0. DBSCAN 개요
- 데이터의 밀도를 기반으로 Clustering하는 알고리즘
- 데이터의 밀도를 기반으로 클러스터 탐색 / 노이즈 구분
- Unsupervised Learning의 일종
1. DBSCAN의 단계별 동작 원리
- DBSCAN 동작에 기반이 되는 두 매개변수
- $\epsilon$(Epsilon, 반경): 하나의 데이터 포인트를 중심으로, 설정한 거리 내 이웃 포인트 탐색 시 사용
- MinPts(최소 포인트 수): 반경 내 존재해야 하는 최소 데이터 포인트 수(min_points)
- 단계 별 동작 원리
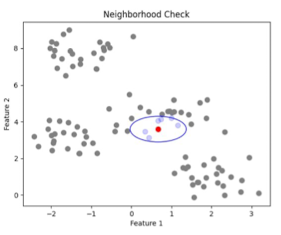
- Random Point 하나 선택 → 해당 Point를 기준으로 $\epsilon$ 이내 포인트 갯수 카운팅
- 아래 그림 ex) eps 거리 내 6(여기서는 min_points)개의 점이 있음 → Cluster로 인정
- 처음에 선택한 Random Point는 “Core Point”(클러스터의 중심)
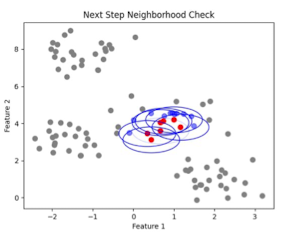
- Core Point 제외한 cluster 내부의 다른 점들로 동일한 과정 진행
- 이 때, 다른 점도 Core Point라면 두 cluster를 합침
- 이 때, 다른 점도 Core Point라면 두 cluster를 합침
- 이렇게 Core Point를 중심으로 연결된 포인트를 계속 묶어나가 클러스터 확장시킴
- 이웃을 전부 확인하고 나면 Cluster 합병 종료
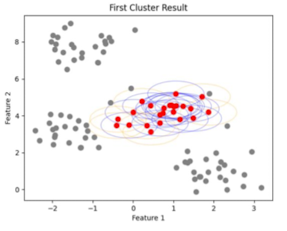
- 이웃을 전부 확인하고 나면 Cluster 합병 종료
- 아직 이웃을 확인하지 않은 다른 점을 찾아 cluster 생성
- 그렇게 모든 점에 대한 진행이 끝나면 알고리즘 종료
- 조건이 맞지 않아 클러스터에 속하지 못하는 포인트는 노이즈로 분류
- Random Point 하나 선택 → 해당 Point를 기준으로 $\epsilon$ 이내 포인트 갯수 카운팅
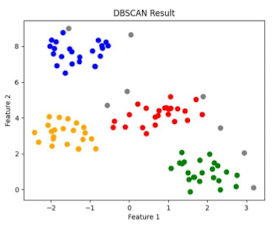
2. DBSCAN 알고리즘의 특징
- 이상치에 강함
- 클러스터 갯수 K에 대한 정보를 파악할 필요가 없음(K-Means와의 차이)
- 임의의 모양의 클러스터도 잘 탐색함
- ex) 왼쪽: 타겟 데이터 / 가운데: DBSCAN으로 clustering한 것(글씨 별 색깔 일정) / 오른쪽: K-Means로 clustering한 것(글씨를 구성하는 색상이 상이함)
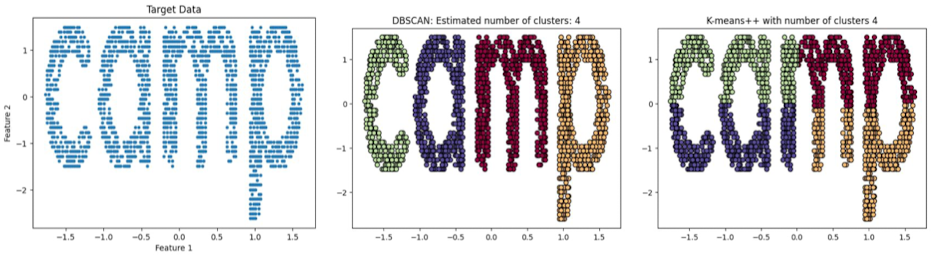
- ex) 왼쪽: 타겟 데이터 / 가운데: DBSCAN으로 clustering한 것(글씨 별 색깔 일정) / 오른쪽: K-Means로 clustering한 것(글씨를 구성하는 색상이 상이함)
- 단점
- 두 하이퍼 파라미터를 찾는 것이 쉽지 않음:
- $\epsilon$
- min_points
- 고차원 데이터에서 잘 작동하지 않음 → 데이터가 희소해져, 거리에 대한 신뢰도가 약해지므로
- 두 하이퍼 파라미터를 찾는 것이 쉽지 않음:
chat_bubble 댓글남기기
댓글남기기