값의 (산술)평균(soft voting)
- 각 모델이 개별적으로 예측한 값을 통합하여 하나의 결과 도출
- Bootstrap Sampling
- 앙상블 기법의 Bagging에서 63.2% 고유 데이터 포함률 증명
- 단일 데이터 선택 확률:
- 원본 데이터셋 크기를 $n$이라 할 때,
- 한 번의 추출에서 특정 데이터가 선택될 확률: $1/n$
- 선택 되지 않을 확률: $1-1/n$
- n회 추출 시 확률 계산:
- 복원 추출을 $n$번 반복할 때,
- 특정 데이터가 한 번도 선택되지 않을 확률: $P = (1-1/n)^n$
- 대규모 데이터셋 근사
- $n \rightarrow \infty$ 일 때,
- $\lim_{n \to \infty}(1-1/n)^n$ = $1/e \simeq 0.632$ ⇒ 63.2%
- 데이터가 적어도 한 번은 선택될 확률 → 36.8%
- 단일 데이터 선택 확률:
Boosting
- 여러 개의 weak learner를 결합하여 하나의 strong learner를 만드는 데 사용되는 알고리즘
- Weak learner: 예측 정확도가 낮음(무작위 추측과 비슷할 정도) / Overfitting에 취약 → 원본 데이터 집합과 너무 많이 다른 데이터는 분류 불가능
- Strong learner: 예측 정확도 높음 / 부스팅
- 매우 단순한 모델들을 순차적으로 구축하여, 오류 보정을 거쳐 모델의 성능을 단계적으로 향상시키는 기법
- 예측 데이터 분석의 오차를 줄이기 위한 기법
- 예측 성능이 뛰어나, 앙상블에 가장 많이 활용되는 기법 (LightGBM, XGBoost, CatBoost 등)
- Boosting 과정
- 일단 데이터 샘플은, bagging과 유사하게 초기 샘플 데이터 생성
- 초기 가중치 할당
- 모든 데이터 포인트에 동일한 가중치 부여
- N개의 데이터에 대해, 초기 가중치 $1/N$ 부여
- Weak learner 훈련
- 첫번째 Weak learner를 훈련 데이터에 맞춤
- 첫번째는 일반적으로 무작위 sample 데이터보다 전체 데이터 활용
- 오류 분석 및 가중치 조정
- 학습 후, 첫번째 weak learner에 대한 오류율($\epsilon$) 및 영향력($\alpha$) 계산
- 이후, 가중치 조정
- 오분류된 데이터의 가중치 증가
- 정분류된 데이터의 가중치 감소
- 순차적 반복
- 이렇게 업데이트 된 가중치를 기반으로, 강화된 weak learner
- 지정된 횟수만큼 반복, 각 단계마다 이전 모델의 오류 보완
- 가중치 합산 예측
- 각 단계 모든 learner의 예측값을 가중 합산하여 최종 예측 수행
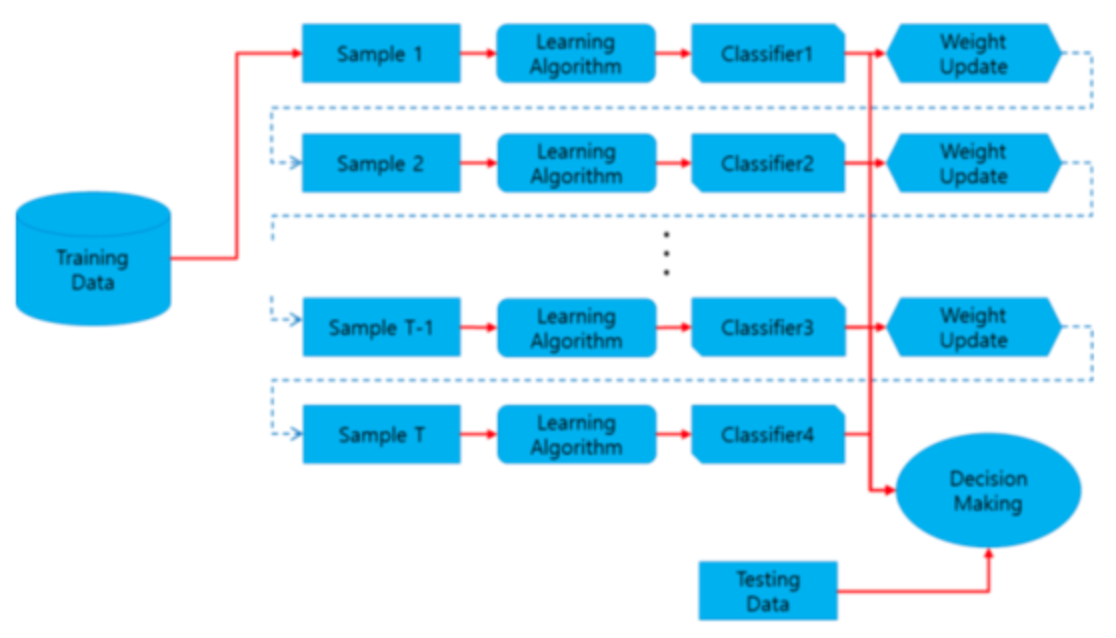
- 각 단계 모든 learner의 예측값을 가중 합산하여 최종 예측 수행
Voting(투표)
- 분류 문제에서만 적용
- 여러 분류기가 투표를 통해 결정하는 방식
- Soft Voting, Hard Voting 크게 두 가지로 나뉨
- Voting vs. Bagging
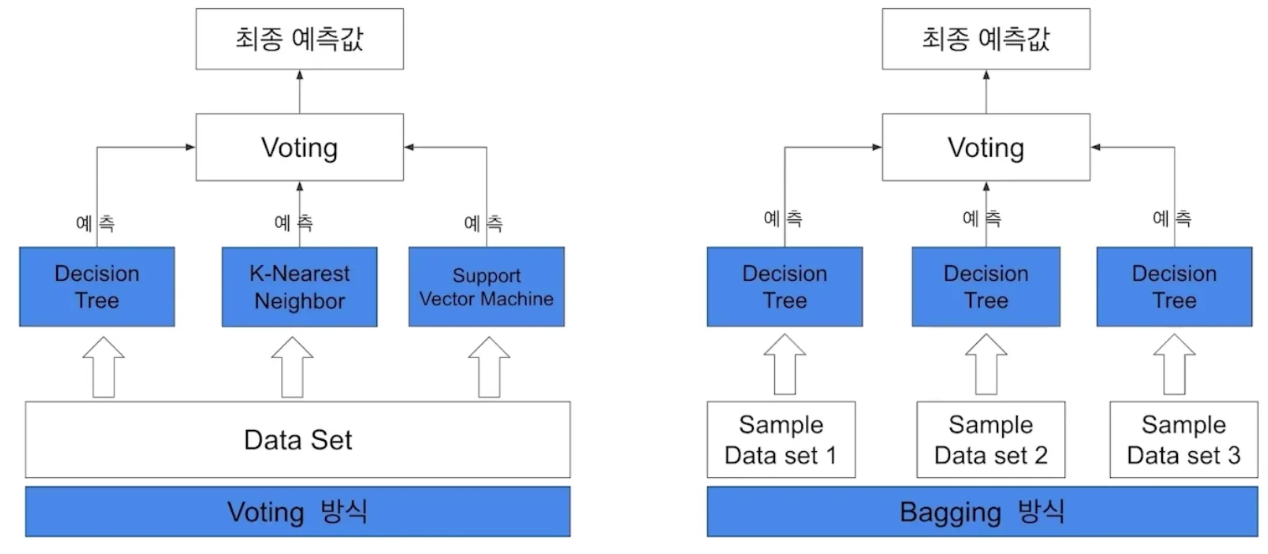
- Voting: 다른 알고리즘 model 조합
- 여러 개의 알고리즘을 선택해 voting
- 데이터셋은 그대로
- Bagging: 같은 알고리즘 내에서, 다른 Sample 조합 사용
- Data를 여러번 Sampling
- 알고리즘은 그대로
- Voting: 다른 알고리즘 model 조합
- Voting은 서로 다른 알고리즘이 도출한 결과물에 대해 최종 투표하는 방식
- Voting 종류
- Soft Voting
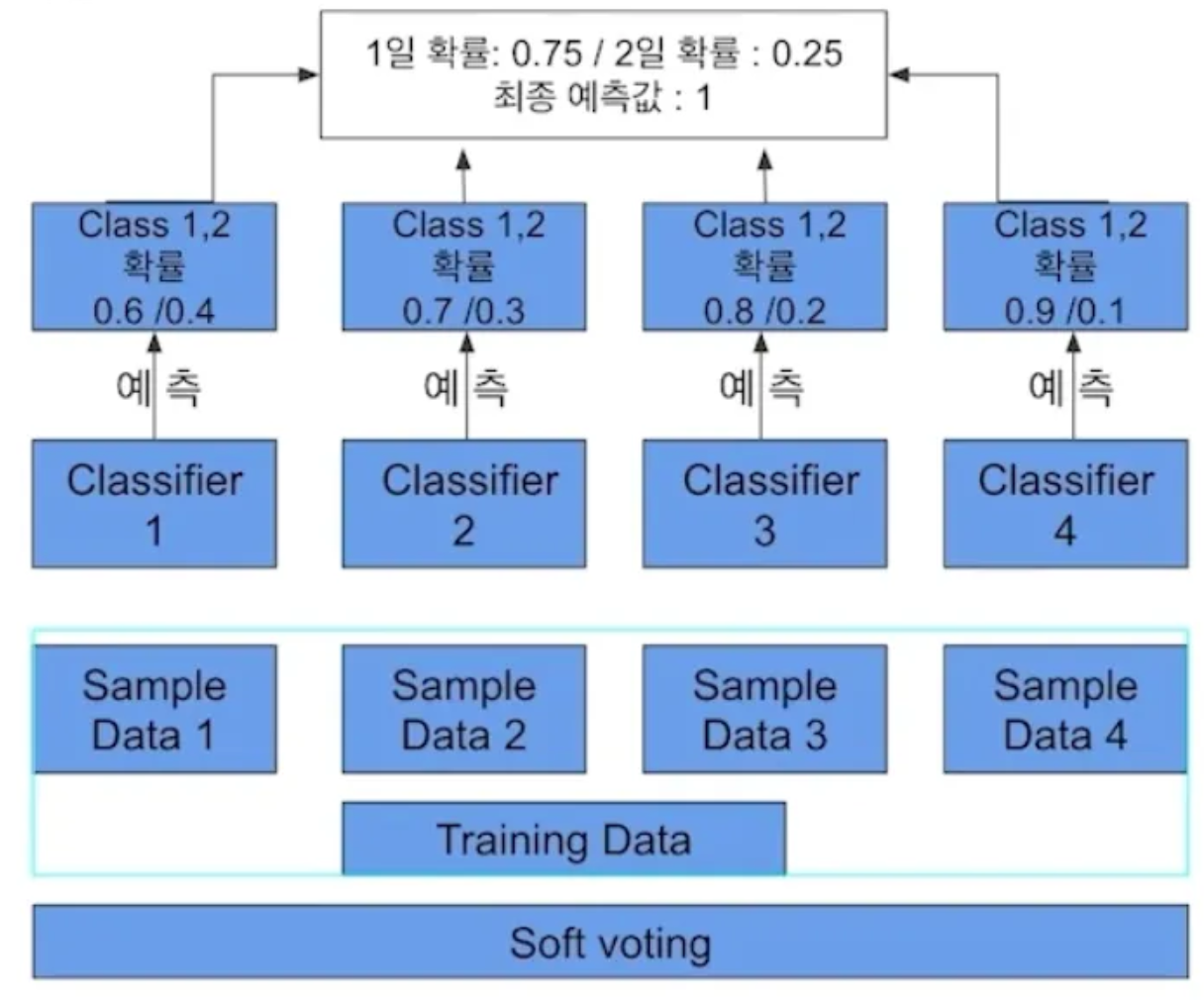
- 분류기들의 (레이블값 결정)확률을 모두 더함 → 평균해 확률이 가장 높은 레이블 값을 최종 결괏값으로
- 확률값 기반 예측
- 일반적으로 Voting은 Soft Voting 활용
- Hard Voting
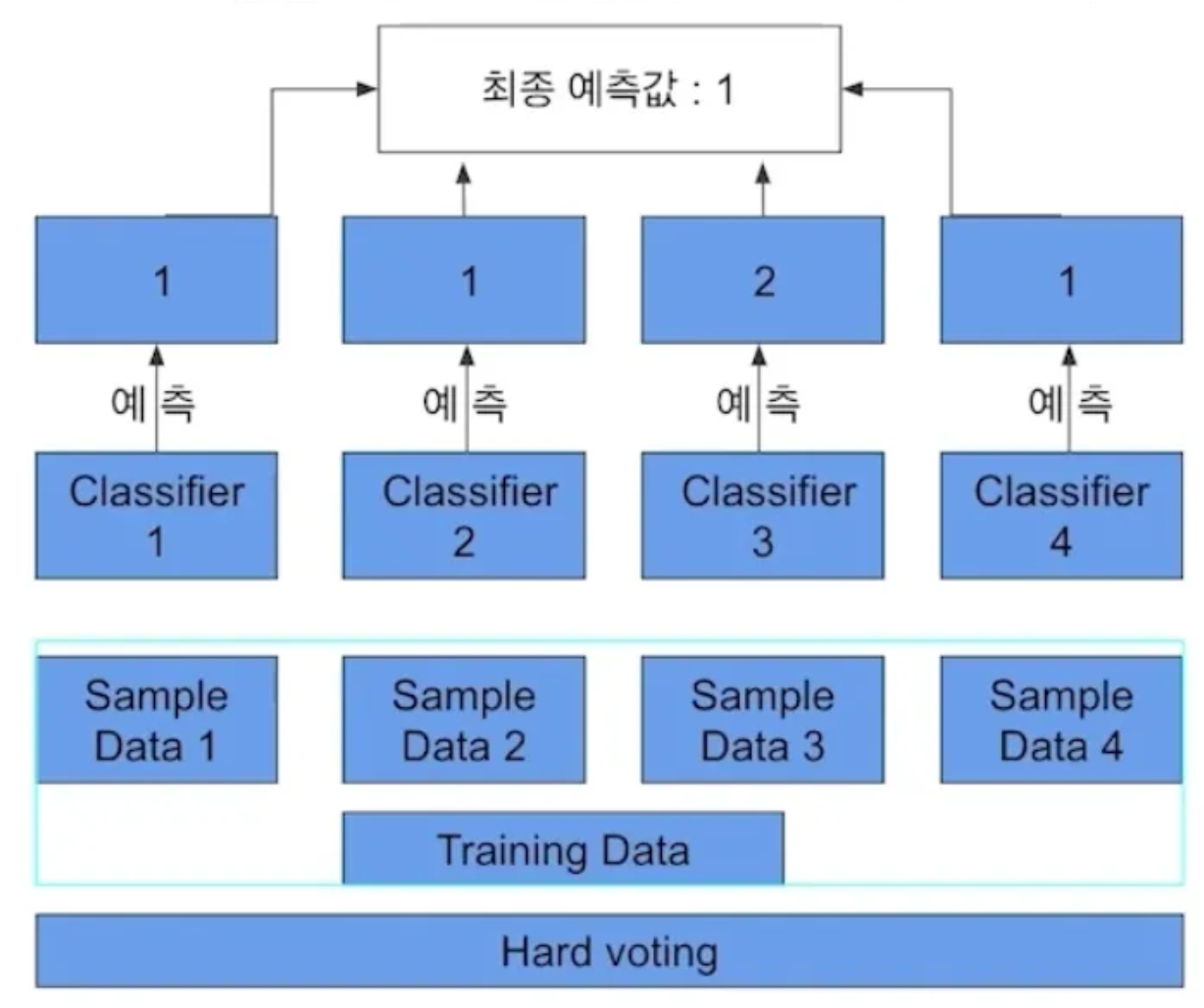
- 결과물에 대한 최종 값을 투표해서 결정 / 다수결 원칙과 유사
- 라벨 기반 예측
- Soft Voting
교차 검증 앙상블
- 교차 검증 프로세스를 응용한 앙상블 기법
- 모델의 일반화 성능을 향상시키는 두 가지 핵심 방법론(Cross Validation, Ensemble)을 결합하여, 모델의 안정성과 예측 정확도를 극대화시키는 방법론
- 기본 개념
- 전체 데이터를 K개의 폴드로 나눔 → Cross Validation 수행
- 각 fold마다 모델에 학습시킴 → Valid data를 이용하여 평가
- 평가 예측 결과를 결합하여(평균 / 다수결 등) 최종 예측 생성
- OOF(Out-Of-Fold)
- k-Fold 교차 검증 과정에서 생성된 검증 세트 예측값을 의미
- 각 폴드에서 훈련된 모델이 해당 폴드의 검증 데이터에 대해 수행한 예측을 집계하여 모델 성능을 평가
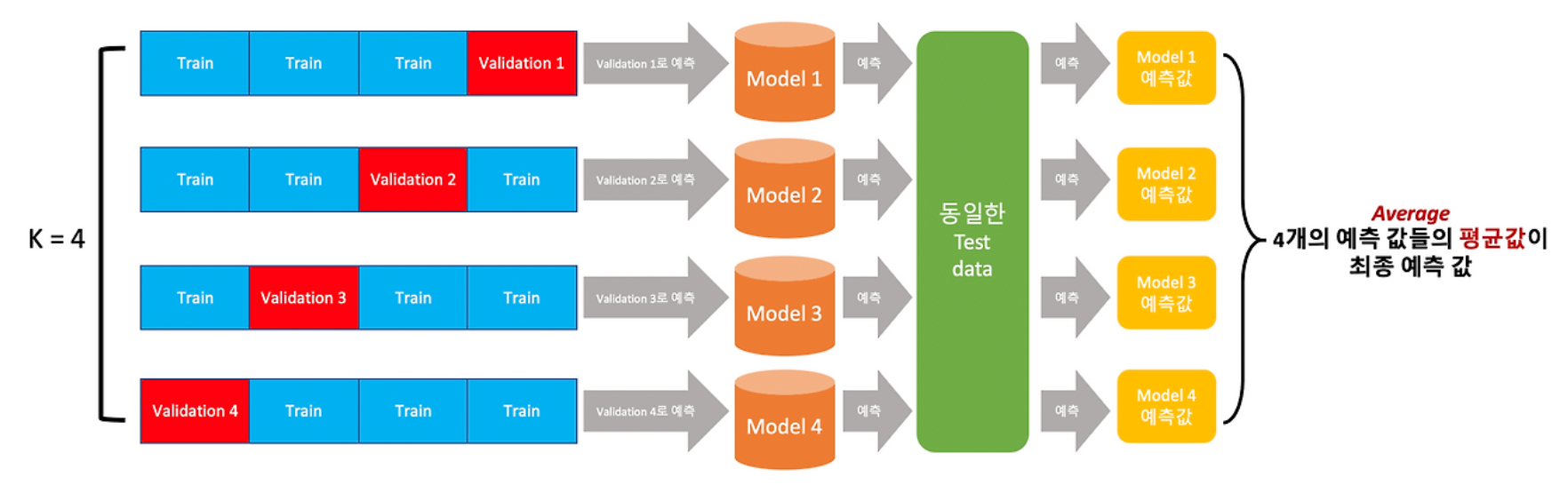
- 특징
- 데이터를 여러 부분으로 나눠, 반복적으로 모델을 학습하고 평가할 수 있음 → 새로운 데이터에 잘 일반화하고 과적합을 방지할 수 있는지 측정
- 여러 번의 평가를 거쳐 안정적인 모델 성능 평가가 가능
- (현업서 와닿는 부분)여러 번 모델 학습과 평가를 수행하므로, 구현 및 유지보수가 복잡함
- (당연히 앙상블이기 때문에) 시간 및 계산 비용은 증가
스태킹 앙상블
- 메타 모델을 활용한 앙상블
- 메타 모델(Meta Model) → 가중치를 어떻게 셋업할지 학습하는 모델
- 상세
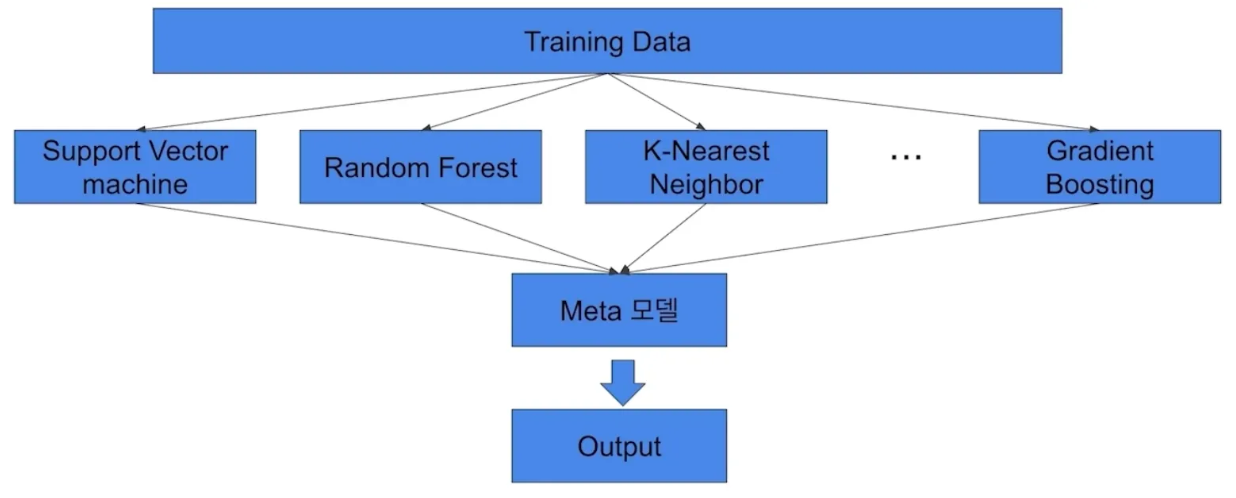
- Base Runner Model → 스태킹 앙상블의 재료가 되는 모델의 결괏값
- Support Vector Machine / RF / K-Nearest Neighbor … Gradient Boosting
- Meta Model → 최종 결과 도출 모델
- Base Runner Model → 스태킹 앙상블의 재료가 되는 모델의 결괏값
- 특징
- 성능의 월등한 향상효과 있음(여러 모델의 학습 결과를 바탕으로 메타 학습을 수행)
- 경진대회(Kaggle 등)에서 성능을 쥐어짜내기 위한 트릭으로 이용되기도 함
- 개별 모델의 과적합을 방지할 수도 있지만, 반대로 어떻게 구현하느냐에 따라 과적합이 발생할 수도 있음
- 메타 모델을 활용하여, 복잡한 패턴을 학습할 수 있음 (단일 모델로는 잡아내기 어려운)
- 데이터가 충분치 않으면, Stacking Ensemble의 효과가 제한될 수 있음
- 다양한 모델을 결합할 수 있음
- 거의 대회 전용으로 성능 쥐어짜기 용도로 활용
- 모델이 너무 무거워지고,
- 매우 많은 시간이 필요
- 성능의 월등한 향상효과 있음(여러 모델의 학습 결과를 바탕으로 메타 학습을 수행)
chat_bubble 댓글남기기
댓글남기기