1. 임베딩이란?
- 구성하는 데이터의 의미 있는 구조를 파악하기 위해, 데이터를 저차원 공간으로 변환하는 방법
- 거의 모든 종류의 데이터를 공간 위 점으로 표현 가능 (텍스트, 이미지, 비디오, 사용자, 음악 등)
2. 임베딩 예시
- Word2Vec(Skip-gram)
- 개요
- “단어를 벡터로” 표현하는 기법
- 단어-벡터 간 유의미한 유사도를 반영할 수 있도록, 단어의 의미를 수치화하기 위한 방법
- 주어진 문장의 특정 단어 기준, 주변에 어떤 단어가 있을지 예측하는 방식으로 학습하는 모델
- 비슷한 의미를 지닌 단어는 비슷한 임베딩 벡터 지님 → 공간적으로도 비슷한 공간에 모이게 됨
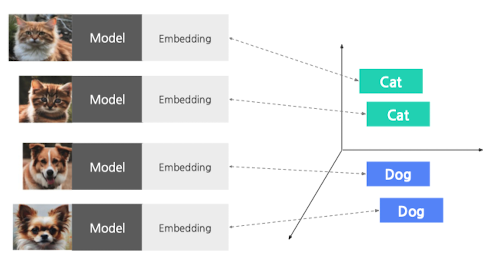
- ex) 비슷한 의미를 지닌 단어(국가, 좌측)끼리 모여있고, 수도(우측)끼리 모여있음
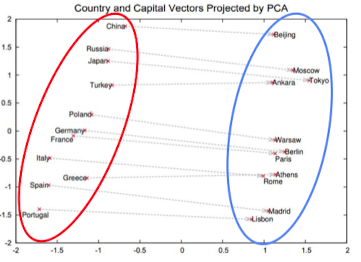
- 비슷한 의미를 지닌 단어는 비슷한 임베딩 벡터 지님 → 공간적으로도 비슷한 공간에 모이게 됨
- 임베딩 과정
- 특정 단어를 의미하는 One-hot 벡터를 입력으로 받아, 단어의 갯수보다 저차원의 공간으로 매핑
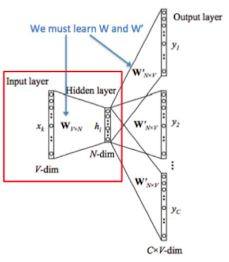
- 특정 단어를 의미하는 One-hot 벡터를 입력으로 받아, 단어의 갯수보다 저차원의 공간으로 매핑
- Word2Vec 임베딩 및 학습 과정(Skip Gram)
- Skip-gram 아키텍처: 문장에서 중심 단어를 입력으로 하여, 주변 단어를 예측
- 슬라이딩 윈도우: 윈도우 크기를 정해, 중심단어 및 주변단어를 추출함
- ex) 슬라이딩 윈도우 크기 3: “The fat cat sat on the mat” → 중심단어: cat, 주변단어: fat, sat
- 각 단어는 입력 측에서 One-hot encoding 벡터로 변환
- 입력층 → Hidden layer
- 해당 벡터를 입력층의 가중치 행렬과 곱해져 임베딩 벡터 생성, Hidden layer 전달
- 이때 생성된 임베딩 벡터는, 단어의 의미를 담은 저차원 벡터로 변환된 벡터
- Hidden layer → 출력층
- Hidden layer의 출력은 출력층의 가중치 행렬과 곱해 주변 단어 확률 계산
- 본래 차원(=원래 단어의 갯수)을 가진 여러 개의 벡터로 변환
- Skip-gram 아키텍처: 문장에서 중심 단어를 입력으로 하여, 주변 단어를 예측
- 개요
- t-SNE
- 개요
- 데이터의 전체 구조보다, 지역적인 구조에 초점을 맞춘 기법
- 고차원 데이터의 군집화에 효과적인 기법
- 임베딩 적용 예시
- 이미지를 모델에 입력해서 얻은 768차원의 bottleneck 임베딩 → 2차원으로 차원축소하여 시각화한 것
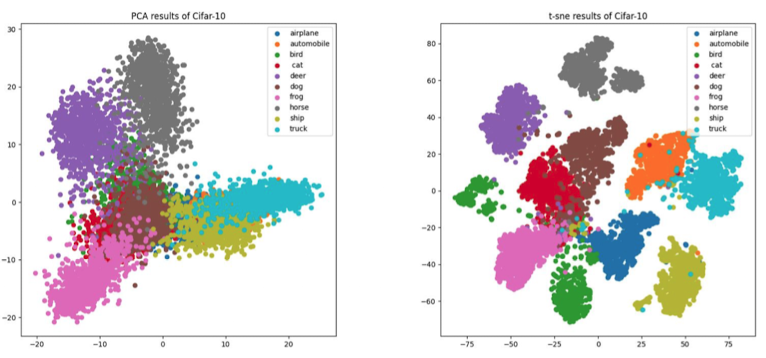
- 이미지를 모델에 입력해서 얻은 768차원의 bottleneck 임베딩 → 2차원으로 차원축소하여 시각화한 것
- 개요
3. 임베딩 활용
- 추천시스템
- 유사성 기반 매칭으로, 임베딩은 사용자와 아이템을 고차원 벡터공간에 배치하여 유사성 계산
- 사용자의 취향 및 아이템 특성을 벡터로 표현 → 아래의 원리에 기반하여 비슷한 사용자와 비슷한 아이템을 찾을 수 있음
- CF(Collaborative Filtering): 사용자-아이템 상호작용 데이터를 행렬 분해 → 사용자 임베딩 및 아이템 임베딩 생성
- 유사도 계산: 같은 벡터 공간 내에 위치한 사용자-아이템 벡터 간 거리 측정하여 선호도 예측
- 개인화: 각 사용자의 임베딩 벡터와 가까운 아이템들을 추천하여 개인화된 결과 제공
- 텍스트 및 이미지 검색
- “검색”에서의 임베딩 → 텍스트/이미지의 의미를 담은 고차원 벡터로 변환
- 비슷한 의미를 지닌 콘텐츠 → 벡터 공간에서 서로 가까운 위치에 배치
- In, Text Retrieval
- 키워드 매칭, 이를 넘어 의미적 유사성을 이해함
- ‘자동차’, ‘승용차’는 다른 단어이지만, 임베딩 공간에서는 가까운 곳에 위치
- BERT, Word2Vec → 단어/문장의 맥락적 의미를 벡터로 인코딩
- 키워드 매칭, 이를 넘어 의미적 유사성을 이해함
- In, Image Retrieval
- 딥러닝 모델이 이미지의 시각적 특성을 벡터로 추출(색상, 모양, 질감 등)
- 픽셀 값을 직접 비교하는 대신, 압축된 벡터 표현끼리 비교하여 효율성을 높임
- 이상 탐지
- 정상 패턴으로부터 편차를 측정하여, 이상치 탐지
- 이상치 탐지에서, 임베딩은 정상 데이터의 분포를 학습해 해당 분포에서 벗어난 데이터를 이상치로 식별
- 정상 데이터들은 임베딩 공간에서 밀집된 클러스터를 형성함
- 새로운 데이터가 정상 클러스터로부터 멀리 떨어져 있으면, 이상치로 분류
- 오토인코더를 활용해,
- 결국, 임베딩이 효과적인 이유
- 고차원 데이터를 의미있는 저차원 벡터로 압축하기 때문
- 동시에, 해당 데이터의 중요한 관계성과 패턴 보존
- 이러한 이유로 인해, 복잡한 데이터 간 유사성을 수치적으로 계산할 수 있다는 점이 임베딩을 활용하는 가장 큰 이유
chat_bubble 댓글남기기
댓글남기기