0. K-Means 개요
- ML 비지도 학습의 일종
- 데이터를 K개로 묶는 군집화 알고리즘
- 군집화: 비슷한 특성을 지닌 데이터를 모아놓은 그룹 생성
- 각 군집의 평균을 활용하여 K개의 군집으로 묶음
1. K-Means 알고리즘 단계
- Centroid 초기화
- 데이터 중 random하게 centroids 선택(데이터 포인트 중, 무작위로 K개)
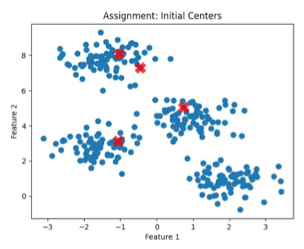
- 데이터 중 random하게 centroids 선택(데이터 포인트 중, 무작위로 K개)
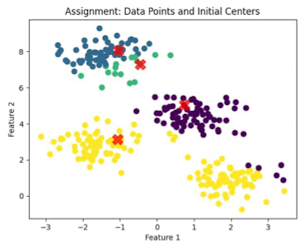
- 클러스터에 할당
- 각 데이터 포인트를 거리가 가장 가까운 centroids에 할당
- Calculate by L2 distance
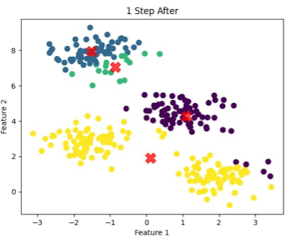
- Centroid 업데이트
- 각 데이터 포인트를 클러스터에 할당하고 나면, 다시 각 클러스터 별 centroid를 계산
- Calculate by center of mass
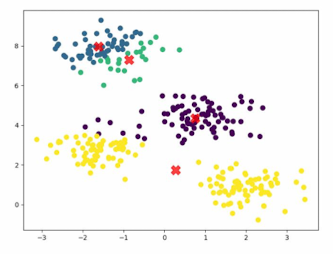
- 반복
- Centroid를 현재 클러스터에 속한 데이터의 평균으로 업데이트 해줌
- 이를, 클러스터 중심이 일정 수준 변화하지 않을 때까지 업데이트(or 정해진 반복 횟수 달성)
2. K-Means 주요 특징
- "직관적" → 거리에 기반하기 때문에, 간단하고 이해가 쉬움
- “범용성” → 대용량 데이터에 빠르게 적용 가능
- 단점
- K(클러스터 숫자)를 미리 지정해야 함
- 최적의 K를 찾는 과정이 꽤나 어려움
- 데이터에 대한 사전 이해도가 요구됨
- Outlier에 민감 → 극단적 값에 쉽게 왜곡(L2 Distance가 큰 값을 갖게 되기 때문)
- Outlier가 존재할 시, 클러스터 중심이 왜곡되어 클러스터 전체가 영향을 받게 됨
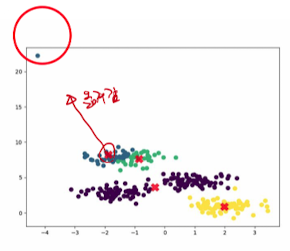
- Outlier가 존재할 시, 클러스터 중심이 왜곡되어 클러스터 전체가 영향을 받게 됨
- Centroid Initialization에 민감
초기에 적절한 Centroid Initialization이 이루어지지 못하면, centroid가 이동을 잘 하지 못함
- K(클러스터 숫자)를 미리 지정해야 함
3. 적절한 K값을 찾기 위한 방법: 엘보우 테스트
- 여러가지 K를 시도해보며, cluster의 centroid와 다른 점들 사이의 거리 제곱의 합이 작은 K값 선택 → 점이 몰려있는 곳에 centroid가 위치해야 거리제곱의 합이 작아지므로
- WCSS 관찰(Cluster 내 오차의 제곱합, Within Cluster Sum of Squares)
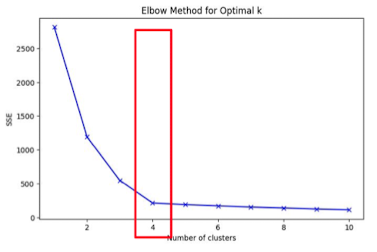
- 실제 K값을 찾을 때는, 최소값보다는 위 그래프처럼 거리 제곱의 합이 급작스레 완만해 지는 곳을 찾음
- 클러스터 내부에 centroid가 하나 더 생겨도, 거리 제곱의 합은 별 차이가 없기 때문
- 클러스터 내부에 centroid가 하나 더 생겨도, 거리 제곱의 합은 별 차이가 없기 때문
4. K-Means++
- 개요
- Initialization 과정에 있어서, K-Means에 비해 개선된 방법
- 결과 및 수렴 속도를 향상시킴
- K-Means의 불확실성은 여전히 존재 (결과, 부적절한 클러스터링, 수렴속도 저하 등)
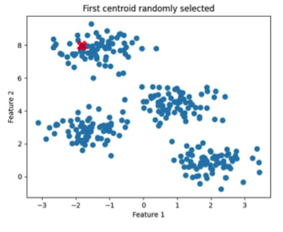
- 개선된 Initialization 방법
- 랜덤하게 첫 번째 centroid 선택(1개만, 아래 그림의 빨간색 점)
- 다음 centroid는, 거리의 제곱에 비례한 확률을 통해 랜덤하게 선택
- $2 + log(k)$번의 시도 중 best(다른 점들과 거리의 제곱합이 제일 작은 경우) 선택
- 아래 노란점: 빨간 centroid와의 거리의 제곱에 비례하여 선택된 점들
- centroid끼리는 거리가 멀수록 좋기 때문에, 거리가 먼 점이 다음 centroid가 될 확률이 높음
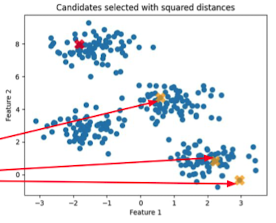
- centroid끼리는 거리가 멀수록 좋기 때문에, 거리가 먼 점이 다음 centroid가 될 확률이 높음
- 이렇게 선택된 다수(위 예시에서는 3개의 노란 점)의 centroid 중 데이터가 모여있는 곳에 있는 점을 선택(아래 예시의 화살표로 가리키는 노란 점)
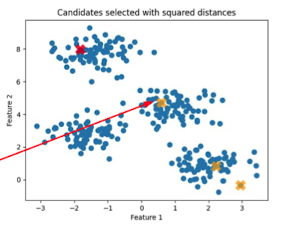
- 위와 같은 centroid 선택 과정을 K개 선택할 때까지 반복
- 이후 클러스터링 과정은 K-Means와 동일
- 랜덤하게 첫 번째 centroid 선택(1개만, 아래 그림의 빨간색 점)
- 초기화 방법 차이에 따른 결과 비교(Random Initialization vs K-Means++ initialization)
- 시간이 더 소모되더라도, Initialization을 더 잘 수행함으로 인해 전체적 성능 및 안정성 향상
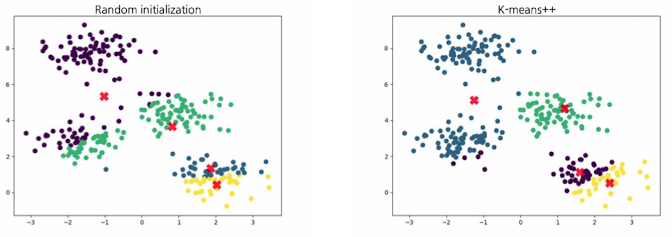
- 시간이 더 소모되더라도, Initialization을 더 잘 수행함으로 인해 전체적 성능 및 안정성 향상
chat_bubble 댓글남기기
댓글남기기