1. 최신 Recsys 동향
1.1 추천시스템 최근동향
- Recsys 발전방향
- Shallow Model
- 행렬 분해를 Recsys에 활용(잘 모델링 하려면, 어떻게 행렬을 분해해야 할까)
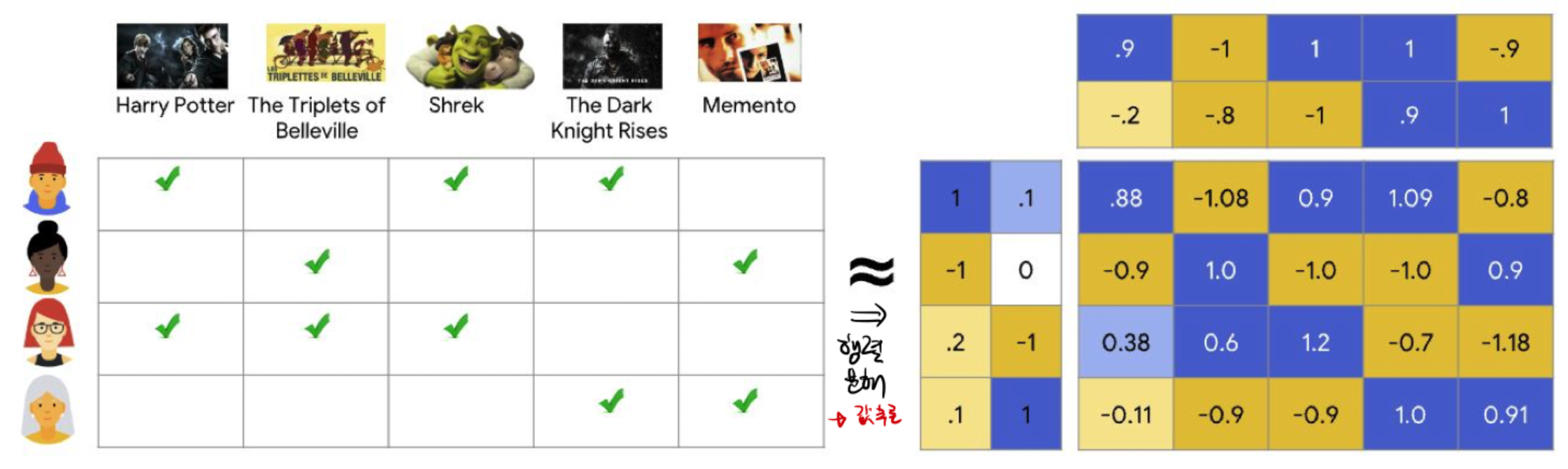
- 좌측 : user matrix
- 상단 : item matrix
- 가운데(원소) : user matrix * item matrix
- 행렬 분해를 Recsys에 활용(잘 모델링 하려면, 어떻게 행렬을 분해해야 할까)
- Deep Model
- Neural Network를 활용한 모델링(AutoRec)
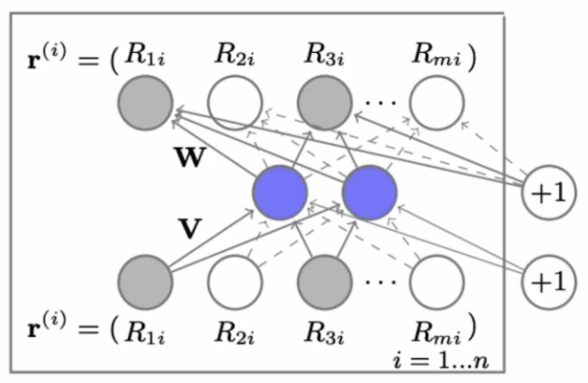
- Rating Matrix : i번째 item을 소비하는 User들 / binary로 사용여부 표기
- Rating Matrix를 input, 해당 input을 최대한 그대로 복원 → 관측되지 않은 Data에 대해 추론 가능
- Neural Network를 활용한 모델링(AutoRec)
- Large-scale Generative Models
- Text based(Multitasking)
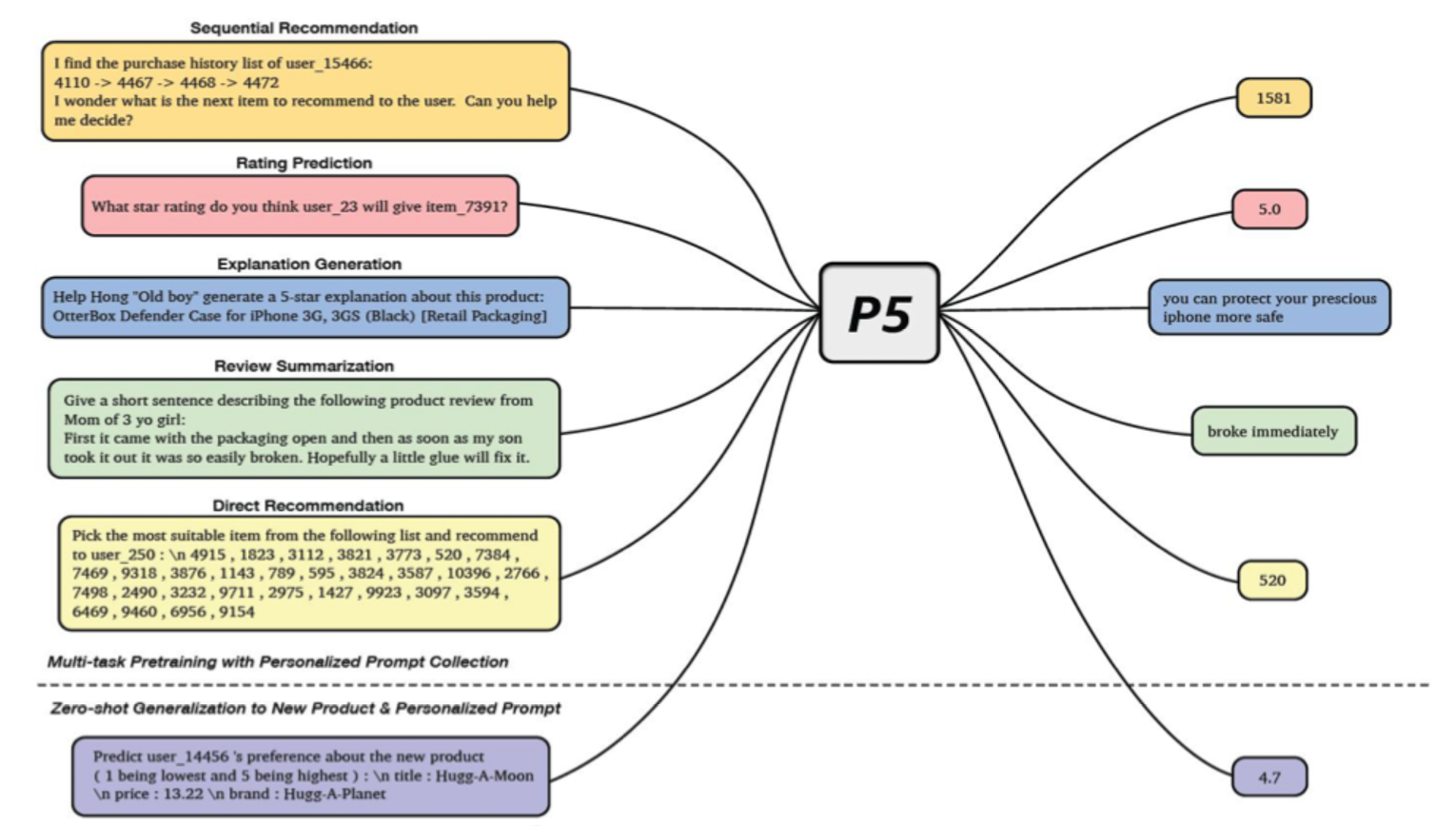
- P5 ⇒ Text 입력 시 번역/감정 분류/요약 등 여러가지 task를 하나로 수행 가능한 통합 모델
- Multi-Modal based(text + img)
- Diffusion based(CV, L-DiffRec)
- Noise를 어떻게 가하는지 추론 ⇒ 반대로 빼주면 목적 달성(복원)
(베네시안 AutoEncoder)
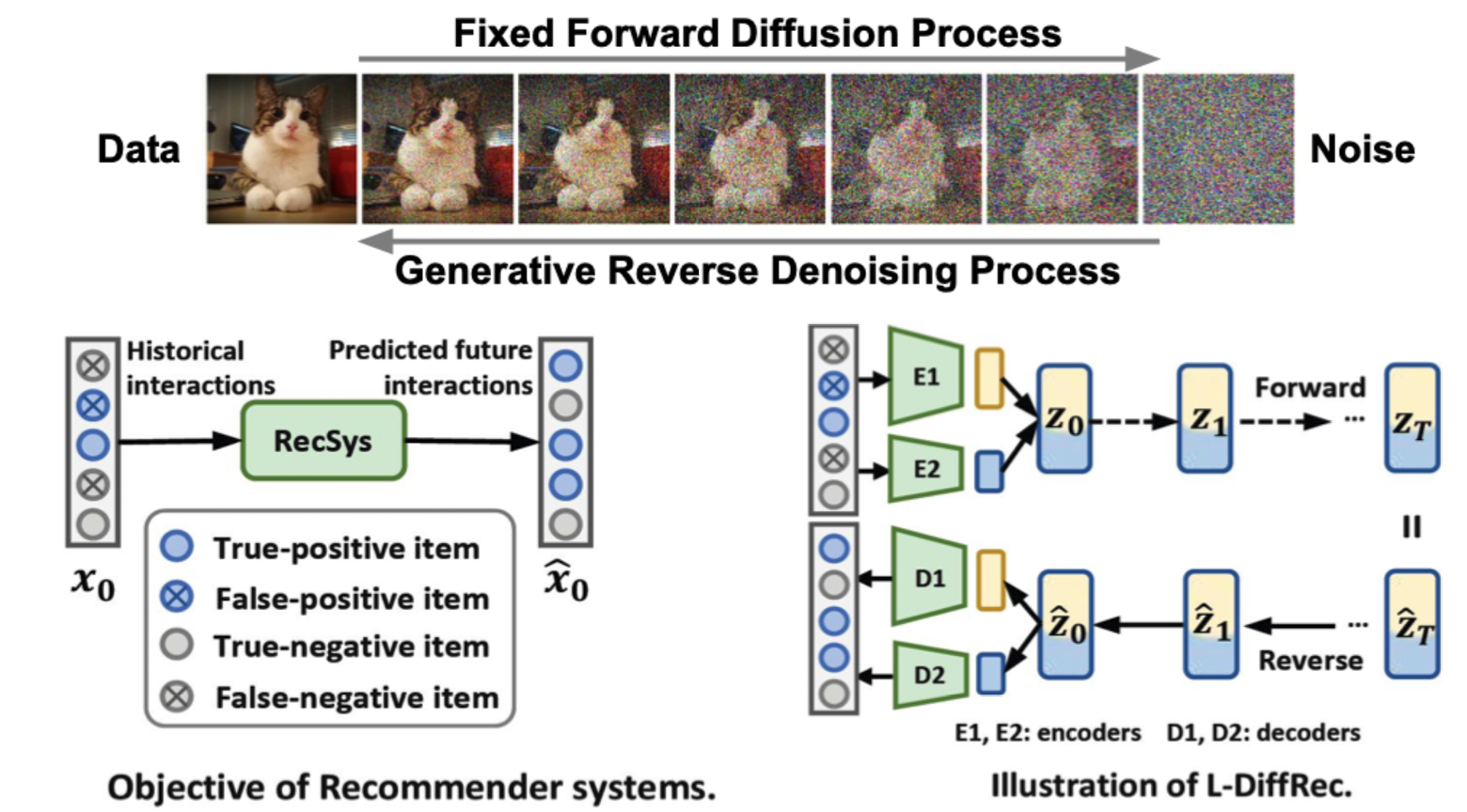
- Objective of Recommender Systems
- Historical Interactions - Diffusion 모델을 RecSys에 활용 / 일부의 관측값만 주어짐
- Predicted future interactions - Historical Interaction이 RecSys를 통과하면서 그럴듯한 Rating Matrix로 변환
- Noise를 어떻게 가하는지 추론 ⇒ 반대로 빼주면 목적 달성(복원)
(베네시안 AutoEncoder)
- 결국 Recsys의 발전 방향?
- “Explainability”
- 왜 이것을 추천?
- item 간 관계?
- 유저의 호불호 설명
- “Debiasing” and “Casuality”
- Debiasing : 애초에 Recsys는 편향된 모델(특정 유저 대상이기에, 너무나도 당연) → bias: 진짜 좋아하는 것, 유명해서 띄워줬으나 금방 닫는 것 등등을 All 포함
- Casuality → 인과성을 고려하여 우수한 예측을 만들어내는 것
- “Explainability”
- Text based(Multitasking)
- Shallow Model
2. ML for RecSys
⇒ 이번 Part의 핵심은 RecSys을 이해하는 데 필요한 ML 개념 완성
2.1 Overview
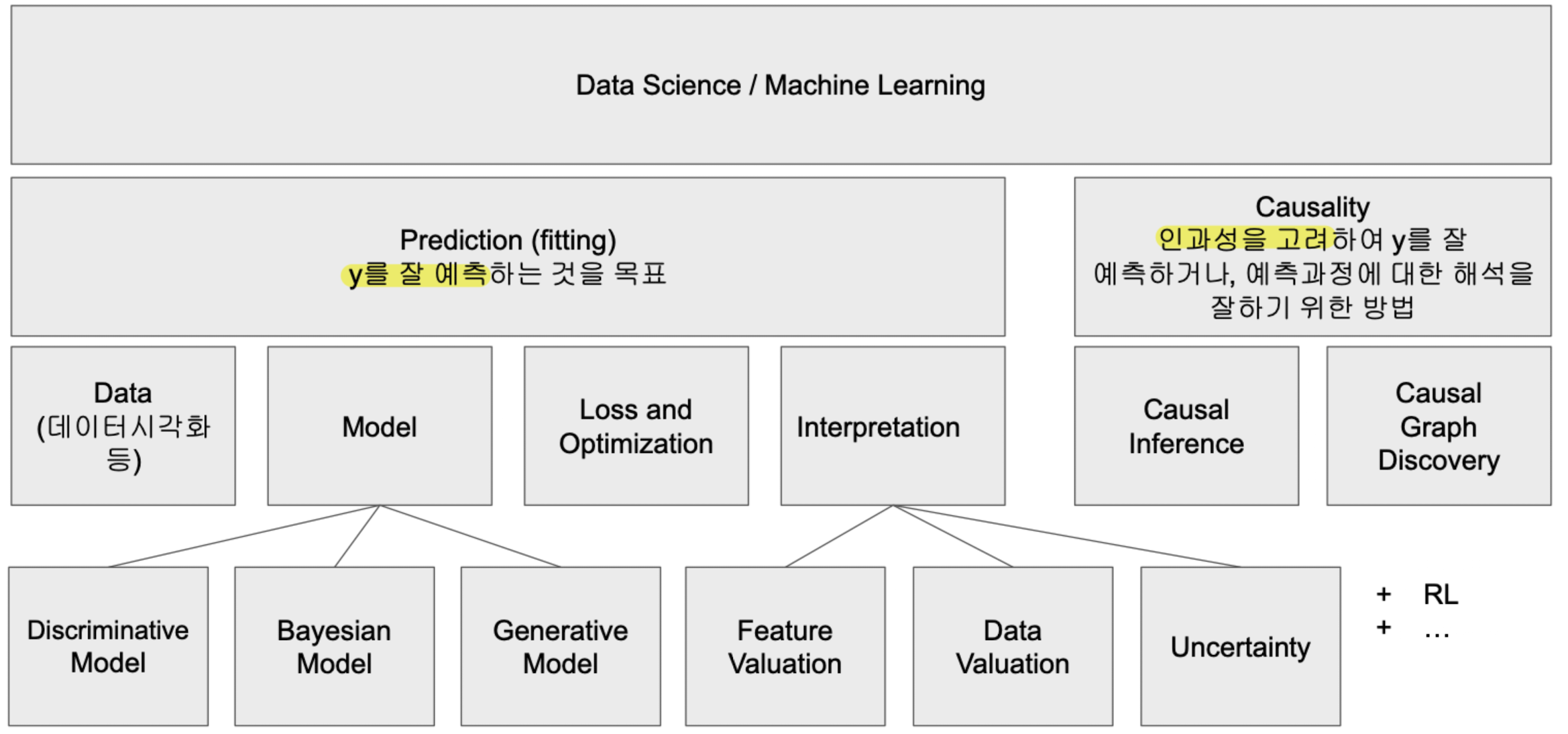
- Recsys 최근 동향
- Generative Model
- Data Valuation
- Casual Inference
- Casual Graph Discovery
- Recsys의 심도있는 이해를 위한 중요 개념(수학, 통계, ML)
- 각종 확률분포(Normal, Beta, Uniform 등)
- 통계학의 개념 및 활용분야
- 생성모델 및 이를 학습하기 위한 추론 기법(Variational Inference, MCMC 등)
- Data Valuation 및 Casuality 개념 이해 및 Python 구현
3. 통계학 기본
3.1 Random Variable
- “확률변수” - 각 사건(확률실험)에 대하여, 발생할 수 있는 결과를 해당 사건을 대표하는 실수값으로 바꾸어 표현한 것
- input: 사건의 집합 S
- output: real-value 하나의 값
- Ex)Random Variable X: 두 개의 주사위를 던져서 나오는 값의 합
- Sample Space: $S = (i, j) : 1 \leq i, j \leq 6$
- Random Variable: $X(i, j) = i + j$ (사건: 주사위 양면의 합)
(좌변: function, 우변: real-value)
3.2 (Probability) Distribution
- Random Variable : 이산적이기도 하고, 연속적이기도 함
- Definition by Discrete(연속확률분포는 수학적으로 더 깊게 들어가야 함)
- 고려해야 하는 가짓수가 한정적일 때
- 각 확률 변수 X에 대해, Sample Space에서 X에 대한 빈도수(확률값)를 불러와 summation
- 모든 X에 대해 y를 정의하여, 공식/표/그래프 등으로 나타낸 것이 확률분포(Probability distribution)
- 이산 확률 분포(Discrete probability distribution)란?
- $0 \leq p(y) \leq 1$, $\sum_y P(y)=1$ 을 만족하는 확률 분포
- $0 \leq p(y) \leq 1$, $\sum_y P(y)=1$ 을 만족하는 확률 분포
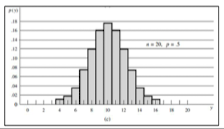
3.3 Binomial & Bernoulli Distribution
- Random Variable의 실행결과가 이진값(0, 1)으로 구성
- n회 시행하였을 때, 결과가 둘 중 하나가 나오는 확률 분포
- 1번 시행 시 0이 나올 확률 - p
- 1번 시행 시 1이 나올 확률 - 1-p
- 실행환경 : i.i.d
- Identical Independent - 동일한 환경에서 독립적으로
- Binomial vs Bernoulli
- Bernoulli : 1 trials
- Binomial : n trial (연속, 독립)
- 관심사 : (일반적으로) 성공횟수, 앞면 나온 횟수
- Formula
- $p(y) = \binom{n}{y} p^y q^{n-y} \quad \text{where } y = 0, 1, \dots, n \text{ and } 0 \leq p \leq 1$
- Discrete PDF - probability mass function
3.4 Uniform Distribution
- 각 실험별 확률이 균등한 분포
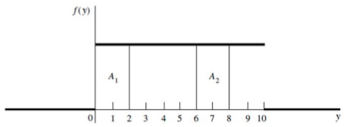
- $f(y) =\begin{cases} \frac{1}{\theta_2 - \theta_1}, & \theta_1 \leq y \leq \theta_2 \ 0, & \text{elsewhere} \end{cases}$
- 엄밀히 정의하기 위해서는, density 개념도 짚고 넘어가야 함
- 위 식의 density : $\frac{1}{\theta_2 - \theta_1}$
- Discrete - probability mass function
3.5 Normal probability distribution
- 정규분포(=가우시안분포, 노멀분포)

- $f(y) = \frac{1}{\sigma \sqrt{2\pi}} e^{-\frac{(y-\mu)^2}{2\sigma^2}}, \quad -\infty < y < \infty$
- $\mu = 0$, $\sigma^2 = 1$
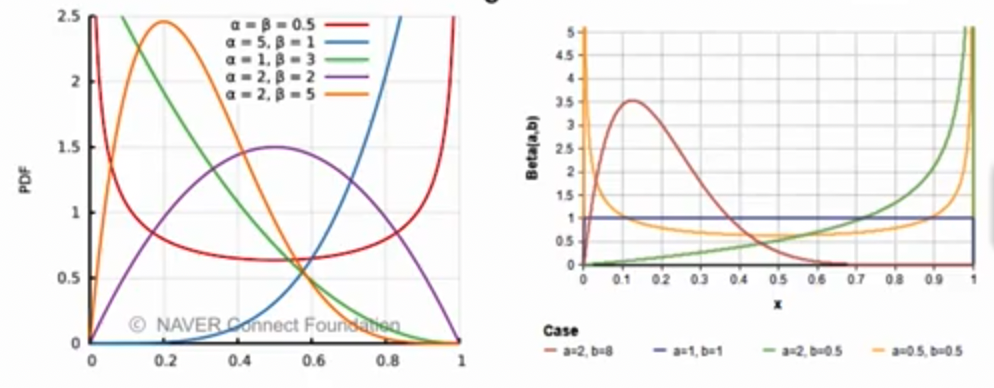
3.6 Beta probability distribution
- 확률변수 $X$가 0과 1사이의 값($0\leq y \leq 1$)을 갖는 연속확률분포
- 0~1의 값을 갖는 모델링 구성에 많이 이용
- 특정한 확률값을 모델링할 때 활용
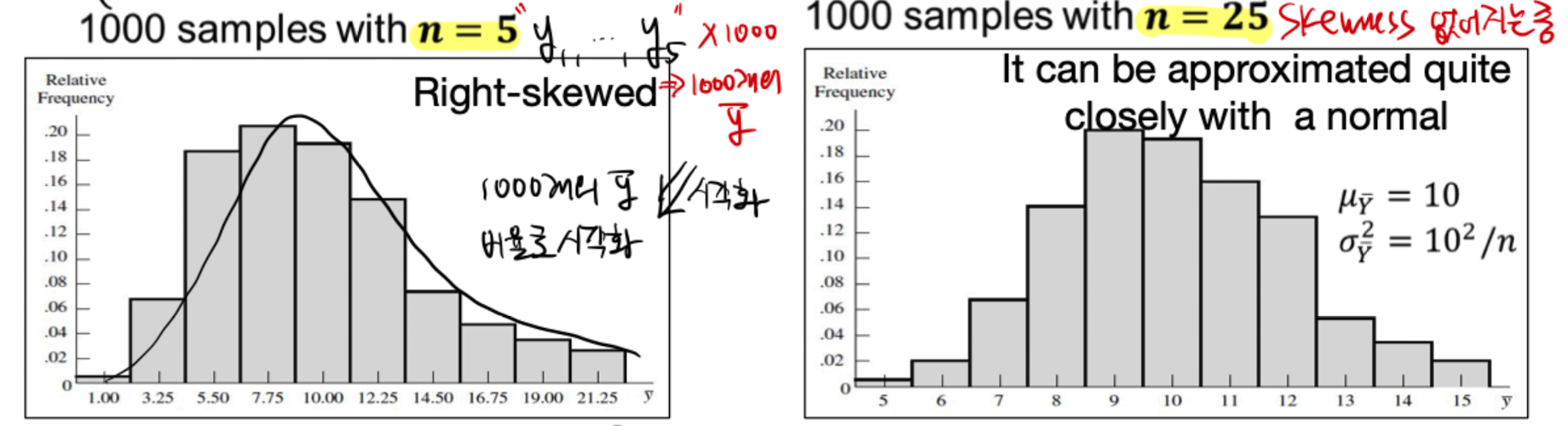
3.7 Central Limit Theorem (중심극한정리) - “$Y$가 아닌 $\bar{Y}$의 분포에 대한 정리”
- $Y$에서 n개씩 추출된 표본 $\bar{Y}$ : 아래 두 가지 조건을 갖추었다면, $\bar{Y}$는 표준정규분포를 따른다고 볼 수 있음.
(skewness가 사라짐)
- 추출하는 표본의 크기 n이 무수히 클 때
- 동일한 환경에서 독립적으로 추출(I.I.d)할 때
- $Y$ : 표본의 크기 n이 커질 수록, 평균 $\mu$ / 분산 $\sigma^2$를 갖는 확률분포 ⇒ $\bar{Y}$ : 평균 $\mu$, 분산은 $\sigma^2 / n$ 인 확률분포로 수렴
- 정규 분포에서 평균 $\mu$와 분산 $\sigma^2$를 가진 표본이 추출되었다면:
- $\bar{Y}$는 정규 분포를 따르며, 기댓값 $E[\bar{Y}] = \mu$이고, 분산 $V[\bar{Y}] = \frac{\sigma^2}{n}$이다. - 어떤 분포에서 추출된 표본이라도 표본 크기가 충분히 크다면:
- $\bar{Y}$는 근사적으로 정규 분포를 따르며, 기댓값 $E[\bar{Y}] = \mu$이고, 분산 $V[\bar{Y}] = \frac{\sigma^2}{n}$이다.
3.8 Likelihood & MLE
- Likelihood(가능도, 우도)
- $n$개의 데이터가 수집 되었을 때, 관측된 $n$개의 데이터가 특정 확률분포를 따를 가능성. 확률과유사하지만 다른 개념
- 확률(Probability) : 이미 확률분포(모수 $\theta$)가 정해진 상태에서, 특정 데이터(관측값 $X$, 주어진 데이터의 집합)가 나올 확률을 계산
- 확률분포가 고정, 관측되는 사건이 변화하는 상황
- $P(X \vert \theta)$
- 가능도(Likelihood) : 이미 데이터(관측값 $X$)가 주어진 상태에서, 이 데이터가 특정 분포(모수 $\theta$)에서 나왔을 “가능성”
- 관측되는 사건이 고정, 확률 분포가 변화하는 상황
- $L(\theta \vert X)$
- 확률(Probability) : 이미 확률분포(모수 $\theta$)가 정해진 상태에서, 특정 데이터(관측값 $X$, 주어진 데이터의 집합)가 나올 확률을 계산
- $L(\theta \vert X) = P(X \vert \theta) = P(x_1\vert\theta) * … * P(x_n\vert\theta) = \prod_{k=1}^{n} P(x_k \vert \theta)$
- 기본 가정 : $x_1, …,x_n$이 독립적으로 모집단 $X$에서 추출(I.I.d)
- $\theta$ : Likelihood에서 최적화 시키고자 하는 파라미터
- 많은 PDF에서 알 수 없는 $\mu$와 $\sigma$에 대해, 데이터가 나올 Likelihood를 가장 잘 설명할 수 있는 $\theta$ → MLE를 통해 그러한 파라미터 $\theta^*$를 찾음
- 즉, n개의 Data를 가장 잘 설명할 수 있는 model parameter를 최대화
- 실제 데이터갯수가 무한대로 뻗어간다면, MLE가 ground truth 값으로 근사
- $\theta$ : Likelihood에서 최적화 시키고자 하는 파라미터
- 표현 : 가끔 순서를 바꾸지 않고 $L(X \vert \theta)$로 표기하기도 함
- 기본 가정 : $x_1, …,x_n$이 독립적으로 모집단 $X$에서 추출(I.I.d)
- $n$개의 데이터가 수집 되었을 때, 관측된 $n$개의 데이터가 특정 확률분포를 따를 가능성. 확률과유사하지만 다른 개념
- MLE(Maximum Likelihood Estimation, 최대우도법 / 최대가능도법, $\theta^*$)
- 관측된 각 데이터가 i.i.d를 만족할 때, Likelihood가 최대가 되도록 하는 확률분포(의 파라미터 $\theta$)를 찾는 것
- $\theta$에 대해 편미분하여 0이 되는 값을 찾아 MLE 찾아냄
- $\theta^* = \text{argmax}{\theta} {\prod{k=1}^{n} P(x_k \vert \theta)}$
- 관측된 데이터를 이용 → 확률 분포의 파라미터를 추정하는 통계적 방법
- 관측된 데이터를 가장 잘 설명하는 분포(모수)를 찾기 위해 “Likelihood function(=$L(\theta \vert X$)”을 최대화 하는 것
- 즉, 관측된 데이터가 가장 그럴듯 하게 나올 수 있는 분포를 찾는 과정
3.9 Prior
- Prior(신뢰도, 사전확률)
- 모수에 대한 사전 지식이나 신뢰도를 확률로 표현한 것
- 전통적인 통계에서는, 확률을 몇 번이 등장하는가”로 보는 Frequentism의 관점으로 봄
- 베이지안 통계에서는, 확률을 “주장에 대한 신뢰도“로 보는 Bayesianism의 관점으로 봄
- 경험에 기반한, 불확실성을 내포하는 수치를 기반으로 함
- Bayesianism의 관점으로 볼 때, Prior는 evidence(새로운 데이터)를 관측하여 갱신하기 전의 주장에 대한 신뢰도
- 쉽게 말하면, Prior는 어떤 주장을 하기 위해 펼치는 가설
- 베이즈 정리(베이지안 통계) : $p(\theta \vert x^{(1)}, \dots, x^{(m)}) = \frac{p(x^{(1)}, \dots, x^{(m)} \vert \theta) p(\theta)}{p(x^{(1)}, \dots, x^{(m)})}$
- Posterior = Likelihood * Prior / Evidence
- $P(H \vert E) = \frac{P(E \vert H) P(H)}{P(E)}$
- Prior(사전확률) : 가설에 대한 확률
- Posterior(사후 확률) : 가설에 대한 확률(Prior)이 evidence(새로운 정보)를 관측하여, 가설에 대해 갱신된 신뢰도(데이터를 given으로 줄 때, $\theta$에 대한 prior가 결합하여 $\theta^*$ 추정)
- Likelihood - 주어진 가설($p(\theta)$)이 참일 때, 데이터가 관측될 확률
- Evidence - 가능한 모든 가설 하에서, 데이터가 관측될 전체 확률
- 앞선 Likelihood는 $\mu$, $\sigma$값을 최적화 시키기 위한 것이었다면, prior는 최적화를 위한 $\mu$, $\sigma$값을 넣어서 값을 확인해보는 과정
- 쉽게 말하면, 확률분포에 관해 사전에 알고 있는 정보를 넣어주는 것(어떤 분포를 따를 것이다, 어떤 범위 안에 있을 것이다 등) → 이를 likelihood와 결합해 주기 위함
- $\mu$, $\sigma$가 어느 값의 범위에 있을 것 같다는 예상을 prior가 제공함 → 값을 넣어봄
- 정확한 posterior를 알 수 없는 경우가 많음 → 이를 위한 Bayesian Inference / M.C.M.C와 같은 방법론 등장
- 모수에 대한 사전 지식이나 신뢰도를 확률로 표현한 것
chat_bubble 댓글남기기
댓글남기기