1. 생성모델 개요
1.1 생성모델 개요
- Training data가 sampling 된 분포에서 같은 분포의 새로운 sample을 생성하는 model
- By Formula
- $P_{\text{data}}(x) \approx P_{\text{model}}(x)$
- $P_{\text{data}}(x, y) \approx P_{\text{model}}(x, y)$
- x : text, image, weighted matrix 등
- y : label
- 목적: 데이터의 분포를 알고 싶음 → 그것이 어렵기 때문에 우리만의 model을 만들어 데이터 분포에 근사하여 파악하고자 하는 것
- By graph
- Captures a hidden or underlying structure of the data
- 아래 그림에서 회색 분포의 추론을 통해, 무지막지한 양의 데이터를 추론할 수 있도록 하는 것
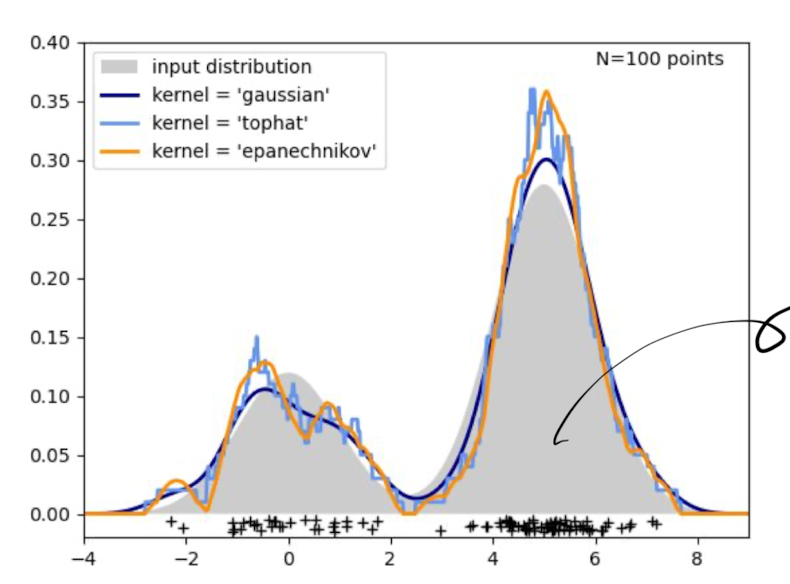
- 아래 검은색 십자부분: Data ⇒ 검은색 십자부분이 생성된 회색분포를 추론하는 것이 생성모델의 목표
- Density Estimation
- Sample Generation

- x 자체가 어떤 분포에서 나왔을지 추론
- 레이블(y)도 같이 추론
- 활용
- CV : 이미지 스타일 변경 / 객체 추가 또는 제거 / 이미지 화질 선명히 복원
- NLP : Text augmentation 제한 시, 생성모델로 새로운 Text 생성 ⇒ 학습 Data 생성
- 아래 그림에서 회색 분포의 추론을 통해, 무지막지한 양의 데이터를 추론할 수 있도록 하는 것
- Captures a hidden or underlying structure of the data
- 생성모델의 패러독스
- 생성모델이 만든 답에 대해, 생성모델이 다른 답을 내놓음
- 마치, $A=B$라 해놓고 같은 질문을 다시 물었을 때 $A \neq B$라고 답하는 격
- 생성모델은 생성은 잘하지만 이해를 못함 → 계속 발전 중
- 생성모델이 만든 답에 대해, 생성모델이 다른 답을 내놓음
- By Formula
2. 그래피컬 모델 개요
2.1 개요
- 생성 모델을 이해하기 위한 그래피컬 모델
- GMM(Gausian Mixture Models)
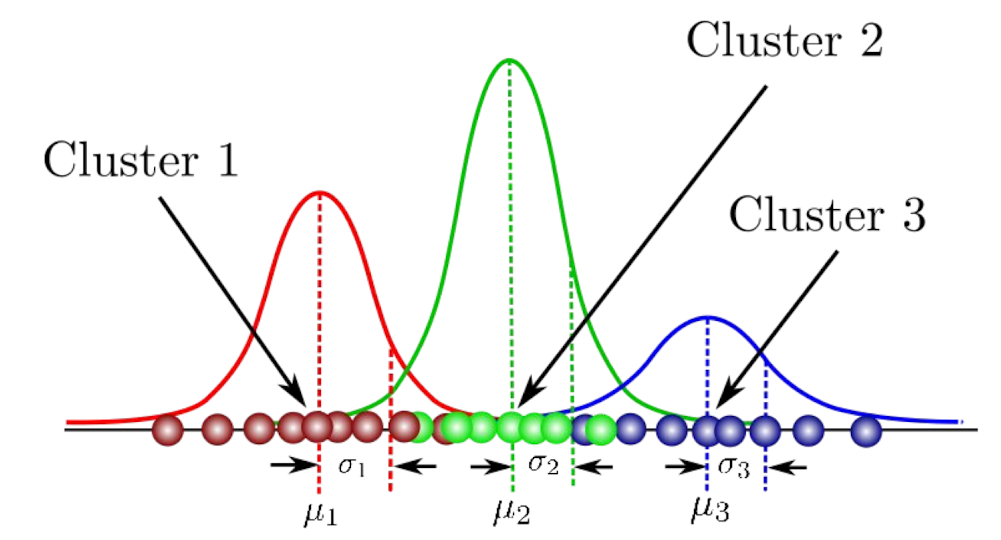
- 각 클러스터에 대한 비중 모델링
- ex)
- Cluster 1 = 0.3
- Cluster 2 = 0.5
- Cluster 3 = 0.2
- GMM 표현
- 수식
- $p(x) = \sum_{i=1}^{K} \pi_i \, N(x \mid \mu_i, \sigma_i)$ - “가우시안 분포가 K개”
- $K$ = 클러스터 갯수
- $\pi_i$ = 분포에 대한 비율
- $N(x \mid \mu_i, \sigma_i)$ = 가우시안 분포
- $p(x) = \sum_{i=1}^{K} \pi_i \, N(x \mid \mu_i, \sigma_i)$ - “가우시안 분포가 K개”
- 그림(plate denote)
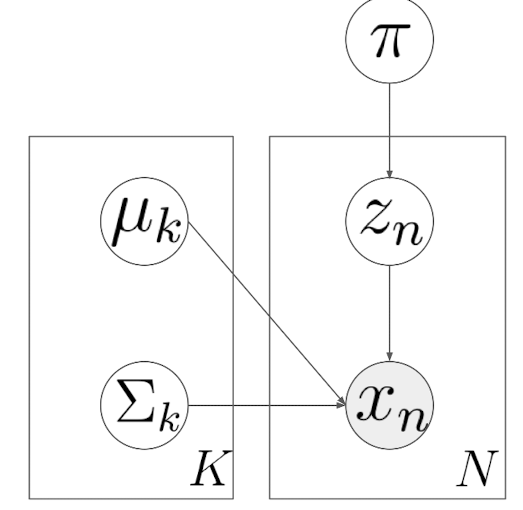
- 우측 K($\mu_k$, $\sum_k$)
- 분포 별 mean, covariance 하나씩
- 좌측 N
- $\pi$
- 매 가우시안 분포 별 비중 (하나만 존재)
- $z_n$
- 임의의 cluster sampling
- $x_n$
- cluster 내 값 sampling
- $\pi$
- 우측 K($\mu_k$, $\sum_k$)
- Generative process
- For each data,
- First, choose
- $z_n$ ~ $\text{Multinominal}(\pi)$ - Cluster Sampling
- Next, choose
- $x_n$~ $Gaussian(\mu_{z_n}\sum_{z_n}$) - 클러스터 별 mean, cov 하나씩 → 이에 대응하는 값 Sampling
- $x_n$~ $Gaussian(\mu_{z_n}\sum_{z_n}$) - 클러스터 별 mean, cov 하나씩 → 이에 대응하는 값 Sampling
- First, choose
- For each data,
- 수식
3. Variational AutoEncoders(VAE)
3.1 VAE 개요
- AutoEncoder
- 목적 - Input을 넣어서 다시 output으로 복원
- $\Vert x-x\prime \Vert^2$을 최소화하는 것이 목표
- 활용
- RecSys에 활용
- 차원축소 알고리즘으로 활용
- Hidden Layer로 차원 축소 시, 중요 정보만 남기고 불필요한 정보는 날림
- 실제 공간보다 관찰대상을 잘 설명할 수 있는 latent space를 알아낼 수 있음 → 이러한 latent space를 알아내는 것이 차원 축소
- 해당 신경망이 압축하는 방식을 배우기 위해 → 비선형적인 차원감소 수행
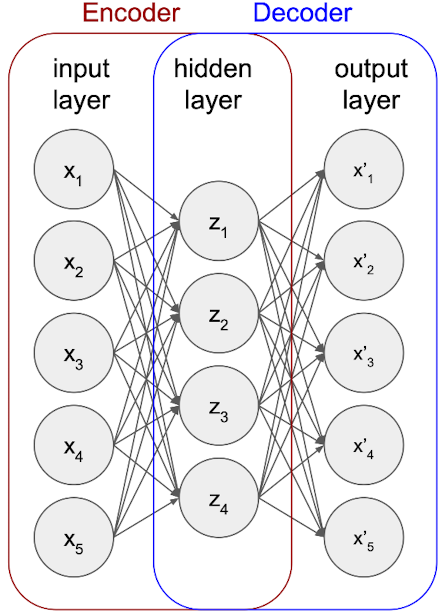
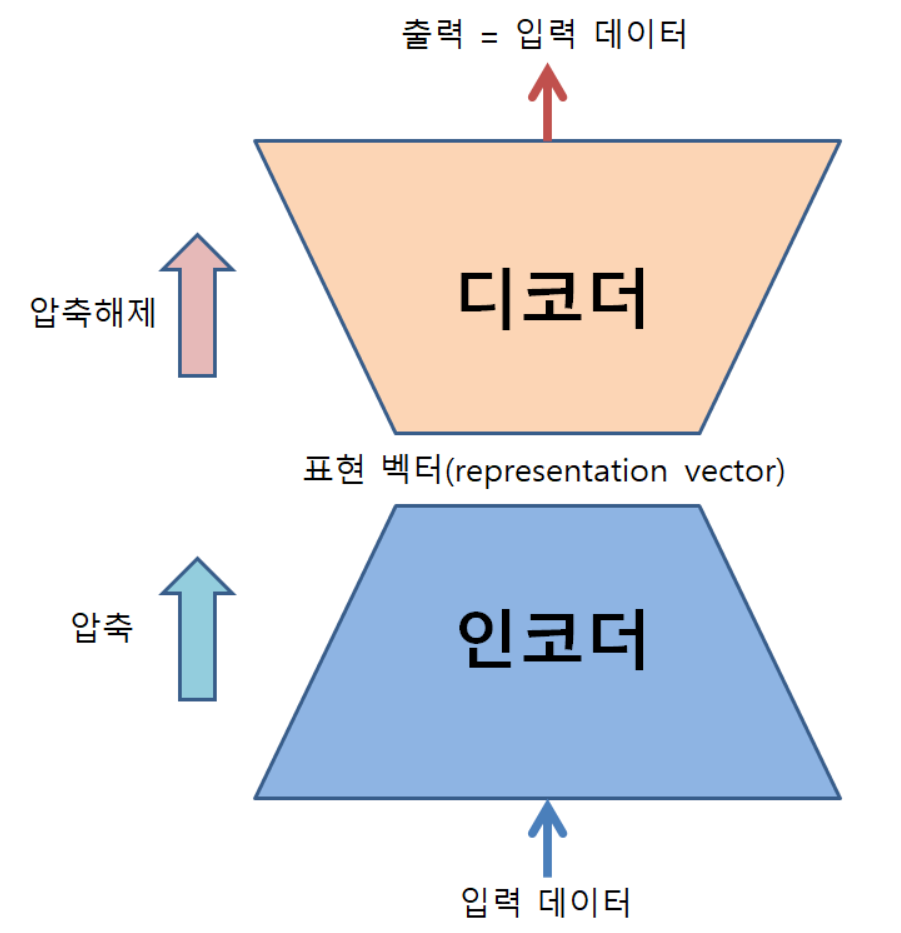
- 구조
- Input
- 입력 데이터를 embedding vector로 변환하여 Encoder에 넣음
- 데이터 전체를 $1 \times x$ 차원으로 평탄화
- Encoder
- embedding vector가 Encoder를 통과하며 차원 축소가 이루어짐
- Encoder는 한 쌍의 선형 변환과 비선형 변환(Hidden layer, $a_1=ReLU(W_1x+b_1)$)을 다중으로 쌓아놓은 형태(일반적으로 3-5층)
- Encoder를 통해 점진적으로 차원을 축소하여 병목층에 이를 전달
- Bottleneck Layer(병목층): Encoder의 마지막 층으로, 최종 차원 축소에 대한 표현을 생성하는 층
- 정보를 압축 : 중요한 특징만을 보존, 불필요한 특징 제거
- 차원 축소(최종) : 인코더의 마지막 층, 입력 데이터를 가장 압축된 형태로 표현
- 정보 병목 현상 유도 : 뉴런 수를 제한하여, 모델이 데이터의 핵심 정보만 보존토록
- 단일 층으로 구성, 인코더 전체에서 가장 적은 뉴런 수 포함
- $\sigma(h = Wz + b)$
- latent space에 표현하는 역할을 담당(latent space와 동일 개념으로 이해 가능)
- embedding vector가 Encoder를 통과하며 차원 축소가 이루어짐
- Latent Space
- Encoder로 압축된 표현은 Latent Space에 표현
- 데이터의 핵심 특징을 포함
- 모델이 학습한 데이터의 내재적 구조를 나타냄
- 특정 수학적 혹은 데이터 표현적 의미를 가질 수 있음
- Decoder로 latent vector 전달
- 일반적인 AE : 추가적 변환 없이 직접 디코더에 전달
- 변형 : 추가적인 정규화 및 변환과정을 거쳐 전달
- Encoder로 압축된 표현은 Latent Space에 표현
- Decoder
- Latent Vector $z$를 받아들여 다시 고차원 데이터로 역변환 수행
- 역변환 과정은 Encoder와 마찬가지로 선형&비선형 변환을 거침.
- 이 과정에서, 압축된 정보가 최대한 보존되기 위하여 Reconstruction Loss를 최소화하는 방향으로 최적화
- Latent Vector $z$를 받아들여 다시 고차원 데이터로 역변환 수행
- Loss Function : “Reconstruction Loss”
- 입력 데이터와 출력 데이터 간 차이
- $\mathcal{L}_{AE} = |x - \hat{x}|^2$
- $|x - \hat{x}|^2$ : Mean Squared Error / Binary Cross Entropy 등으로 계산
- Input
- 기타 : Encoder 및 Decoder의 가중치 관계
- Tied Weights(가중치 공유)
- Decoder 가중치를 Encoder의 Transpose(전치행렬)로 고정
- $W_{dec} = W_{enc}^T$
- 학습 시, Encoder의 가중치만 업데이트 / Decoder는 Encoder와 전치 관계 유지
- Untied Weights(가중치 독립)
- Encoder와 Decoder의 가중치를 독립적으로 초기화
- 현대 딥러닝에서 대체로 선호되는 방식 - “표현력 강화”
- $W_{dec} \neq W_{enc}^T$
- Encoder - $W_{\text{enc}} \gets W_{\text{enc}} - \eta \frac{\partial \mathcal{L}}{\partial W_{\text{enc}}}$
- Decoder - $W_{\text{dec}} \gets W_{\text{dec}} - \eta \frac{\partial \mathcal{L}}{\partial W_{\text{dec}}}$
- Tied Weights(가중치 공유)
- AE 예시 - MNIST 데이터 활용
- 28x28 = 784차원
- 모든 픽셀은 0 or 1 (검 or 흰)
- 파라미터의 갯수는 $2^{784}$ → 비효율 연산
- MNIST 데이터셋은 0-9까지의 숫자를 손글씨로 작성한 이미지 데이터셋 → 크게 10가지로 분류 가능
- AutoEncoder의 차원 축소 알고리즘을 통해 $2^{784}$ → 10차원으로 중요정보만 남기고 차원 축소 to Hidden Layer
- 목적 - Input을 넣어서 다시 output으로 복원
- Variational AutoEncoder
- AutoEncoder에서 확장하여, 확률적인 접근을 추가해 생성 모델의 기능을 수행하기 위해 Variational Inference를 접목시킨 모델
- 목적 - Input Image X를 잘 설명하는 feature 추출, latent vector로 embedding하여 이를 통해 X와 유사하면서 동시에 새로운 데이터를 생성해 내는 것이 목표
- 각 feature는 가우시안 분포 따름
- Latent Vector(Latent Variable)는 각 feature의 평균과 분산을 나타냄
- AE는 Decoder를 통해 입력 데이터가 출력되듯, VAE는 latent vector를 통해 이미지를 생성해냄
- 구조
- Input
- AE와 동일하게, 입력 데이터에 대한 embedding vector를 만들어줌
- Embedding Vector를 “$1 \times x$”의 형태로 평탄화하여 Encoder에 넣어줌
- Encoder
- AE와 동일하게 선형 변환에 비선형성을 추가한 Hidden Layer를 쌓아줌
- 마지막 Layer에서는, 두개의 독립적인 Fully Connected Layer를 사용하여 평균과 로그 분산을 계산
- $μ=W_μh+b_μ$ , $logσ^2=W_σh+b_σ$ ($h$ : 마지막 hidden layer의 출력값)
- 분산의 특성상 항상 양수여야 하며, 이를 보장하기 위한 제약으로서 $log\sigma^2$ 값을 얻게 됨
- 최종적으로, Reparametrization Metric을 통해 latent vector 생성
- VAE는 입력데이터를 latent space로 매핑할 때, 확률적인 분포로 매핑함을 기본적인 핵심으로 함
- 그렇다면 latent vector z는 $z∼N(μ,σ^2)$에서 샘플링
- 하지만 z를 이렇게 샘플링 할 경우, 직접적인 역전파 적용이 불가능함
- 역전파는 확률 분포에서 추출되는 랜덤한 값이 아닌, 정해진 값에 대해 기울기 계산 가능
- 이를 해결하기 위해, 샘플링 과정을 평균, 분산과 노이즈의 조합으로 변환
- $z=μ+σ⊙ϵ$ ⇒ $z = f(\mu, \sigma, \epsilon)$으로 표현되어 역전파 기울기 계산 가능
- $ϵ∼N(0,I)$ : 노이즈는 표준 정규분포에서 샘플링
- 동일한 데이터라도 latent space 내에서 다양한 sample을 추출 가능하게 됨
- 확률적 요소 및 최적화 과정 분리
- 생성 모델로서의 동력
- $\mu$ : 평균값 from Encoder
- $\sigma$ : 표준편차($=exp(\frac{log\sigma^2}{2})$)
- $ϵ∼N(0,I)$ : 노이즈는 표준 정규분포에서 샘플링
- $z=μ+σ⊙ϵ$ ⇒ $z = f(\mu, \sigma, \epsilon)$으로 표현되어 역전파 기울기 계산 가능
- Decoder
- AE와 마찬가지로, 여러 층의 Hidden Layer를 거쳐서 원래 값으로 복원됨
- Loss Function
- VAE의 Loss Function은 Reconstruction Loss와 KL Divergence의 합으로 표현
- Reconstruction Loss
- $\mathcal{L_{recon}}=−E_{q(z∣x)}[logp(x∣z)]$
- p와 q의 전체 분포에 대한 복원능력을 평가하기 위해, 기댓값 개념을 도입하며 모든 latent vector에 대한 복원 능력 평가
- $z \sim q_{\phi}(z\vert x_i)$
- Encoder가 학습한 Latent Space의 확률분포 $q$에서 latent vector $z$를 sampling
- $p_{\theta}(x_i \vert z)$
- sampling한 $z$를 Decoder를 통해 입력 데이터를 복원하는 확률분포
- $\mathcal{L_{recon}}=−E_{q(z∣x)}[logp(x∣z)]$
- KL Divergence
- $\text{KL}(q_{\phi}(z \vert x_i) \Vert p(z))$ → “확률분포 $p$와 $q$가 얼마나 다른지”에 대한 수치
- Reconstruction Loss
- VAE의 Loss Function은 Reconstruction Loss와 KL Divergence의 합으로 표현
- Input
- AutoEncoder의 세 가지 한계점 및 VAE를 통한 보완
- 한계점
- AE는 지금껏 보지 못한 데이터 생성 시 퀄리티 떨어짐
- latent space가 빈 공간일 때 생성된 데이터들은 품질이 떨어짐
- 인코딩 시, 표현 벡터들의 위치를 선택하는 규칙이 없음
- 디코딩 시, 매번 인코더가 어떤 좌표에 데이터들을 옮겨 담았는지 매번 Sampling 해야하는 번거로움
- 고정적인 변환만 이루어짐($z=f(x)$)
- 어떤 class의 데이터들은 매우 작은 영역에 밀집, 어떤 class의 데이터들은 넓은 지역에 퍼져있음
- AE는 지금껏 보지 못한 데이터 생성 시 퀄리티 떨어짐
- 보완책
- 1번 한계점 → Gaussian 분포 이용
- 목적: 벡터 공간 상의 정확한 위치가 아닌, 살짝 벗어난 곳에 점을 찍을 수 있도록 하여 랜덤성 부여)
- 2번 한계점 → KL divergence
- p와 z간 거리가 얼마나 먼지를 KL-Divergence로 표현
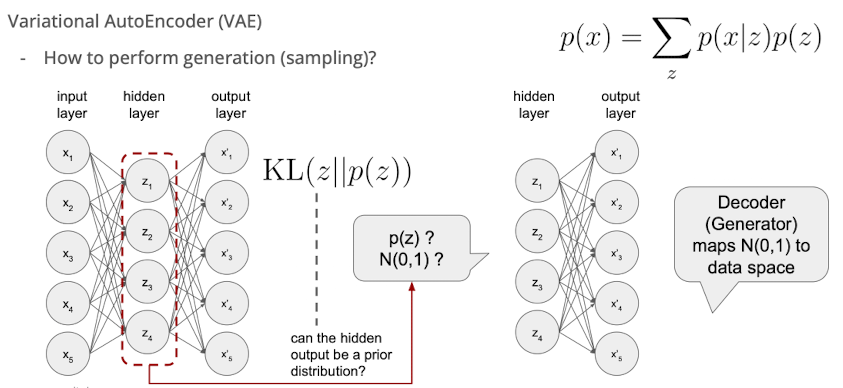
- p와 z간 거리가 얼마나 먼지를 KL-Divergence로 표현
- 1번 한계점 → Gaussian 분포 이용
- 한계점
- 목적 - Input Image X를 잘 설명하는 feature 추출, latent vector로 embedding하여 이를 통해 X와 유사하면서 동시에 새로운 데이터를 생성해 내는 것이 목표
chat_bubble 댓글남기기
댓글남기기