모델 경량화
개요
- 경량화란?
- AI 모델의 크기를 줄이고 계산 비용을 감소시키며 필요한 모델의 성능을 최대한 유지시켜주는 기술
- 주요 경량화 기법 - 단독 사용 혹은 여러 기법 조합하여 사용하기도
- Pruning
- 가지치기 기법
- 모델 내 불필요한 부분 지워주는 기법
- KD(Knowledge Distillation)
- 마치 “선생님이 가진 지식을 학생에게 알려주듯”
- 고성능의 Teacher 모델로부터 지식을 전달받아 Student 모델이 학습하는 기법
- Quantization
- 모델 내 정보를, 같은 정보를 저장하더라도 더 간단한 형식으로 저장하는 기법
- 저해상도로 저장, 압축하여 저장 등
- Pruning
경량화의 필요성
- 에너지 효율성: 모델 경량화를 통해, 모델에 필요한 전력 양을 절약할 수 있음
- 실시간 처리: 데이터에 반응한, 즉각적인 결정이나 예측이 중요한 분야에서는 경량화된 모델이 필요함
- 자율 주행 자동차, 금융 거래, 헬스케어 시스템 등
- 저자원 환경: 온디바이스 모델에 탑재하기 위해서는 모델 경량화 및 추론 가속화 기술이 필요
- 소형 IOT 장치, 모바일 AI 모델
Pruning
개요
-
AI 신경망 모델에서, 노드(뉴런) 혹은 연결(시냅스)을 제거 → 모델의 크기 및 계산 비용 절감을 도모하는 기법
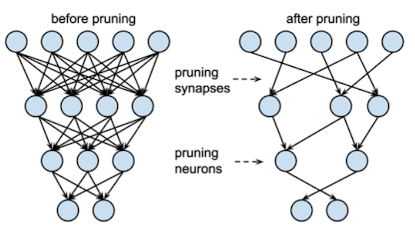
-
Pruning의 개략적 과정

- 초기 모델
- 제거 가능한 파라미터 판별 →Pruning 대상 식별
- 2번 과정에서 판별한 파라미터 제거(Prune)
- 해당 과정 이후, 성능은 매우 급감할 수 밖에 없음 → 성능 감소폭을 최소한으로 막아주는 것이 기본
- 최종 모델
- 기존 모델에서, 각 파라미터는 서로 의존적인 형태였음
- 그렇기 때문에, 이를 fine-tuning을 통해 남아있는 파라미터의 값을 조정해 줌
- 모델 평가
- 아래와 같은 평가 기준을 바탕으로 모델 평가
- Pruning의 목표 달성치 평가
- 성능 목표 달성치 평가
- 아래와 같은 평가 기준을 바탕으로 모델 평가
- Pruning의 대상 및 목표
- Pruning 대상
- “파라미터” → 갯수 최소화
- Pruning 목표
- 메모리 사용량 감소
-
메모리의 대부분은 파라미터, 메모리는 에너지를 많이 잡아먹음
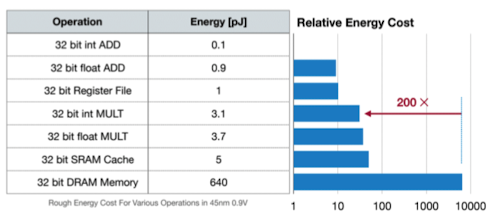
- 메모리 저장 및 유지에 사용되는 에너지(32bit DRAM Memory - 640pJ)가 압도적으로 높다는 것을 알 수 있음
-
- 연산 속도 가속화
- 메모리 사용량 감소
- Pruning 대상
- Pruning 예시
- 단순 신경망 모델 : $y = a_1x_1 + a_2x_2 + a_3x_3 + a_4x_4$
-
weight: $a = [18, -10, 0.01, 5]$
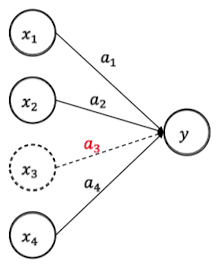
- Input $x = [1, 2, 3, 4]$
- $y = 18.03$
- Input $x = [1, 2, -20, 4]$ → weight $a_3 = 0.01$ 제거
- $y = 17.8$
- Input $x = [1, 2, 3, -20]$ → weight $a_4 = 5$ 제거
- $y = 101.97$
- Input $x = [1, 2, 3, 4]$
-
위의 2, 3번 결과에서 볼 수 있듯, 세 번째 뉴런 혹은 시냅스는 제거해도 전체값이 크게 바뀌지 않음
- $x_3, a_3$ 제거: 18.03 → 17.8
- $x_4, a_4$ 제거: 18.03 → 101.97
-
- 단순 신경망 모델 : $y = a_1x_1 + a_2x_2 + a_3x_3 + a_4x_4$
Pruning의 효과
- 기본적으로, 신경망 모델에서 절약 가능한 것은 모두 절약하며 성능을 최대한 유지하는 것이 가장 큰 목표
- 효과
- 모델 연산량 감소 → 시간 절약
- 메모리 사용량 감소 → 공간(메모리) 절약
- 전체적인 에너지 절약과 함께, 성능을 최대한 유지(보통 경량화 정도와 성능은 반비례-당연)
- 유명 모델로 알아본, Pruning의 메모리 절약 예시
-
CNN 기반 RNN 모델
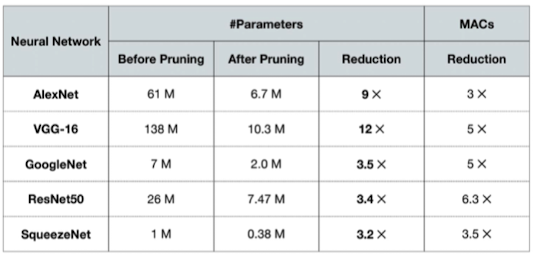
- Pruning을 통해, 적은 것은 3.2배 부터(SqueezeNet) 많은 것은 12배까지(VGG-16) 파라미터 절약
- 연산량(MACs) 또한 3배부터 많게는 6.3배까지 감소함
-
이미지 captioning 모델 예시

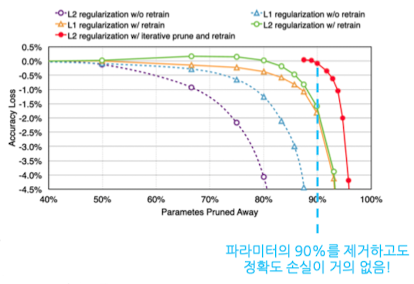
- 앞선 세가지 예시처럼, 파라미터 갯수를 90% Pruning한 모델이 생성하는 이미지는 Baseline 모델에서 생성한 이미지와 비교해도 생성하는 이미지 품질이 큰 차이가 없음
- 하지만, 95% Pruning한 모델이 생성하는 이미지는 Baseline 모델에 비교해서 생성하는 이미지에 문제가 발생하기 시작함 → 한 축구경기에서 뛰는 선수들의 유니폼 색깔이 3가지임(불가능)
-
아래 그래프에서 확인해볼 수 있듯, 파라미터를 90% 제거한 수준에서는 정확도 손실이 거의 없는 것에 반해, 95% 제거한 모델은 정확도가 급락하는 모습을 볼 수 있음
-
Lottery Ticket Hypothesis
- 신경망 모델에서, 일부분을 적절히 선별해서 가져오면 원래 모델과 유사한 양의 학습만으로도 동일한 효과를 얻을 수 있다는 가설
- eyeclear 학회서 우수상 수상
- 성공적인 Pruning이 가능하다는 가설 → 몇몇 유명한 데이터셋을 통해 Lottery Ticket 가설이 가능하다는 것을 실험적으로 증명
- 여기서 당첨복권은 “일부분을 적절히 선별해서 가져오면 원래 모델과 유사한 양의 학습만으로도 동일한 효과를 얻을 수 있는 모델의 일부분”을 의미
- 당첨 복권을 “winning ticket”이라고도 함
-
Lottery Ticket Hypothesis 수행 절차
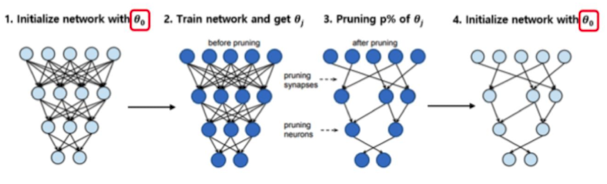
- 무작위 초기 가중치 설정 → $\theta_0$
- 해당 초기값을 저장하여, 나중에 winning ticket를 만들 때 그대로 다시 쓰기 위함이 목표
- 한 번 충분히 학습
- 평소처럼 학습을 진행하여 얻어진 가중치 $\theta_j$ 획득
- 단순히, 원본 모델을 제대로 학습하여 성능이 잘 나오도록 만든 상태
- 전체 파라미터의 p% 가량 pruning 진행
- 현재 가중치 $\theta_j$ → 영향이 적은 파라미터(절댓값이 작은 것들)를 p% 가량 0으로 만듦
- 마스크 씌움
- “0으로 만듦 / 0으로 안만듦” 파라미터를 구분하여 마스크를 씌워줌
- p% pruning 이후, 남은 부분에 대해 초기 파라미터 $\theta_0$로 되돌려 재학습 진행
- “pruning된 작은 네트워크”구조(3번 과정에서 생성된 네트워크 구조)는 그대로 둔 채, 그 안의 가중치 값만 처음 랜덤 초기값으로 리셋시켜주는 과정
- 이렇게 만들어진 “마스크 + 초기값” 조합으로 만든 모델이 winning ticket 후보 → 처음부터 다시 학습
- 이렇게 얻은 작은 네트워크를 다시 학습시킬 때, 기존의 큰 네트워크를 학습하였을 때에 비해 거의 비슷하거나 가끔은 더 좋은 성능을 낸다는 것이 해당 가설의 핵심 포인트
- 즉, 4번 과정의 모델을 재학습한 것이 2번 과정의 모델을 재학습한 것보다 성능차이가 거의 안난다는 것이 핵심
- 무작위 초기 가중치 설정 → $\theta_0$
메서드에 따른 Pruning 기법 분류
Structure: pruning 단위에 따른 분류
- Pruning 단위의 세분화 정도(pruning 단위의 크기)에 따른 분류
- 크게 두 가지로 분류
- Unstructured Pruning - 작은 pruning 단위
- Pruning 단위: 파라미터 하나하나가 pruning 대상 단위 → 값을 0으로 변경
- 각 파라미터를 개별로 제거하기 때문에, 모델 구조의 변경이 없음
- 장점: 쉬운 구현
- 단점: 가속 실현이 어려움
- Structured Pruning - 큰 pruning 단위
- Pruning 단위: 특정 구조 단위(레이어 단위, 채널 단위 등) → 통째로 제거
- 구조 단위로 pruning하기 때문에, 모델 구조는 당연히 변경이 있음
- 장점: 가속 실현이 쉬움(즉시 가속 가능)
- 단점: 구현이 어려운 경우 다수(불가능한 경우도 있음)
- Unstructured Pruning - 작은 pruning 단위
Scoring: pruning 할 파라미터 선정 방법에 따른 분류
- 덜 중요한 파라미터/레이어가 pruning의 우선 대상
- 파라미터/레이어의 중요도를 계산하는 방법
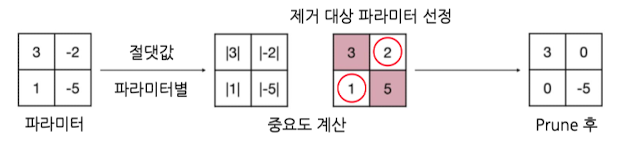
- 파라미터: 파라미터 별 절댓값 사용
-
절댓값이 작은 순으로 pruning 대상 선정
-
- 레이어: 레이어 별 $L^p$-norm 사용
- Definition of $L^p$-norm: $(\left\vert x_1 \right\vert^p + \left\vert x_2 \right\vert^p + \cdots + \left\vert x_n \right\vert^p)^{1/p}$
- 벡터나 함수의 크기를 측정하는 수학적 도구
- $L^1$-norm: 맨해튼 거리 → 각 성분의 절댓값을 단순 합산
- $L^2$-norm: 유클리드 거리 → 거리 측정
- $L^{\infty}$-norm: 벡터 성분 중 최대 절댓값
-
중요도 선정 → “$L^2$-norm”이 작은 순으로 pruning 순서 결정

- Definition of $L^p$-norm: $(\left\vert x_1 \right\vert^p + \left\vert x_2 \right\vert^p + \cdots + \left\vert x_n \right\vert^p)^{1/p}$
- 파라미터: 파라미터 별 절댓값 사용
- 계산한 중요도를 반영할 단위
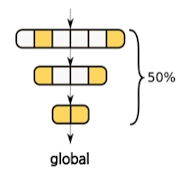
- Global Pruning
- 모델 전체에서 pruning
- 중요도를, 전체에서 절대적으로 비교
-
중요한 레이어가 잘 보존되나, 계산량이 많음(전체를 놓고 비교하기 때문)
-
ex) 파라미터의 50%를 pruning 하는 경우
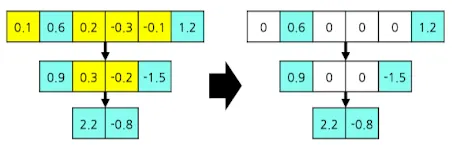
- 전체에서 중요도 기준
- 절댓값 기준, 하위 50%를 pruning
- Local Pruning
- 특정 단위별로(레이어 등) 각각을 pruning
- 중요도를 단위 내에서만 상대 비교
-
특정 레이어에 pruning이 편중되지 않지만, 중요한 레이어가 필요 이상으로 과하게 pruning될 수 있음 → 치명적인 성능 저하
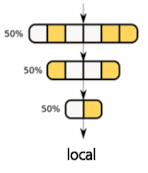
-
ex) 파라미터의 50%를 pruning 하는 경우
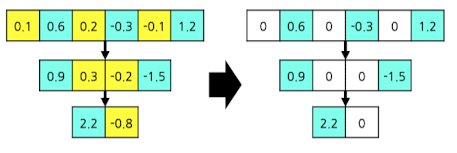
- 레이어 별 중요도 기준
- 레이어 별 하위 50%를 pruning
- Global Pruning
Scheduling: Pruning을 언제, 얼마나 할 것인지에 따른 분류
- Pruning 및 fine-tuning을 언제, 얼마나 할 것인지 설정에 따른 분류
- Pruning 및 fine-tuning의 스케쥴 및 정도 설정
- Scheduling에 따른 방법 분류
- One-shot
- Single Iteration
- Pruning을 한 번만 진행
- Recursive
- Pruning을 한번에 많이 하면, 성능 손실이 클 수 있음
- Pruning을 조금씩 여러번에 나눠 진행
- One-shot
-
One shot vs Recursive

- ex) 같은 pruning이라도,
- One shot: 30% pruning을 1회 진행
- Recursive: 10% pruning을 3회 진행
-
그래프를 통한 성능 비교
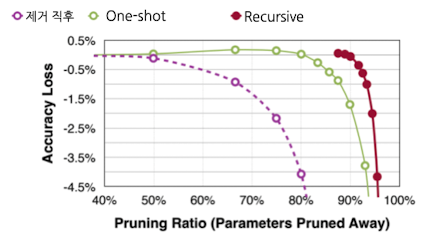
- Accuracy loss를 0%로 유지하면서도
- One-shot으로 pruning을 할 경우 80%는 pruning 가능
- Recursive로 pruning할 경우, 90%까지 pruning 가능
- Accuracy loss를 0%로 유지하면서도
- ex) 같은 pruning이라도,
Initialization: Fine-tuning시, 파라미터 초기화 방법에 따른 분류
- Pruning 직후에는, 학습된 모델 파라미터 중 일부만 잘려나간 상태임 → 이 이후, 최종 모델까지 추가 학습을 어떤 파라미터 값으로 시작할 지에 대한 구분
- 크게 두 가지 방법
- Weight-preserving(classic)
- Pruning 직후 상태 그대로 이어 fine-tuning 진행
-
학습 및 이후 수렴과정이 빠르지만, 성능이 불안정함(Global Minimum을 못찾고, Local Minimum에 빠짐)
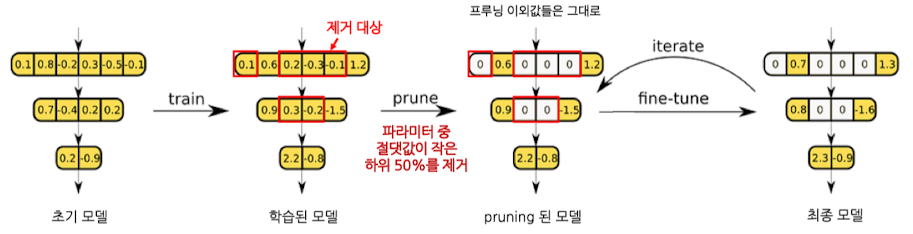
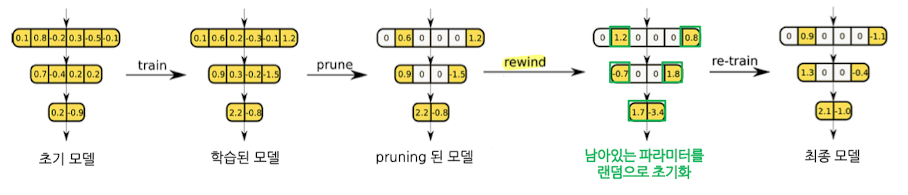
- Weight-reinitializing(rewinding)
- Pruning 이후, 랜덤 값으로 재초기화 후 재학습 진행
-
성능이 안정적이지만, 재학습이 필요하다는 단점이 있음.
- Weight-preserving(classic)
실제 Pruning 과정 예시
Iterative Magnitude Pruning(IMP)
- 가중치 절댓값을 기준으로, 조금씩 반복해서 잘라내고 다시 학습시키는 Pruning 기법
- 전형적인 Iterative Pruning 기법
- 활용 메서드
- Structured
- Unstructured pruning
- Scoring
- 파라미터 별 절댓값을 중요도로
- Global Pruning
- Scheduling
- Recursive
- Initialization
- Rewind
- Structured
- Pruning 과정
- 초기 모델 학습(Unstructured - 개별 파라미터에 대해 pruning)
-
(Scoring) 사용자가 지정한, 절댓값이 작은 일정 비율의 하위 파라미터를 전역에서 설정 및 제거
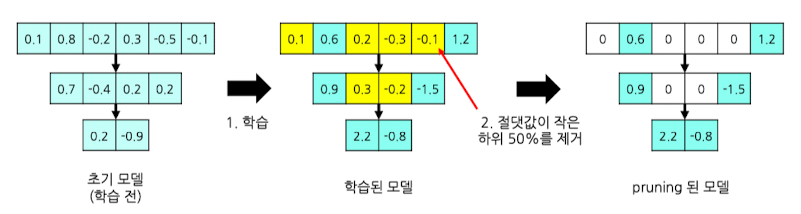
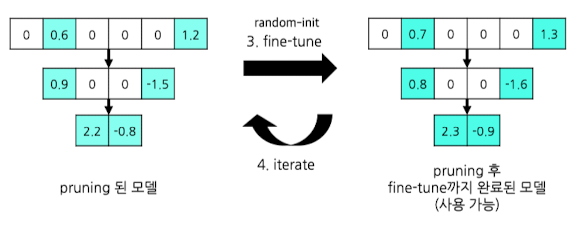
- 기존 데이터로 fine-tuning 진행 (rewind 기법을 통해, 랜덤으로 파라미터 초기화 후 재학습)
-
(Scheduling - recursive) 반복하여 pruning 추가 진행
chat_bubble 댓글남기기
댓글남기기