1. Variational Inference (변분추론)
1.1 Variational Inference의 필요성
- Variational Inference → 생성 모델을 학습시키는 대표적인 방법론
- Supervised Learning: $x$ → $y$ 관계성 학습
- Unsupervised Learning: $x$에 내재된 패턴 학습
- 생성모델: “$x$(이미지) or $(x, y)$(이미지, 레이블)는 어떤 분포에서 sampling 되었을까?”
- Model : $p_\theta(x)$ - 어떠한 모델이든(NN, Gaussian Mixture, …) / $\theta$ : parameter
- ex) $N \sim \mu, \sigma^2$
- $\theta$ : $\mu, \sigma$
- $p_{\theta}(x)$ : N($\mu, \sigma^2$)
- ex) $N \sim \mu, \sigma^2$
- Data
- $D = {x_1, … ,x_n}$
- Maximum likelihood
- 표현
- $\theta \leftarrow \arg\max_{\theta} \frac{1}{N} \sum_i \log p_{\theta}(x_i)$
- $\theta \leftarrow \arg\max_{\theta} \frac{1}{N} \sum_i \log \int p_{\theta}(x_i, z)$
- $p_{\theta}(x_i)$ : i번째 데이터를 가장 잘 설명하는 것
- $z$ : 이미 관측된 $x$ 제외한 모든 데이터가 어느 클러스터에서 생성되었는지
- 생성모델 모델링을 위한 변수
- 예시 - 두 개의 Gaussian Mixture 모델이 있다고 할 때,
- $z$(=이미 관측된 $x$ 제외한 모든 데이터) : 어느 클러스터에서 왔는지 결정

- $z$(=이미 관측된 $x$ 제외한 모든 데이터) : 어느 클러스터에서 왔는지 결정
- 의미
- 데이터(검은색 점)를 가장 잘 만들어내는 $\theta$ 추정
(그래프 파란 선, Log Likelihood 최대화)

- 데이터(검은색 점)를 가장 잘 만들어내는 $\theta$ 추정
(그래프 파란 선, Log Likelihood 최대화)
- 표현
- Expected log-likelihood
- 표현
- $\theta \leftarrow \arg\max_{\theta} \frac{1}{N} \sum_i E_{z \sim p(z \vert x_i)}\log p_{\theta}(x_i, z)$
- Maximum Likelihood: $\log \int p_{\theta}(x_i, z)$
- Expected Maximum Likelihood: $E_{z \sim p(z \vert x_i)}\log p_{\theta}(x_i, z)$
- “근사 형태” (Monte Carlos Approximation)
- $\theta \leftarrow \arg\max_{\theta} \frac{1}{N} \sum_i E_{z \sim p(z \vert x_i)}\log p_{\theta}(x_i, z)$
- 의미
- $\log \int p_{\theta}(x_i, z)$
- “Intractable”
- 적분이 복잡해 정확한 계산을 할 수 없는 형태 → 다른 접근법이 필요
- $z$에 대한 적분 대신에,
- $z$를 각각 ==Posterior에서 Sampling== 해온 후, $z$에 넣어 계산(Discrete)
- ==각각 계산해준 값에 대한 기댓값==을 취하여 대신 사용
- $z$는 직접 관측되지 않지만, 데이터 생성에 영향을 미치는 잠재변수
- 영향을 미치는 변수가 하나가 아닐 수 있기에, $z$는 다차원 변수
- $p(x_i, z)$ : 관측 데이터 x와 잠재변수 z의 joint probability(결합확률)
- “Intractable”
- $\log \int p_{\theta}(x_i, z)$
- 표현
- Model : $p_\theta(x)$ - 어떠한 모델이든(NN, Gaussian Mixture, …) / $\theta$ : parameter
- Variational Inference의 필요성
- $z$는 왜 posterior에서 sampling하는가?
- $E_{z \sim p(z \vert x_i)}$ → posterior 확률분포는 어떻게 구함?
1.2 Variational Inference 학습을 위한 기본 개념
- Convex vs Concave
- Convex Function - “아래로 볼록”
- 표현
- 모든 $0 \leq t \leq 1 \text{ , } x_1, x_2 \in X$ 를 만족하는 값에 대해,
- $f(tx_1 + (1-t)x_2) \leq t f(x_1) + (1-t)f(x_2)$을 만족하는 함수
- 수식 의미
- $x \leq y$이고 함수 $f$에 대해, 좌변이 우변보다 작을 경우 $f$는 convex function
- $1-t:t$ 로 내분하는 점에 대한 함숫값이(좌변)
- $f(x)$, $f(y)$ 양 끝점의 함숫값 평균보다(우변)
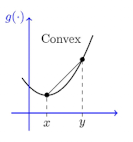
- $x \leq y$이고 함수 $f$에 대해, 좌변이 우변보다 작을 경우 $f$는 convex function
- 표현
- Concave Function - “위로 볼록”
- 표현
- $f:X \rightarrow R$인 함수 $f$에 대해,
- $-f$가 convex function이라면, $f$는 concave function
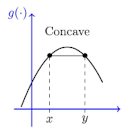
- 표현
- Example
- $f$ → convex ( $x, x^2, e^x$ )
- $-f$ → concave ( $log (x)$ )
- 당연히, 도함수와 이차도함수 부호도 판별 가능
- Convex Function - “아래로 볼록”
- Jansen’s Inequality
- 표현
- $\varphi(E[X]) \leq E[\varphi(X)]$ - $\varphi$ is convex
- $\varphi(E[X]) \geq E[\varphi(X)]$ - $\varphi$ is concave
- 예시
- $\text{Var}(x) = E[x^2] - E[x]^2 \geq 0$ → $E[x]^2 \leq E[x^2]$
- $x^2$ : convex function → Jensen’s Inequality 성립
- $x^2$ : convex function → Jensen’s Inequality 성립
- $\text{Var}(x) = E[x^2] - E[x]^2 \geq 0$ → $E[x]^2 \leq E[x^2]$
- 표현
- KL-divergence
- One of f-divergence (f-divergence의 특정한 형태)
- 쉽게 말하면, 두 확률분포를 비교한 차 by. log ratio
- 정의
- Discrete: $\text{KL}(p(x) \parallel q(x)) = \sum_{x} p(x) \log \frac{p(x)}{q(x)} = - \sum_{x} p(x) \log \frac{q(x)}{p(x)}$
- Contiguous: $\text{KL}(p(x) \parallel q(x)) = \int_{x} p(x) \log \frac{p(x)}{q(x)} dx = - \int_{x} p(x) \log \frac{q(x)}{p(x)} dx$
- Weight주는 것을 앞에 - $p(x)$
- 경향
- $p=q$ ⇒ $\text{KL}$ = 0
- $p$, $q$ 차이 증가 → $\text{KL}$ 증가
- One of f-divergence (f-divergence의 특정한 형태)
- 그렇다면, $\text{KL}$ 을 줄이기 위해 $q$를 어느 곳으로 옮겨야 할까…?
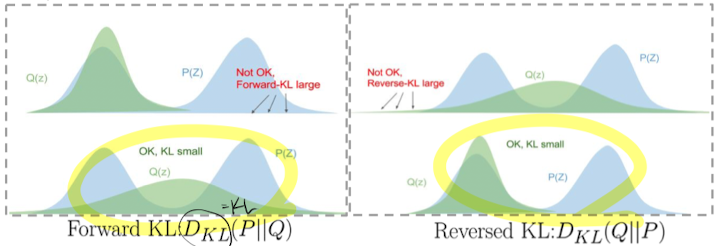
- 좌측 - P에 가중치
- 어떻게든 Q가 P에 걸쳐야
- 우측 - Q에 가중치
- 어느 한쪽 Q가 P를 최대한 덮어줌
- 어느 한쪽 Q가 P를 최대한 덮어줌
- 좌측 - P에 가중치
1.3 Variational Inference
- 목표: 확률분포 $q(z)$를 posterior($p(z \vert x)$)에 근사 (본질적 목표 : q(z)를 posterior에 근사시켜야 $P_\theta(x)$ maximize in expected log-likelihood)
- 유도 by log likelihood
- $\text{log}p(x_i)$ : ==데이터 포인트에 대한 Log Likelihood==
- Integrate에서 Expectation 변환 (Alternative)
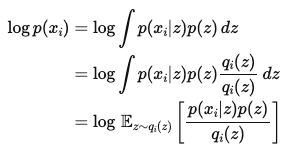
- Integrate에서 Expectation 변환 (Alternative)
- Jansen Inequality 적용
- 기댓값으로 유도한 $\text{log} p(x_i)$에 Jansen Inequality 적용
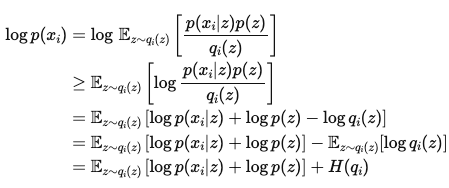
- $H(q_i)$ - Definition of ENTROPY
- 기댓값으로 유도한 $\text{log} p(x_i)$에 Jansen Inequality 적용
- 정리
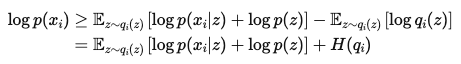
- $\text{log}p(x_i)$ : ==데이터 포인트에 대한 Log Likelihood==
- Interpretation
- $\mathbb{E}_{z \sim q_i(z)} \left[ \log p(x_i \vert z) + \log p(z) \right]$ : $z$를 sampling해서($z \sim q_i(z)$), 다시 $x_i$를 얼마나 잘 설명하는지
- $H(q_i)$ ($=-\mathbb{E}_{z \sim q_i(z)} [\log q_i(z)]$) : Random성 측정 → “얼마나 불확실한지”
-
여기서 핵심 의문점은 아직 남아 있음 : lower bound ↔ posterior 관계
- 유도 by KL-Divergence
- $\text{KL}(q_i(z) \Vert p(z \vert x_i)$)
- $q_i(z$) - Variational Posterior 최적화의 대상 ⇒ KL이 0에 수렴할 수 있도록 ==posterior와 유사==하게 학습 예정
- $p(z \vert x_i)$ - “posterior”
- 유도 상세
- 정리하면 → $\log p(x_i) = L_i(p, q_i) + \mathrm{KL}(q_i(z) \Vert p(z \vert x_i))$
- $\text{KL} \geq 0$ 이므로 → $\log p(x_i) \geq L_i(p, q_i)$
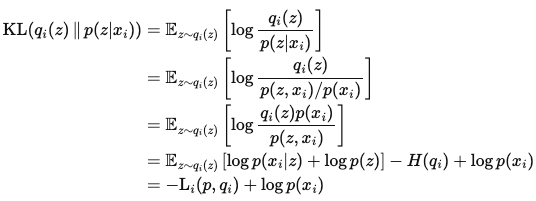
- 정리
- $L_i$ 최대화가 곧 KL 최소화
- 이 식에서 확인해보면, $\log p(x_i) = L_i(p, q_i) + \mathrm{KL}(q_i(z) \Vert p(z \vert x_i))$
- Data의 Log-Likelihood($\log p(x_i)$)는 고정된 상수값임
- 그렇기 때문에, $\text {L}_i(p, q_i)$를 최대화 해주려면, KL-Divergence가 0이 되어야 함
- KL-Divergence가 0이 되기 위해서는, posterior($p(z \vert x_i)$)와 $q_i(z)$가 최대한 유사해져야 함
- $\text{KL}(q_i(z) \Vert p(z \vert x_i)$)
- 결론
- 가장 처음으로 돌아가서, 변분추론을 해야 하는 이유는
- $z$는 왜 posterior에서 sampling하는가?
- $E_{z \sim p(z \vert x_i)}$ → posterior 확률분포는 어떻게 구함?
- 이에 대한 답변을 정리해보면, 다음과 같음
- $\text{KL}(q_i(z) \Vert p(z \vert x_i)$ → ==posterior 근사화는 매우 중요==한 과정
- 궁극의 목표
- $p(z \vert x_i) = q_i(z)$ → 그렇기 때문에, z를 posterior에서 sampling 해야함
- posterior는 직접 구하기 매우 힘들기 때문에, 다음과 같이 ==확률분포 q를 posterior에 근사==시켜서 얻어야 함
- posterior만 잘 추정해도 대부분의 문제 거의 해결
- 이후 posterior에서 sampling해서 나머지 계산
- 궁극의 목표
- $\text{KL}(q_i(z) \Vert p(z \vert x_i)$ → ==posterior 근사화는 매우 중요==한 과정
- 가장 처음으로 돌아가서, 변분추론을 해야 하는 이유는
- 변분추론의 필요성 정리
- 실제 MLE를 구하기 위해서, 그 Lower Bound(ELBO)로 근사하여 확률분포를 추정해야 한다
- 이론
- $\theta \leftarrow \arg\max_{\theta} \frac{1}{N} \sum_{i} \log p_{\theta}(x_i)$
- 실제
- $\theta \leftarrow \arg\max_{\theta} \frac{1}{N} \sum_{i} L_i(p, q_i)$
- 이론
- 문제
- param 갯수가 너무 많아짐(Amortized VI) → 하나당 mean, covariance 2개씩 튀어나옴
- 위 문제는 ==MFVI==를 통해 해결
- 실제 MLE를 구하기 위해서, 그 Lower Bound(ELBO)로 근사하여 확률분포를 추정해야 한다
2. Mean-Field Variational Inference (MFVI)
2.1 MFVI 필요성
- VI를 통해 이루고자 하는 목표 : 확률분포 $q$를 posterior에 근사
- But, 모든 확률분포가 하나의 파라미터만 갖는 것은 아님
- 아래와 같은 상황일 때, 확률분포는 $\alpha, \theta, \eta, \beta, z$ 5개 파라미터를 지님
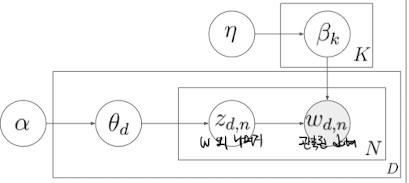
- $q(z)$를 구할 때, ==모든 z에 대한 joint를 독립적으로 고려==해서, 아래와 같이 가정
- $q(z) = \prod_{i=1}^{M} q(z_i)$
- $q(z_1, z_2,…,z_M)$ 대신 $q(z_1) \centerdot q(z_2) \centerdot ,…,\centerdot q(z_M)$
- $M$개의 $q(z)$ 모두 독립이라 가정
- 아래와 같은 상황일 때, 확률분포는 $\alpha, \theta, \eta, \beta, z$ 5개 파라미터를 지님
- MFVI를 ELBO에 적용하여, 근사시켜 구해본다면 아래와 같다
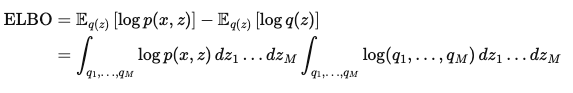
- M개의 q(z)를 모두 독립이라 가정한다면, $q_1, \ldots, q_M$로 표현 가능
- 이를 가정한다면, 각각의 $q$에 대해서만 maximize 해주면 됨
- 서로 연관해서 구할 때보다, 훨씬 간편하게 ELBO 값을 구할 수 있음
- But, 모든 확률분포가 하나의 파라미터만 갖는 것은 아님
chat_bubble 댓글남기기
댓글남기기