Matrix Sparsity
개요
- 행렬의 대부분의 요소가 0인 행렬
- Sparsity → 행렬의 전체 요소 중 0의 비율
- Density = 1 - Sparsity
- ex) Dense Matrix vs Sparse Matrix
-
Dense Matrix
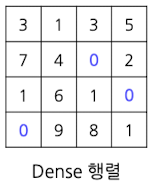
- Sparsity = 3/16 = 18.75%
- Density = 13/16 = 81.25%
-
Sparse Matrix
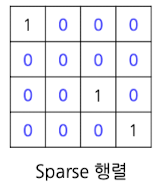
- Sparsity = 13/16 = 81.25%
- Density = 3/16 = 18.75%
-
Pruning 시 Sparse Matrix의 문제점 및 해결책
- Matrix Sparsity와 Unstructured Pruning
- Unstructured Pruning은 파라미터 값을 0으로 바꾸는 경량화 기법
- 이것만으로는, 곧바로 경량화의 목적을 달성할 수 없음
- 여전히 ‘0’이라는 값은 저장되어 있음 (메모리 차지)
- ‘0’이 저장되어 있기에, 계산 과정에서 0을 곱하는 과정을 수행하고 있음 (계산시간 잡아먹음)
- 해결책 → “Sparse Matrix Representation”
- 개요
- 행렬의 Sparsity가 심한 경우 활용
- 행렬에서 0이 아닌 값들의 좌표만 기억 → 메모리 및 연산속도 모두 크게 개선
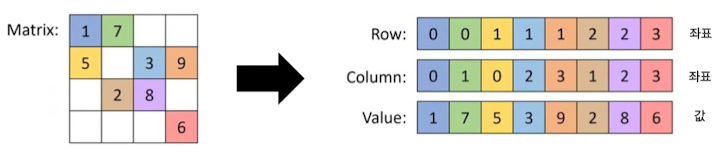
- 메모리 효율
- 일반적인 $n \times m$ 행렬에 필요한 메모리 = $nm$
- Sparse Matrix Representation 방식은 0이 아닌 값만 저장, 따라서 0이 아닌 원소의 갯수를 $k$라 할 때, 필요한 메모리의 양은 3$k$($k$+$k$+$k$)임
- $k$개의 각 원소에 대해, 그 값
- $k$개의 각 원소에 대해, 그 값이 있는 행(row)의 인덱스
- $k$개의 각 원소에 대해, 그 값이 있는 열(column)의 인덱스
- 이 때 Sparsity를 계산해 보면
- sparsity = $k / (nm)$
- 메모리 측면에서 일반 행렬에 비해 Sparse Matrix Representation이 이득이려면
- $3k < nm$ ⇒ $\frac{k}{nm} < \frac{1}{3}$ ⇒ sparsity < 1/3
- sparsity < 1/3이어야 효율성이라는 목적 달성 가능
- 연산 효율
- 일반적인 $n \times m$ 행렬과 $m \times p$ 행렬의 행렬곱 연산량: $\propto nm$
- Sparse 행렬의 경우 계산량
- $n \times m$ 행렬과 $m \times p$ 행렬에서, 0이 아닌 요소의 수가 각각 $k_1, k_2$라고 하면,
- 계산량은 최대 $k_1p, k_2n$에 비례함
- 메모리 효율의 경우처럼, 충분히 Sparse하면 훨씬 효율적
- $k_1p < nmp, k_2n<nmp$
- $k_1/(nm) < 1, k_2/(mp)<1$ → “각 행렬의 Sparsity”
- example
-
Sparse Matrix Representation 미적용한 채로 연산시
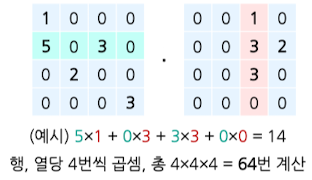
-
Sparse Matrix Representation 적용하여 연산하면
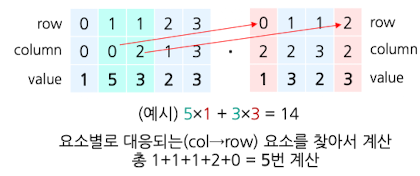
-
- 개요
- 애매하게 Sparse할 경우 → 전용 하드웨어 활용
- 행렬 곱셈 수행 전, 미리 스캔을 통해 0의 위치를 파악(overhead 발생)
- 이를 통해, 사전에 해당 위치를 건너뛰고 계산될 수 있도록 조정
Sensitivity Analysis
개요
- Pruning Ratio
- 모델 전체의 파라미터를 어느 정도 비율로 제거할 것인지
- 레이어 별로 동일하게 일정 비율을 제거하기도 함(Uniform Shrink)
-
하지만 이보다, 레이어 별로 비율을 다르게 설정하는 것이 같은 pruning 효율과 함께 더 높은 성능을 취할 수 있음
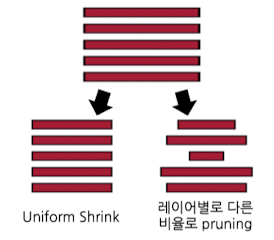
-
그래프를 통한 비교
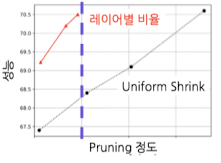
- 아래 검은 선 → 레이어 별로 동일하게 일정 비율을 pruning한 결과
- 위 빨간 선 → 레이어 별 다른 비율로 pruning한 결과 (같은 pruning ratio 대비 더 높은 성능)
- 이처럼, 각 레이어의 특성을 반영하여 pruning하기 위해 레이어 별 중요도를 측정하는 방법을 Sensitivity Analysis라고 함
- 민감도가 높은 부분은 덜 pruning
- 민감도가 낮은 부분은 더 pruning
- 모델 전체의 파라미터를 어느 정도 비율로 제거할 것인지
Sensitivity 측정 과정
- Sensitivity Analysis: 각 레이어의 pruning 비율을 설정하는 중요도 측정 방법
- Global Pruning의 일종
- 실험을 통해 측정하는 실용적인 방법 (empirical, practical method)
- 측정 과정
- 각 파라미터/레이어의 민감도 측정
- pruning 했을 경우의 성능 저하정도를 각 파라미터/레이어 별로 모두 구해줌
- 일반적인 레이어의 민감도 분포
- 가장 앞 부분 레이어가 민감한 편(마치 인식/감각기관에 해당)
- 뒷 부분 레이어는 상대적으로 덜 민감한 편(앞선 정보를 기반으로 최종 판단 내릴 경우에는 많은 연산량이 필요 없음)
- 측정 과정 상세
- 한 레이어를 고르고
- 해당 레이어의 파라미터를 일정 비율 pruning하고, 다시 fine-tuning
-
위 과정을 모든 레이어 별 & 비율 별로 수행하여 성능 측정
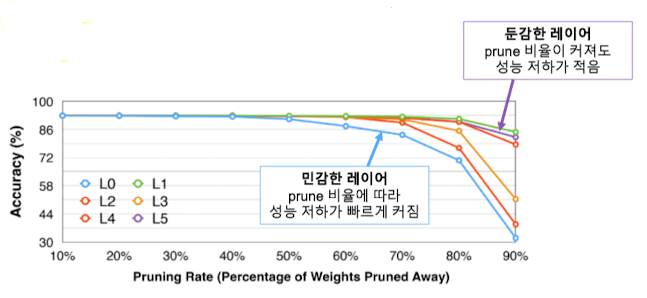
- 성능 저하 허용 범위( $T(\%)$) 고정
-
이를 기준으로, 레이어 별 pruning 비율 결정
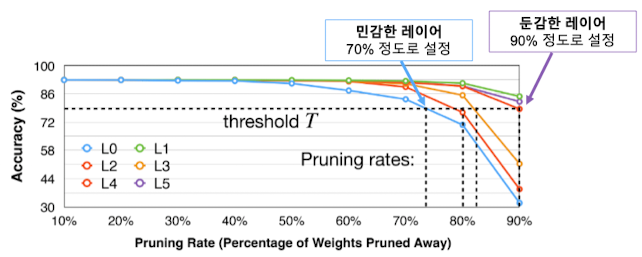
- 각 파라미터/레이어의 민감도 측정
- 활용
- 레이어 별, 비율 별로 각각 측정 → 오래 걸리는 작업이기에 주로 분석용으로 사용
- 단, 모델 구조가 같고 데이터만 다른 경우에는 한번 계산해둔 비율을 어느 정도 재사용 가능함
- 측정 한번에 pruning 전체 과정 1번 만큼의 iteration이 소요됨
- 레이어 별, 비율 별로 각각 측정 → 오래 걸리는 작업이기에 주로 분석용으로 사용
Pruning in CNNs
CNN
- CNN 구조
- 이미지 데이터 처리에 적합한 딥러닝 모델 구조
- 일반적으로, CNN은 CNN 부분과 FC(Fully-Connected) Layer로 나뉨
- 대부분의 파라미터는 FC Layer에 있음
- CNN Pruning
- 대부분의 파라미터는 FC Layer에 있지만, CNN 연산속도의 병목현상은 대체로 CNN 파트에서 발생
- 따라서, CNN과 FC Layer 부분을 각각 pruning 해주어야 공간(메모리)/시간(연산속도) 효율을 모두 챙길 수 있음
- CNN과 FC Layer는 구조적으로 당연히 차이가 날 수 밖에 없기에, 효율적인 pruning 방법이 다를 수는 있음
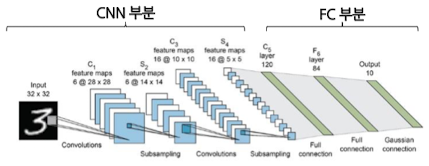
Filter Pruning
- CNN 파트 Pruning
- CNN은 이미지에 적용할 적절한 filter가 필요하고, 이를 학습함
- CNN Filter
- 이미지의 단위(Feature map, ex: 코 모양/입 모양/얼굴 윤곽 등)
- 레이어 별로 각각 여러 개의 filter가 있음
- 앞쪽 레이어: 데이터의 디테일 파악하는 경향
- 뒤쪽 레이어: 데이터의 전체 구조 파악하는 경향
-
역할
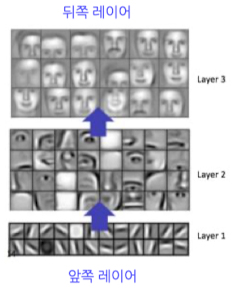
- 이미지가 어느 위치에 있는지를 찾고
- 그 정보들을 조합
- 이미지 분류
- CNN 모델은 좋은 filter를 학습해 내는것이 목표
- Filter Pruning
- 개요
- CNN의 Filter 중, 중요도가 낮은 filter를 판별하여 제거하는 과정
- Filter map 하나를 통으로 날리는 pruning
- 효과
- Strcutured Pruning, 수행 즉시 속도 향상
- Unstructured Pruning → Sparse convolution 연산 구현 필요
- Sparsity가 높은 순으로 Filter 제거
-
ex) 모 레이어에 있는 filter의 실제 모습 → 절반 가량은 sparse or 0에 근접

-
- Strcutured Pruning, 수행 즉시 속도 향상
- Sensitivity Analysis
- Sparse한 filter의 비율이 높은 레이어는, pruning을 많이 진행해도 성능 저하가 덜함 → Sensitivity Analysis로 확인 가능
-
conv_2, conv_10을 비교해 보면 Sparsity가 높은 filter는 pruning을 많이 진행해도 성능 저하가 적음을 알 수 있음
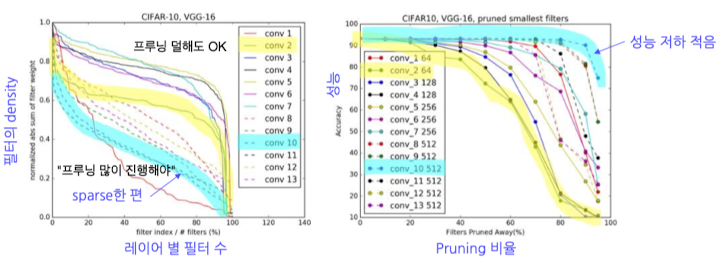
- conv_2(위 그래프에서 노란색): 필터의 density가 상대적으로 높음 → 성능 저하 확연
- conv_10(위 그래프에서 하늘색): 필터의 density가 상대적으로 낮음 → 성능 저하 미미
- Scoring 지표: Filter의 Sparsity ($L^2$-norm)
-
또한 Sensitivity Analysis를 해보면, 뒤쪽 레이어가 앞쪽 레이어에 비해 성능에 미치는 영향이 덜함
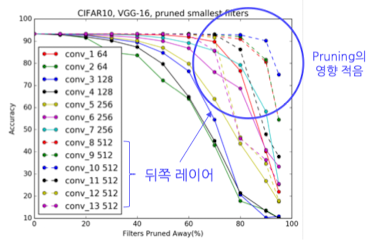
- 큰 형태(이미지의 전체적 구조)를 파악하는 뒤쪽 레이어 → 90%씩 삭제해도 상관없는 레이어도 존재
- 작은 세부사항을 파악하는 앞쪽 레이어 → 과도하게 제거 시, 모델이 이미지의 세부 사항을 파악하기 어려움(작은 형태는 그 다양성이 높기 때문)
- 결론: CNN을 Pruning하는 경우, filter pruning 비율을 레이어 별로 나눠서 분배해 주어야 함
- 개요
Pruning in BERT
BERT
- 개요
- Bidirectional Encoder Representations from Transformer
- LLM 시대 직전의 다용도 언어 모델
- 기능: 단어 자동완성, 문장 분류, 문장 간 관계 파악 등
- 구조
- Transformer의 Encoder만 여러 층 쌓아서 만듦
- BERT-Base: 12개의 인코더 층
- BERT-Large: 24개의 인코더 층
- 각 층 안에는, Multi-head Self-Attention 및 FNN이 포함되어 있음
- Transformer의 Encoder만 여러 층 쌓아서 만듦
BERT Pruning
- BERT의 Layer 특징
- Layer 별 역할
- 앞쪽 레이어: 작은 형태 식별(단어 등)
- 뒷쪽 레이어: 큰 형태 식별(문장 등)
-
BERT Layer의 특징
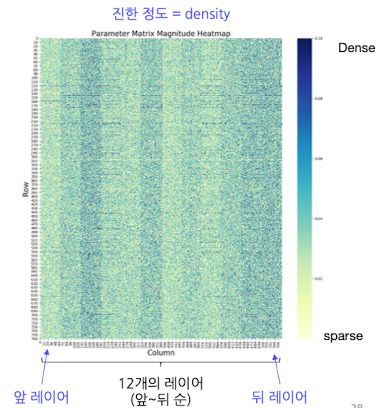
- 레이어 별 Sparsity가 일관적이지 못함 → sparsity가 낮아졌다 높아졌다 반복(특이 패턴)
- 그러므로, Global Pruning 방식은 부적절
- 12개 레이어를 한 번에 묶어, 모든 가중치를 한꺼번에 정렬해서 작은 것부터 잘라내는 방식 → 레이어마다 중요 정도 및 Sparsity가 전부 다른데, 전부 한데 섞어 잘라버리면 어떤 레이어는 너무 많이, 어떤 레이어는 너무 적게 잘리게 되어 위험
- 또한 당연히 Structured Pruning도 위험
- “헤드 하나를 통째로 제거, 뉴런 채널을 통째로 제거, 레이어 자체를 제거”
- BERT는 레이어마다 역할이 다르고, 특정 어텐션 헤드가 문장 구조나 특정 패턴을 특히 잘 담당하는 경우도 있음 → 구조 단위로 큰 덩어리를 없애면 갑자기 성능 하락이 클 수 있음
- 그렇기 때문에, BERT 모델을 pruning할 때는 레이어와 구조의 차이를 고려하여 너무 거친 방식(Global, Structure)보다는 조심스럽게 잘라야 함
- 그러므로, Global Pruning 방식은 부적절
- 또한, 여전히 대부분의 파라미터는 0에 가까움 → 절댓값 기준 pruning이 유효함
- 레이어 별 Sparsity가 일관적이지 못함 → sparsity가 낮아졌다 높아졌다 반복(특이 패턴)
- Layer 별 역할
- BERT 모델의 효율적인 Pruning
- BERT의 첫 번째 레이어: 사실상 “임베딩 행렬”
- Row: 단어
- Column: 해당 단어의 벡터 차원
-
임베딩 행렬의 특징
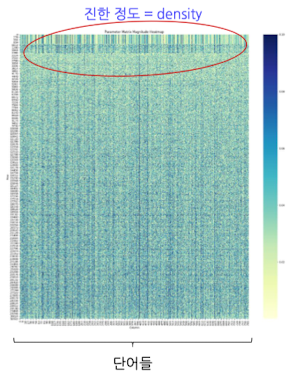
- 짧은 단어(혹은 관사)일수록 임베딩 벡터가 더 sparse한 경향
- 위 히트맵에서도 확인할 수 있듯, 위쪽 영역(짧은 단어 영역)이 더 연한 패턴으로 표시
- BERT 모델의 Pruning 전략
- Local Pruning: 레이어마다 기준을 따로 두고 pruning하는 방식
- 첫 레이어(임베딩 행렬)의 짧은 단어 영역이 많이 sparse하니 해당 부분을 더욱 과감히 자른다면 효율적인 pruning 가능
- 즉, 레이어의 특성을 살린 pruning
- BERT의 첫 번째 레이어: 사실상 “임베딩 행렬”
-
BERT 모델의 Pruning 결과
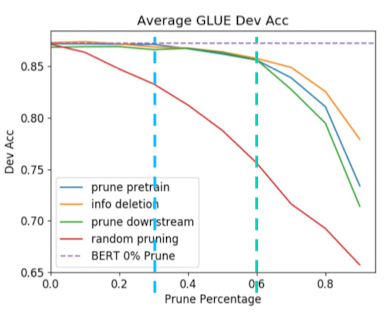
- GLUE 벤치마크 활용
- 파란선: 일반 pruning
- 보라색 점선: pruning 하나도 수행 안한 BERT
- Result by Pruning Ratio
- 30% 가량의 파라미터(세로 파란 점선)는 완전 제거 가능 → 그래프에서 보이듯, 30% 가량은 통째로 제거해도 그 성능이 유지됨
- 이말인 즉슨, 파라미터가 처음부터 불필요하게 많이 있었다는 얘기
- 60% 가량의 파라미터(세로 녹색 점선)를 제거해도 성능 저하가 그렇게 심각하지는 않음
- Pruning 방법에 따라 성능 곡선은 다름
- 무작위로 pruning하는 방법(빨간 곡선)은 성능이 빠르게 망가짐
- 올바르게 설계된 pruning 방법을 수행하면 성능이 훨씬 천천히 떨어짐
- 30% 가량의 파라미터(세로 파란 점선)는 완전 제거 가능 → 그래프에서 보이듯, 30% 가량은 통째로 제거해도 그 성능이 유지됨
- BERT 모델의 Pruning 방법론 요약
- Structure: Unstructured Pruning
- Scoring: Local Pruning(레이어 별), 절댓값 기준으로 파라미터 제거
chat_bubble 댓글남기기
댓글남기기