Knowledge Distillation
개요
- 고성능의 Teacher 모델로부터 지식을 전달받음 → 이를 기반으로 Student 모델을 학습시키는 기법
- 성능 저하를 최소화하면서 모델을 압축하는 방법
- 이를 통해, 작고 가벼운 학생 모델을 사용
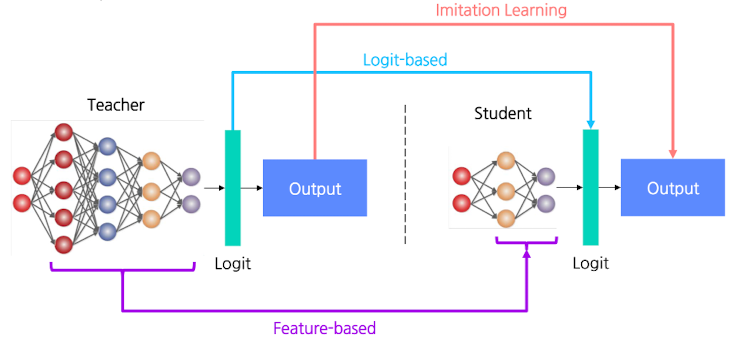
- Teacher vs Student
- Teacher(선생 모델): 일반적인, 고성능의 Pre-trained 모델
- 크고, 무겁고, 느리고, Pre-trained된 모델
- Student(학생 모델): 선생 모델의 증류된 지식을 받아서 학습할 모델
- 작고, 가볍고, 빠르고, 학습할 대상인 모델
- Teacher(선생 모델): 일반적인, 고성능의 Pre-trained 모델
메서드에 따른 KD 기법 분류
- Knowledge: 증류할 지식의 종류에 따른 분류
-
Response-based
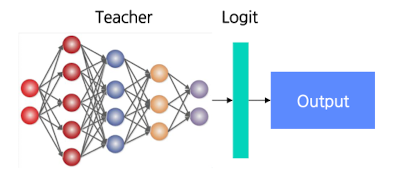
- Logit-based → Teacher 모델의 logit값을 사용
- Logit: 신경망의 마지막 레이어(Sigmoid, Softmax 등)에 들어가기 직전의 raw 벡터
- “확률로 바꾸기 전 점수들”을 그대로 가져와서 Teacher 점수 벡터를 따라 하도록 Student를 학습시킴
- 그렇기 때문에, 클래스들 사이 미세한 점수 차이까지 전달하기 용이함
- Output-based → Teacher 모델의 output값을 사용
- Output: 신경망에서 마지막 레이어까지 모두 통과한 확률분포 값(각 클래스가 정답일 확률값)
- “Softmax 적용 이후 확률들”을 가져와서 Teacher 확률 분포를 따라 하도록 Student를 학습시킴
- 실제 예측에서 보는 값과 바로 연결되는 정보를 전달함
- Logit-based → Teacher 모델의 logit값을 사용
-
Feature-based
- Teacher 모델의 중간 레이어의 feature/representation 활용
-
- Transparency: 모델 내부 구조 / 파라미터 열람 가능 여부에 따른 분류
-
White-Box
- Teacher 모델의 내부 구조, 파라미터 등을 알 수 있는 경우
-
Gray-box
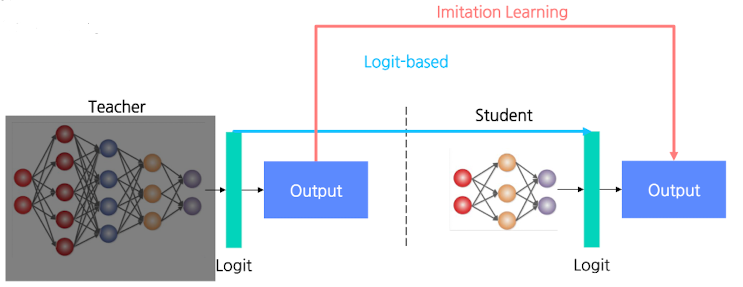
- Teacher 모델의 output, 최종 logit값 등 제한된 정보만 알 수 있는 경우
-
Black-box
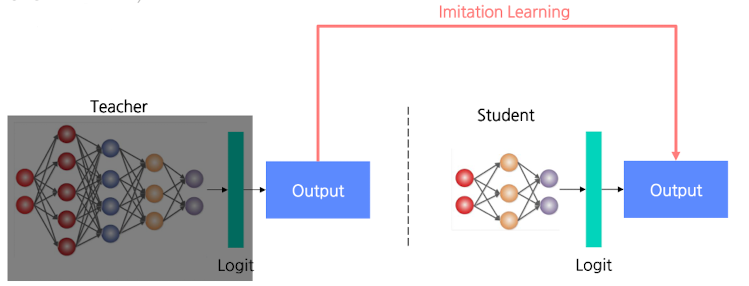
- Teacher 모델의 output만 알 수 있는 경우
-
Logit-based KD
개요
- Teacher 모델의 logit값을 지식으로 활용한 KD 기법
-
Logit
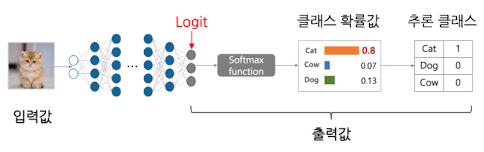
- (넓은 의미) Unnormalized prediction value → “아직 정규화되지 않은 확률분포”
- (좁은 의미) Softmax 함수를 씌워 클래스 확률값으로 만들 수 있는 값들
학습 알고리즘
-
Soft Label vs Hard Label
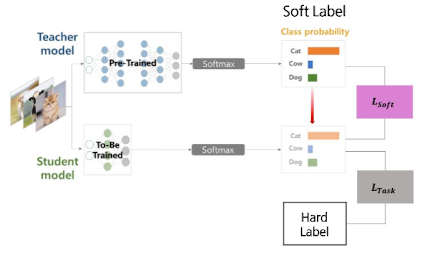
- Hard Label: 정답 클래스 (실제 정답, 즉 가장 높은 확률을 갖는 클래스 1개만 선택, Similarity값 X)
- Teacher, Student 두 모델의 학습에 모두 활용
- Soft Label: 각 클래스에 대한 확률 (모델이 예측하고 있는 확률값)
- Student 모델 학습에 활용 → Soft Label은 곧 Teacher 모델의 logit
- Hard Label: 정답 클래스 (실제 정답, 즉 가장 높은 확률을 갖는 클래스 1개만 선택, Similarity값 X)
- 학습 개요
- 일반적인 분류기 학습
-
여기에 추가로, Teacher의 지식을 학습하는 과정 수행
- Teacher의 지식은 곧 출력값의 확률분포
- Teacher가 사용하는 지식
- 주어진 Logit으로 계산한 클래스의 확률값
- 클래스 간 유사도 정보가 간접적으로는 담겨 있음
- Teacher 모델은 데이터를 학습하면서 클래스 간 유사도를 자연스레 파악함
- Teacher가 사용하는 지식
- Student는 자신의 클래스 예측이 Teacher의 클래스 예측과 유사해지도록 추가 학습 진행 → “정답 라벨을 맞추는 loss + Teacher를 따라가는 distillation loss” 두 가지를 동시에 줄이면서 학습
- Teacher의 지식은 곧 출력값의 확률분포
- 학습과정에서 Student 및 Teacher 모델의 역할
- Teacher
- 분류 문제를 Cross-Entropy Loss로 사전에 학습(Hard Label)
- 이러한 학습의 결과로 나온 클래스 확률값(Softmax 결과값)을 지식으로 Student 모델에 전달
- Student
- 분류 문제를 푸는 Cross-Entropy Loss는 기본(Hard Label), 여기에 더해
- KL-divergence loss 추가 → Student 확률값을 Teacher의 확률값으로 모사하는 Loss값(Soft Label)
- 확률값(확률분포)이 유사한 정도를 측정 → 일반적으로 KL-Divergence 활용
- Teacher
- Teacher 및 Student 모델의 학습 과정 상세
- 개략적 학습 과정
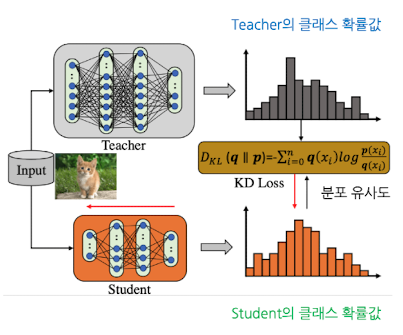
- 입력 이미지 x를 Teacher와 Student 모델에 동시에 넣어줌
- 각 모델에 넣어주면, Teacher, Student 모델 모두 클래스에 대한 logit → Softmax → 확률분포 Output 생성
- Teacher 확률분포($P_t$)를 soft label로 보고, Student의 확률 분포($P_s$)와의 차이를 KL-Divergence로 계산해 distillation loss를 만들어줌
- Distillation loss 생성과 동시에, Student의 예측 $P_s$와 실제 정답 라벨 $y$ 사이의 차이를 cross-entropy loss를 통해 계산
- 최종 Loss값: student loss, distillation loss 두 값의 가중합으로 둠 → 최종 loss값을 줄여나가는 방향으로 Student의 가중치를 역전파로 업데이트해줌
- 1-4과정을 반복하면, Student 모델은 정답을 맞춤과 동시에 Teacher가 주는 부드러운 확률 분포의 패턴까지 흉내내어 자신의 클래스 예측이 선생님의 클래스 예측과 유사해 지도록 학습
- 입력 이미지 x를 Teacher와 Student 모델에 동시에 넣어줌
-
Teacher 모델의 학습 과정
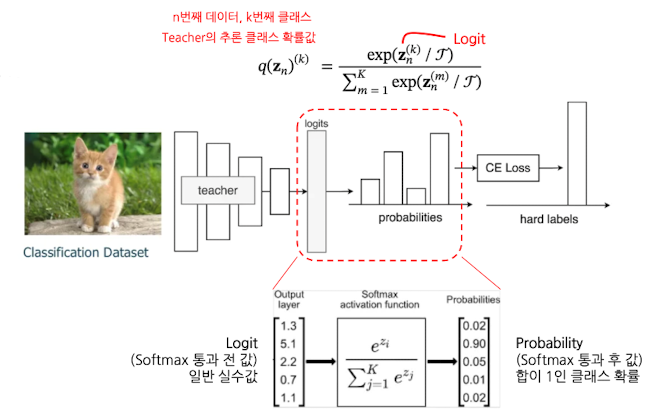
- 데이터와 정답 준비
- 고양이/강아지 같은 이미지와, 각각에 대한 정답 라벨(벡터)이 주어진 상태에서 시작
- 입력을 Teacher 모델에 통과
- 고양이/강아지 같은 이미지를 Teacher 네트워크에 넣으면, 마지막 층에서 각 클래스에 대한 logit값이 나옴
- logits → probabilities(확률)로 변환
- 이 logits에 softmax 함수를 적용해서, 각 클래스가 정답일 “확률 분포”로 바꿔줌
- ex) logits [5.1, 2.2, 0.7] → softmax 통과 → [0.9, 0.08, 0.02]처럼 확률 벡터로 변환(합이 1)
- Cross‑Entropy loss 계산
- “위에서 얻은 확률 분포 ↔ 앞서 주어진 정답 라벨” 비교 → cross‑entropy loss 계산
- 정답 클래스 확률이 높을수록 loss는 낮아지고, 낮을수록 loss가 높아짐
- 역전파로 가중치 업데이트
- 계산된 Cross‑Entropy loss를 기준으로 역전파 수행 → Teacher 네트워크의 모든 가중치를 조금씩 수정
- 이 과정을 전체 학습 데이터에 대해 여러 epoch 반복, Teacher가 점점 더 정답 라벨에 맞는 확률 분포(=출력)를 내도록 성능 개선
- 데이터와 정답 준비
-
Student 모델의 학습 과정
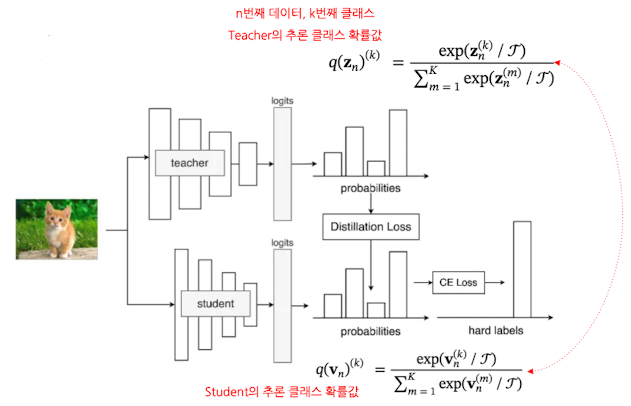
- 입력을 Teacher / Student 모델에 동시에 넣기
- 고양이 이미지 한 장을 Teacher, Student 두 모델에 동시에 넣어줌
- 두 모델 모두 마지막 층에서 각 클래스에 대한 logits 출력
- logits → 확률(softmax)로 바꾸기
- Teacher logits에 softmax(온도 $\tau$ 적용 가능) 적용하여 Teacher 확률 분포 $p_{tea}$ 얻음
- Student logits에도 같은 방식으로 softmax를 적용해 Student 확률 분포 $p_{stu}$ 얻음
- Distillation loss(KL Divergence) 계산
- Teacher 확률 분포 $p_{tea}$를 “soft target”이라고 보고, Student 분포 $p_{stu}$와 $p_{tea}$ 간 KL Divergence 계산 → “Distillation loss 생성”
- 두 분포가 비슷할수록 KL 값이 작아짐 / 다를수록 커짐 → loss값을 줄여 Student 예측이 Teacher 예측과 점점 가까워지도록 만들어줌
- Cross-Entropy loss 계산(정답 라벨 기반)
- 이와 동시에 Student 확률 분포와 실제 정답 라벨 간 cross‑entropy loss도 계산
- 일반적인 분류 학습과 동일하게, Student가 정답을 잘 맞추도록 만드는 역할
- 이와 동시에 Student 확률 분포와 실제 정답 라벨 간 cross‑entropy loss도 계산
- 두 loss를 섞어서 역전파 수행
- 최종 loss는 보통 두 loss의 가중합으로 둠
- L = $\alpha \cdot$CE(Student, hard label) + $\beta \cdot$KL(Teacher, Student) 형태
- 이 최종 loss를 기준으로 역전파 수행 → Student의 가중치 업데이트
- 데이터 전체에 대해 여러 epoch 반복
- 최종 loss는 보통 두 loss의 가중합으로 둠
- 입력을 Teacher / Student 모델에 동시에 넣기
- 개략적 학습 과정
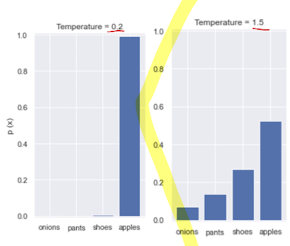
- Temperature 인자
-
확률분포를 날카롭게/완만하게 조절해주는 인자

- $T<1$: 날카롭게
- $T>1$: 완만하게
- 모든 클래스에 대해, logit 값을 동일한 temperature로 나눠 softmax 적용
-
균등 분포로 만들어주면, 연관도 및 유사도 파악이 쉬움
-
- Teacher 및 Student 모델의 추론 확률값 및 Loss 수식 정리
- 추론 클래스 확률값 ($n$번째 아이템, $k$번째 클래스)
- Teacher: $q(z_n)^{(k)} = \frac{\exp(z_n^{(k)}/\mathcal{T})}{\sum_{m=1}^K \exp(z_n^{(m)} / \mathcal{T})}$
- Student: $q(v_n)^{(k)} = \frac{\exp(v_n^{(k)}/\mathcal{T})}{\sum_{m=1}^K \exp(v_n^{(m)} / \mathcal{T})}$
- Loss값
- KL Loss(Soft Label): $\mathcal{L}{KL}(q(v_n) \vert q(z_n) = \sum{k=1}^K q(v_n)^{(k)}\log(\frac{q(v_n)^{(k)}}{q(z_n)^{(k)}})$
- CE Loss(Hard Label): $\mathcal{L}{CE}(q(v_n), q(z_n) = - \sum{k=1}^K q(v_n)^{(k)}\log{q(z_n)^{(k)}}$
- Teacher, Student의 Loss
- Teacher: $\mathcal{L}_{CE}$
- Student: $\lambda_{CE}\mathcal{L}{CE} + \lambda{KL}\mathcal{L}_{KL}$
- 추론 클래스 확률값 ($n$번째 아이템, $k$번째 클래스)
성능
- 데이터셋
- CIFAR100 → 이미지를 100개 클래스로 분류하는 task(train: 50k, test: 10k)
- 모델
- Teacher: ResNet-56(Layer 층수) → 파라미터 약 860k개
- Student: ResNet-20(Layer 층수) → 파라미터 약 270k개
-
결과
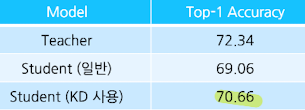
Logit-based KD의 효과
- Label Smoothing
- 일반적인 정답 라벨(One-hot encoding)은 매우 뾰족한 분포
- Logit-based KD의 “soft label” → 오답에도 약간의 점수를 주어 부드러운 분포를 만들어줌
-
ex) Dog는 오답이지만, 약간의 점수를 부여함

-
- 이렇게 부드러운 분포를 사용하게 된다면,
- 모델이 한 클래스에만 과한 확신을 갖지 않아 overfitting을 방지할 수 있고
- 이에 따라, 다양한 상황에 더 잘 버티는 robustness 및 일반화 성능이 향상됨
- Continuous Distribution
-
Discrete vs Continuous
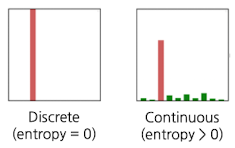
- One-hot Label이 0 또는 1로만 알려주는 discrete distribution를 보여주지만
- soft label은 여러 클래스에 연속적인 확률값을 주는 continuous distribution임
-
이러한 Continuous Distribution는 엔트로피가 높아, Student 모델이 데이터 간 미묘한 차이점까지 학습
- 마치 더 어려운 문제를 풀게 되는 것과 같고, 표현력이 향상되게 됨
-
- Intra-class variance
- 클래스 내부의 다양성 파악
-
“고양이” 클래스 안에도 털 색, 자세, 배경이 모두 다른 여러 인스턴스가 존재 → Teacher의 Soft label은 서로 다른 고양이 이미지에 대해 다양한 패턴을 만들어줌

- 이로 인해, Student는 단순히 고양이면 무조건 1이 아니라
- 고양이 내에서 다양한 모습들을 구분하는 능력을 갖춤과 함께, 모두가 다 고양이라는 공통점을 유지하는 더욱 풍부한 내부 표현을 배우게 됨
- Inter-class variance
- 클래스 간 관계 파악
-
서로 비슷한 클래스들(동물 클래스: 고양이, 개, 소 등) → 서로의 확률 값이 완전히 0이 되지 않고, Teacher 모델의 soft label에서 어느 정도 유사한 패턴으로 나타남

- Student는 이 분포를 따라가면서, 클래스 간 간 관계까지 함께 학습
- ex) “고양이는 개보다는 더 비슷하고, 소와는 덜 비슷하다.” 등
chat_bubble 댓글남기기
댓글남기기