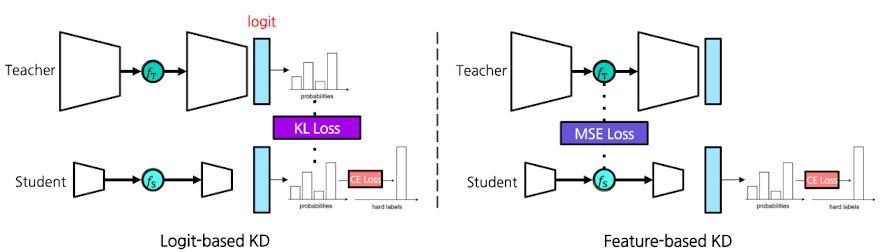
Feature-based KD
개요
- Teacher 모델의 Layer 특징값(feature)을 사용
- = 중간 계산 결과, 추론 과정
- ex) In CNN
- CNN filter는 뒤쪽 레이어일 수록 큰 형태를 확인하는 특징
-
이러한 특징을 Student 모델이 물려받을 수 있도록 전달하는 것이 Feature-based KD
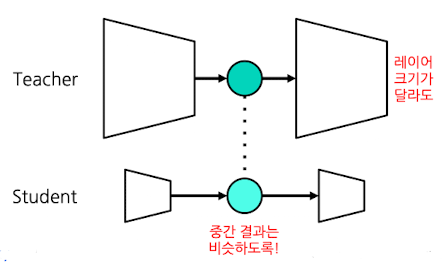
학습 알고리즘
- vs. Logit-based KD
-
Feature-based Loss는 KL Loss 대신 MSE Loss를 추가해줌
-
-
학습 알고리즘 상세
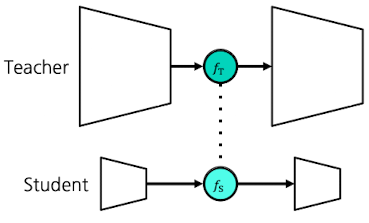
- Logit-based KD와 비교한 차이점
- Student가 물려받는 중간 레이어
- Teacher의 중간 레이어 $f_T$($d_T$차원)
- Student의 중간 레이어$f_S$($d_S$차원)
- 물려 받는 중간 레이어의 차원 일치 이슈
- $d_T \neq d_S$일 수 있으므로(구조가 서로 다르므로)
- 이를 해결하기 위해, Student는 Regressor Layer 사용($R$)
- $R$: $\mathbb{R}^{d_T} \to \mathbb{R}^{d_S}$
- 추가되는 Loss (Logit-based KD 대비)
- MSE Loss = MSE($f_T, R(f_S)$) → “Mean Squared Error”
- Student가 물려받는 중간 레이어
- Logit-based KD와 비교한 차이점
- Feature map
- 중간 레이어에서 추출한 feature map을 Knowledge distillation에 활용
- 이유
- 다양한 수준의 정보 포함
- 초기 레이어는 주로 low representation(엣지, 텍스처 등) 표현
- 특정 데이터에 덜 특화되어 있어 distillation 효율이 좋지 못함
- 후반 레이어는 주로 high representation(클래스 수준 정보) 표현
- 지나친 고수준 정보만 담고 있음 → Logit-based KD와 큰 차이점이 없는 기법이 됨
- 거의 유사한 정보를 담고 있는 형국
- 중간 레이어는, 이 둘의 중간에서 distillation 효과를 극대화시킴
- 초기 레이어는 주로 low representation(엣지, 텍스처 등) 표현
- 의미 있는 표현
- 선정된 feature map은 Student가 중요한 표현을 학습할 수 있는 레이어 → 최종 결과에 직접적 영향
- 다양한 수준의 정보 포함
- Loss
-
Student는 원래 task + feature 동시 학습
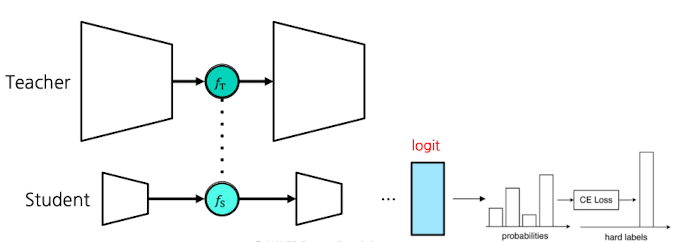
- Teacher’s loss: $\mathcal{L}_{CE}$
- Student’s loss: $ \lambda_{CE} \mathcal{L}_{CE}
-
- \lambda_{MSE} \mathcal{L}_{MSE} $
Imitation Learning
Black-box
- 모델의 내부(파라미터, 레이어 등), 추론 과정 등은 알 수 없음
- 입력에 따른 결과만 접근 가능한 모델
- ex) 사과 이미지를 준다면, 결과로 “이것은 사과입니다!”라는 결과만 확인 가능 / 어떻게 추론하였는지는 알 수 없음
- 보통 외부에 모델 존재, API로만 접근 가능
- Black-box 모델이 좋은 경우
- 내부를 모르는 좋은 모델이 있을 때,
-
그 모델에 많이 물어보고 답변을 모아서, 그걸 선생님 삼아 내 모델을 대신 키우는 방법
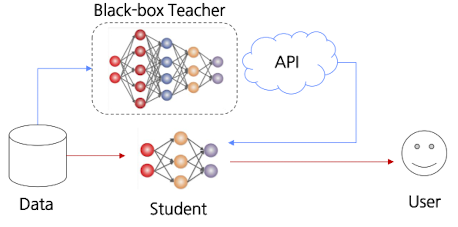
Imitation Learning
- 개요
- 타 에이전트의 행동을 관찰, 이를 모방하여 자신의 정책을 학습하는 ML 방법론
- 출력 결과 외 모델 정보를 얻을 수 없는 Black-Box 모델의 지식을 전달 받는 방법 → 최근 NLP 분야에서 많이 활용
-
과정
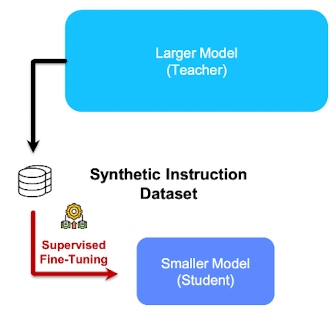
- 모방 데이터 수집
- Seed 질문 설정 → “Teacher 모델에 어떤 질문을 할 것인가?”
- 공개 데이터 활용하거나
- Teacher 모델에 부탁하여 생성
- 지식 추출 → “어떻게 Teacher 모델로부터 더 유의미한 답변을 추출할 것인가?”
- 주로 Prompt Engineering 활용 → 답변 유도를 위한
- 다양한 형태의 답변 생성 유도
- 구체적 과정 및 설명 과정 답변 유도
- 주로 Prompt Engineering 활용 → 답변 유도를 위한
- Seed 질문 설정 → “Teacher 모델에 어떤 질문을 할 것인가?”
- 데이터 전처리
- 수집된 데이터의 품질 확인 및 검증
- 의미 없는 대화
- 불충분, 너무 짧은 대화
- Hallucination
- 특정 유형의 ‘질문-답변’ 페어가 지나치게 많거나 적지 않도록
- 수집된 데이터의 품질 확인 및 검증
- 모델 재학습
- 품질 검증이 끝난 데이터 활용
- 모방 데이터 수집
- Imitation Learning의 장단점
- 장점
- Black-box 모델이 KD에 접근 가능한 유일한 방법
- 다른 기법과 다르게, 증류된 지식이 인간이 해석 가능한 형태
- 단점
- LLM이 출력한 응답만으로는 LLM 내부 지식을 심층적으로 이해하고 학습하기 어려움
- 데이터 품질에 민감함 → 답변의 다양성 및 새로운 상황에 대한 대응력 떨어짐
- 장점
- 예시 모델
- 명확한 Imitation Learning 모델
- Orca
- GPT‑4와 ChatGPT가 만들어 준 복잡한 설명/chain‑of‑thought 등을 보고 그 추론 과정을 모방하도록 설계된 모델
- 전형적인 Imitation Learning + KD 셋팅
- Orca
- 강한 LLM이 만든 답을 모방하여 학습한 모델
- Vicuna
- LLaMA에 대해, 실제 사용자–ChatGPT 대화(ShareGPT) 같은 “다른 모델이 만든 응답 데이터”로 instruction 튜닝한 모델
- 결과적으로, ChatGPT 스타일을 모방하도록 학습된 imitation 성격이 강하다.
- WizardLM
- 강한 teacher LLM을 프롬프트로 삼아, Evol‑Instruct라는 인스트럭션·응답 데이터를 자동 생성 → 그 데이터를 정답으로 LLaMA를 파인튜닝한 모델
- synthetic teacher 데이터를 이용한 imitation/instruction learning 계열에 속함
- Vicuna
- 명확한 Imitation Learning 모델
기타 KD 기법
Multi-teacher
- 여러개의 Teacher로부터 평균적으로 학습
-
Ensemble method의 일종
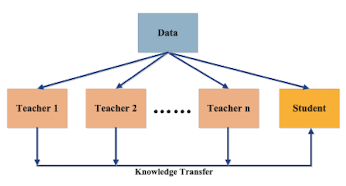
- 단일 Teacher의 possible error 최소화
- Teacher 일부에서 오답이 발생해도, Student는 안정적인 학습이 가능
- 단일 Teacher의 possible error 최소화
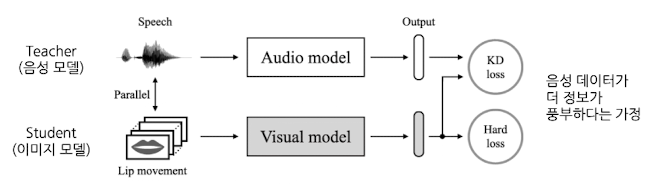
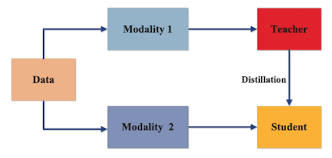
Cross-modal
- 다른 modality를 지닌 Teacher에게 배우기
-
Modality: 이미지, 음성, 텍스트 등
-
chat_bubble 댓글남기기
댓글남기기