0. GMM 개요
- 데이터가 여러 개의 서로 다른 가우시안 분포에서 왔다고 가정
- 각 분포의 평균, 공분산, 혼합계수 추정
- 각 데이터 포인트가 어떤 클러스터에 속하는지 확률적으로 결정
- 각 분포는 혼합 계수를 통해 가중 → 하나의 분포 생성
- 위 과정을 반복하여, 전체 데이터 중 가장 잘 설명하는 가우시안 분포 조합을 찾음
1. GMM 학습 알고리즘
- "EM Algorithm"
- 초기화
- 처음 초기화하면, 각 정규분포들이 데이터와 잘 안맞는 것을 확인할 수 있음
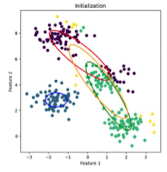
- 처음 초기화하면, 각 정규분포들이 데이터와 잘 안맞는 것을 확인할 수 있음
- Step E(Expectation): 각 데이터 포인트가 특정 가우시안 분포에 포함될 확률(responsibility, 책임도) 계산
- Step M(Maximization): 이전 단계에서 계산한 확률로 각 분포의 새로운 평균 / 공분산(행렬) / 혼합 계수 계산
- 새 평균 / 공분산 행렬을 구할 수록, 데이터에 fit해짐
- 아래 예시의 빨간색 정규분포를 보면, 평균쪽에 점이 많이 모여있는 곳으로 이동
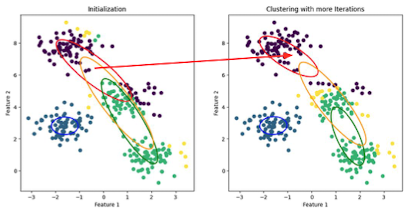
- 초록색 분포도 유사한 움직임을 보임
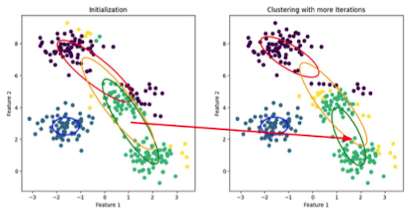
- 2~3의 과정을 수렴할 때까지 반복
- 끝까지 반복하다보면, 아래와 같이 수렴하는 결과를 확인할 수 있음
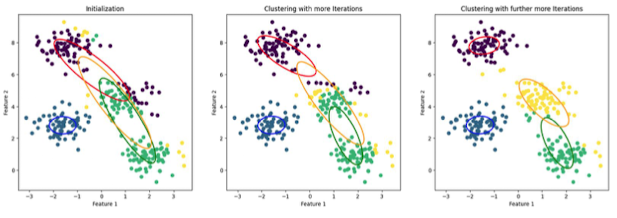
- 끝까지 반복하다보면, 아래와 같이 수렴하는 결과를 확인할 수 있음
- 초기화
2. GMM vs 다른 clustering 알고리즘
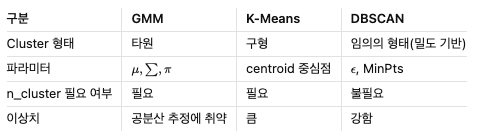
3. GMM 특징
- ‘불확실성’을 다루는 데에 유용
- 확률적 모델이므로, 데이터 포인트가 각 cluster에 속할 확률 계산 → 불확실성 정량화에 유용
- 클러스터의 형태가 다양할 때 효과적(타원형, 중첩 데이터 등)
- 계산: EM Algorithm은 수렴을 보장함 → 대용량에서도 구현 용이
- 단점
- 초기화에 민감
- Local 최적화에 수렴할 가능성도 있음 → 그럴 경우, 여러 번 실행해 주어야 함
- K(num_cluster)를 미리 지정해 두어야 함
- 계산 복잡도 높음 / 데이터가 가우시안 분포와 거리가 멀 경우, 모델 성능 저하될 수 있음
chat_bubble 댓글남기기
댓글남기기