1. 현업과 경진대회의 차이점
일단 가장 큰 차이점은, 데이터 수집단계에서 가장 큰 차이가 있다.
당연하게도, 경진대회는 데이터를 제공하고 현업에서는 직접 데이터를 수집해서 가공해야 하기 때문이다.
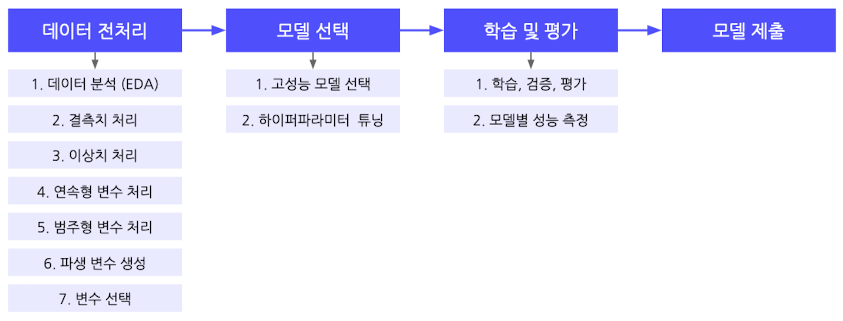
경진대회의 흐름
데이터 전처리 → 모델 선택 → 학습 및 평가 → 모델 제출
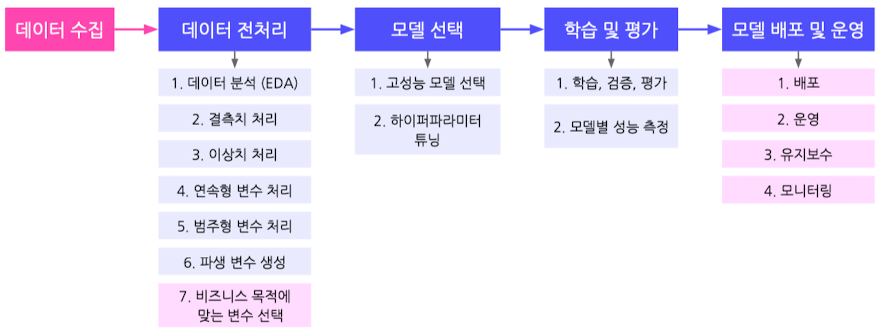
현업의 흐름
==데이터 수집== → 데이터 전처리 → 모델 선택 → 학습 및 평가 → 모델 ==배포 및 운영==
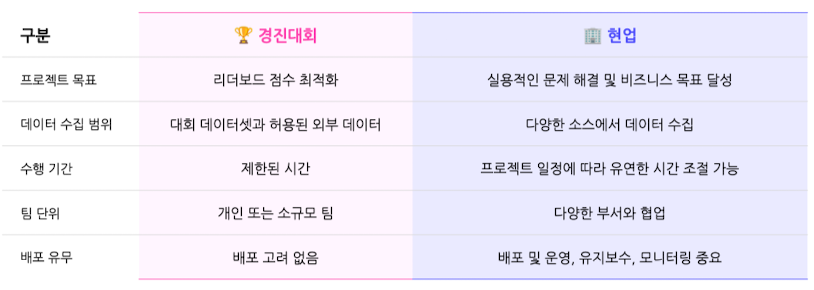
현업 vs 경진대회
수행 목적 / 데이터 수집 범위 / 프로젝트 수행 시간 / 협업 방식 / 모델 배포 유무 등에서 차이
2. ML 경진대회 방법론 기초: Regression
Regression → ML의 기본
- Linear Regression
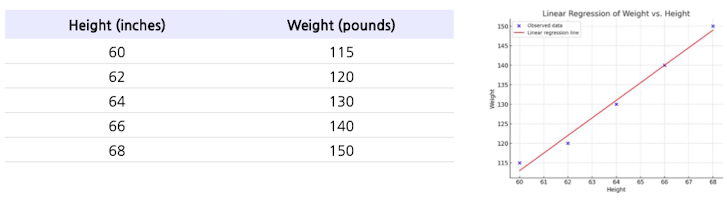
- “종속 변수 - 하나의 독립 변수” 간 관계를 모델링하기 위해, 관측된 데이터에 선형 방정식을 만드는 기법
- ex) 키-몸무계 간 관계를 선형 방정식으로 모델링
- Multiple Regression
- 하나의 종속 변수 예측을 위해 → 두 개 이상의 독립 변수를 사용하는 방법
- Linear Regression 확장
- ex) “직업 만족도” 변수 예측을 위해 Age, Income, Unpaid Work Hours 3개의 독립 변수를 활용하여 모델링
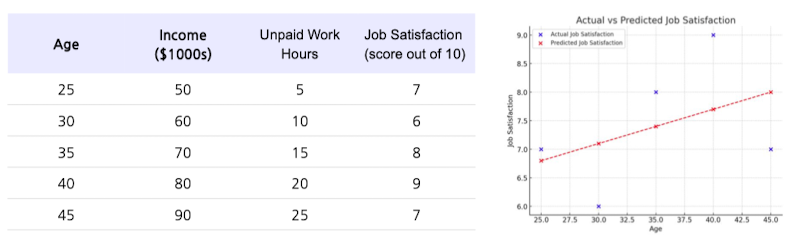
- 기타 Regression 방법론
- Ridge Regression
- Ridge Regression에 ==L2 정규화 항을 추가==한 규제 회귀 방법
- 독립변수들 간 높은 상관관계가 있을 경우 주로 활용
- Lasso Regression
- Linear Regression에 L1 정규화 항을 추가한 규제 회귀 방법
- 독립 변수들 중 중요 변수를 강조하기 위해 주로 활용
- Elastic Regression
- Ridge와 Lasso의 장점을 결합한 정규화 방법
- L1과 L2 정규화를 선형 결합 → 두 방법의 한계 보완
- Regression Through Deep Learning
- MLP(다층 신경망, Multi-Layer Perceptron)를 사용하여 입력과 출력 간의 복잡한 비선형 관계를 모델링하는 방법
- Ridge Regression
Regression 성능 평가 지표
- MSE(평균 제곱 오차)
- ‘실제 값 - 예측 값’ 간 차이를 ==제곱한 값들==의 평균
- RMSE(평균 제곱근 오차)
- $\sqrt{MSE}$
- MAE(평균 절대 오차)
- ‘실제 값 - 예측 값’간 차이의 ==절대값==의 평균
- R-Squared(결정 계수)
- Regression 모델이 실제 데이터의 분산을 설명하는 정도
- Regression 모델이 실제 데이터의 분산을 설명하는 정도
3. ML 경진대회 방법론 기초: Clustering
Clustering → 데이터를 비슷한 데이터끼리 모아주고 / 분류하고 / 시각화하는 방법
대표적인 Clustering 방법론
- K-Means
- cluster 중심에서 거리 기반으로 K개의 클러스터로 분할
- DBSCAN
- 데이터가 밀집해있는 밀도를 기반으로 클러스터 형성
- Hierarchical Methods
- 점진적으로, 작은 그룹을 병합하여 크게 or 큰 그룹을 분할하여 작게 그룹을 형성하는 방법
- GMM
- 가우시안 분포를 혼합하여 데이터를 표현하는 방법
- 가우시안 분포를 혼합하여 데이터를 표현하는 방법
최적의 Cluster 갯수를 찾는 방법
- Elbow Method
- K-Means에서 활용
- K값을 증가시키며, 클러스터 내부의 분산값을 계산하여 최적의 클러스터링 갯수 계산
- Silhouette Method
- Cluster 내부의 응집도 / Cluster 간 분리도를 동시에 고려 → Elbow Method에 비해 더 나은 최적 Cluster 갯수 도출
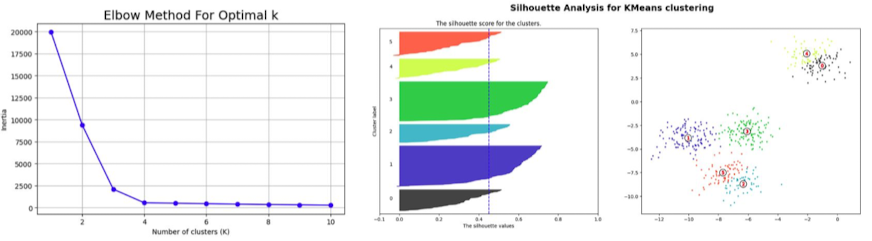
고차원 feature를 저차원으로 변형하는 방법
- Cluster 내부의 응집도 / Cluster 간 분리도를 동시에 고려 → Elbow Method에 비해 더 나은 최적 Cluster 갯수 도출
- PCA(주성분 분석)
- 데이터의 분산을 가장 잘 설명하는 몇 개의 축을 이용해 차원을 축소하는 기법
- t-SNE
- 데이터 포인트들 간 거리를 확률적으로 모델링 → 저차원(아래 예시: 2차원) 공간에서 비슷한 데이터끼리 가까이 위치하도록 만드는 기법
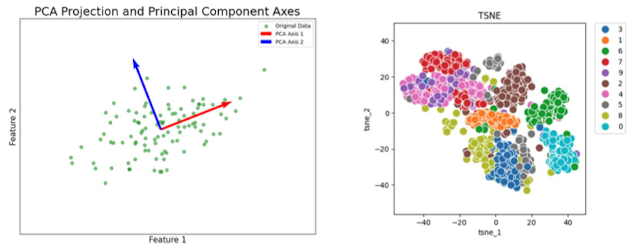
- 데이터 포인트들 간 거리를 확률적으로 모델링 → 저차원(아래 예시: 2차원) 공간에서 비슷한 데이터끼리 가까이 위치하도록 만드는 기법
4. ML 경진대회 방법론 기초: Retrieval
Retrieval → 주어진 입력과 비슷한 데이터 샘플을 DB에서 검색하는 방법론
- ex) 얼굴의 특징을 저차원으로 Embedding 하는 모델 → 이를 활용하여 training set에 없는 인물 검색
- 어떻게? FAISS와 같은 tool을 활용하여 DL Embedding의 Retrieval 수행 기법 학습

- 어떻게? FAISS와 같은 tool을 활용하여 DL Embedding의 Retrieval 수행 기법 학습
5. ML 경진대회 방법론 기초: ML 기반 예측 모델
Basic ML Model
ML 모델의 기본 → Decision Tree / Bagging
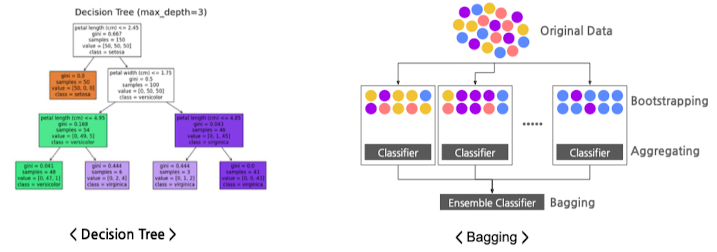
- Decision Tree
- 변수의 값에 따라, 데이터 반복적으로 분할
- Bagging
- Bootstrap을 통해, 여러 데이터의 하위 집합 생성 → 다수결 투표나 평균으로 예측 결합\
- Boosting
- 약한 모델 결합 → 강한 모델 생성
- Gradient Boosting
- Gradient Descent 활용하는 부스팅 기법
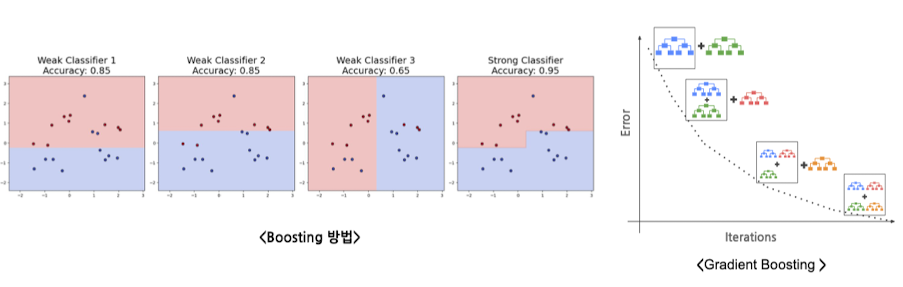
- Gradient Descent 활용하는 부스팅 기법
Tree Model 3대장: 경진대회 상위권 모델
- XGBoost(Since. 2014)
- Regularization / Tree Pruning / 대규모 데이터셋 처리에 적합
- Gradient Boosting 알고리즘
- LightGBM(Since. 2016)
- 기울기가 큰 데이터를 우선적으로 Sampling → 학습 속도 향상
- Gradient Boosting 알고리즘
- CatBoost(Since. 2017)
- 범주형 변수를 효과적으로 처리하는 방법
- Gradient Boosting 알고리즘
6. ML 경진대회 방법론 기초: 시계열을 위한 DL 모델
DL 기반 시계열 모델의 Basic
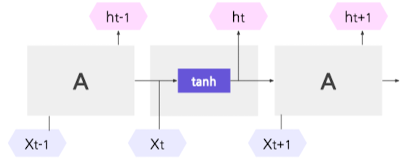
- RNN
- 시간에 따른 의존성 포착을 위해, hidden state 활용
- 데이터를 순서대로 처리 → 시간 종속적 작업에 적합
- 하지만, 긴 Sequence가 이어지는 의존성 학습은 어려움(Gradient 소실 문제 발생)
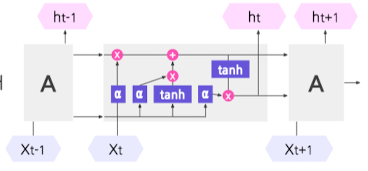
- LSTM
- RNN의 한계(Gradient 소실 문제) 극복 위해 고안
- 긴 Sequence가 이어지는 정보를 저장하고 추출하는게 가능하도록 만들어준 DL 네트워크
- 핵심 아이디어: Input / Forget / Output Gate 활용 → 정보 입출력 제어
Transformer
- Encoder
- 입력 Sequence 변환 → 고차원적 표현 생성
- Decoder
- 고차원적 표현을 기반하여 출력 Sequence 생성
- Self-Attention Mechanism
- 간 Sequence의 종속관계 / 상호작용을 포착 가능한 메커니즘
- Positional Encoding
- 위치 정보 임베딩 → 시계열의 시간 정보 추가 가능
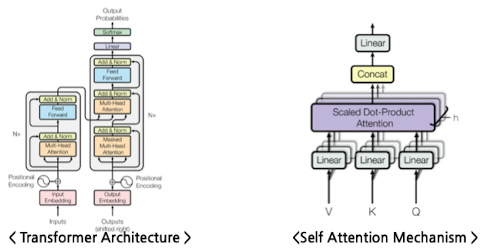
- 위치 정보 임베딩 → 시계열의 시간 정보 추가 가능
chat_bubble 댓글남기기
댓글남기기