1. Clustering Overview
Clustering
- 데이터에서 유사한 특징을 가진 데이터 포인트들을 그룹화하여 의미있는 패턴을 발견하는 기술
- 정답이 주어지지 않은 상황에서, 데이터 자체의 구조를 파악
- ML의 비지도 학습(Unsupervised Learning) 영역에서 중요한 기법 중 하나
- 데이터 단순화
- 데이터의 복잡성을 줄이고, 이를 의미 있는 그룹으로 구조화해줌
- 패턴 인식
- 데이터 노이즈 제거 / 기본적인 구조를 형성시켜 숨겨진 패턴 발견
- 다른 알고리즘을 위한 전처리
- 다른 알고리즘(분류/회귀 등)에 앞서 수행되는 전처리 작업으로서 활용
- 다른 알고리즘(분류/회귀 등)에 앞서 수행되는 전처리 작업으로서 활용
- 데이터 단순화
- 다른 알고리즘을 위한 전처리 example
- 과제: 백화점 고객들을 그룹화해서 분석
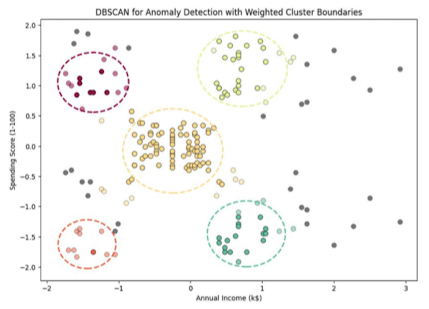
- 연간 수입 및 지출을 기반으로 그룹화
- 가로축: 수입
- 세로축: 지출
- 크게 다섯 그룹으로 구분 / 다섯 그룹으로 구분되지 않는 특수 케이스 존재
- 다섯 그룹안에 속하는 고객 → 데이터 그룹화 및 패턴 분석
- 다섯 그룹에 속하지 않는 특수 케이스 → 이상치
- 이상치에 대해서는 추가적인 Clustering을 수행할 수도
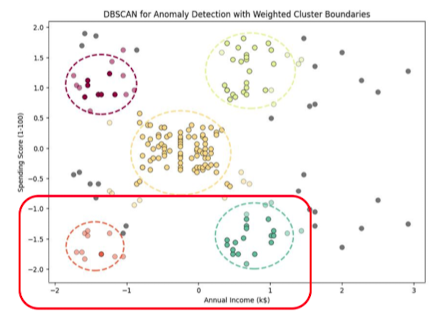
- 연간 수입 및 지출을 기반으로 그룹화
- 선형회귀: 지출은 비슷한데 수입은 다른 그룹을 선형회귀하면?
- 묶어서 선형회귀 → 선형회귀가 잘못된 방향으로 표현됨
- 수입이 적은 그룹은 수입에 따른 지출 증가가 없지만 선형회귀 모델은 수입이 적은 그룹의 지출 증가가 있는 것처럼 표현하게 됨
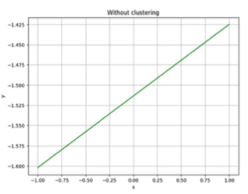
- 수입이 적은 그룹은 수입에 따른 지출 증가가 없지만 선형회귀 모델은 수입이 적은 그룹의 지출 증가가 있는 것처럼 표현하게 됨
- 나눠서 선형회귀 → 선형회귀를 명확한 방향으로 표현할 수 있게 됨
- 수입 많은 그룹의 수입 증가에 따른 지출 증가 / 수입 적은 그룹의 지출 성향은 반대
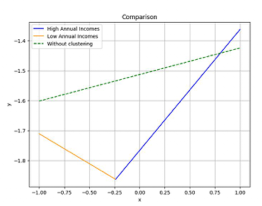
- 수입 많은 그룹의 수입 증가에 따른 지출 증가 / 수입 적은 그룹의 지출 성향은 반대
- 묶어서 선형회귀 → 선형회귀가 잘못된 방향으로 표현됨
- 과제: 백화점 고객들을 그룹화해서 분석
Clustering 방법의 종류
- Partitioning Methods → 데이터를 그룹으로 나누는 방법
- 데이터를 K개의 그룹으로 나누고, 각 그룹의 중심점을 최적화하는 과정 반복
- 알고리즘이 간편 / 계산 속도가 빠름
- 원형 분포 데이터에 적합
- 대표 Partioning Methods: K-Means / (K-medoids)
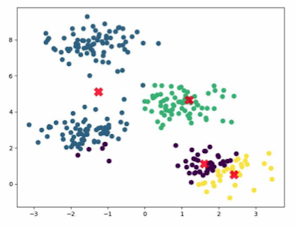
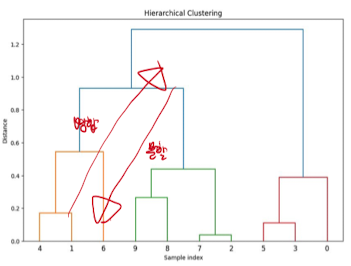
- Hierarchical Methods
- 점진적으로 작은 그룹을 병합 / 큰 그룹을 나누는 알고리즘 → 계층 형성
- 계층적 결과물 형성 / 덴드로그램 사용하여 시각적 표현 가능(주요 활용도)
- 대표 Hierarchical Methods: 병합/분할적 방법
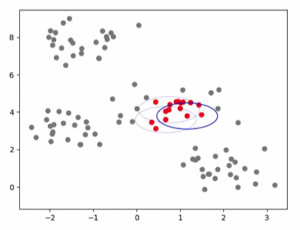
- Density-based Methods
- 데이터 포인트를 밀도에 기반하여 그룹 형성 → 일정 수준으로 밀집한 영역을 그룹으로 간주
- 원형 뿐 아니라, 임의의 모양을 지닌 클러스터를 감지할 수 있음
- 저밀도 지역은 노이즈/이상치 처리 → 노이즈/이상치 처리에 강한 기법
- 클러스터 숫자를 사전에 지정하지 않아도 됨
- 데이터 밀도가 균일치 못하면 성능이 저하될 수 있음
- 대표 Density-based Methods: DBSCAN / OPTICS
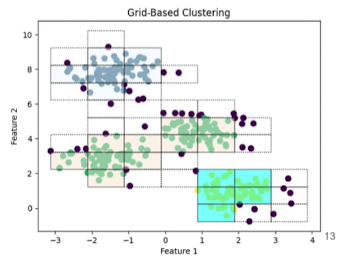
- Grid-based Methods
- 데이터가 분포한 공간을 격자로 나누어, 격자 셀 별로 데이터를 분석하여 그룹을 형성하는 기법
- 격자로 나누어 처리하기 때문에, 속도가 빠름 → 대규모 데이터 세트에 적합
- 계층적 격자 구조를 활용하기에 데이터 공간을 효율적으로 탐색
- 다양한 밀도의 cluster를 효과적으로 식별 가능
- 대표 Grid-based Methods: STING / CLIQUE
- Model-based Methods
- 데이터가 특정 통계 모델을 따른다고 가정한 클러스터링 방법
- GMM: 데이터가 여러 개의 가우시안 분포로 구성되어 있음을 가정
- EM Algorithm: 각 데이터 포인트가 각 가우시안 분포에 속할 확률을 반복적으로 계산
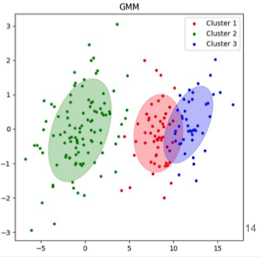
- 확률적 접근: 각 데이터 포인트가 클러스터에 속할 확률 제공
- 유연한 클러스터 형태: 타원형 등 다양한 형태의 클러스터에 효과적
- 혼합 분포 처리: 데이터가 여러 분포의 혼합으로 구성된 경우 유용
- 대표 Model-based Methods: GMM(Gaussian Mixture Models) / EM(Expectation-Maximization)
- 데이터가 특정 통계 모델을 따른다고 가정한 클러스터링 방법
chat_bubble 댓글남기기
댓글남기기