Quantization
개요
- Quantization(양자화): 숫자의 정밀도(precision)를 낮추는 경량화/최적화 기법
- 메모리 및 연산량을 낮춰줌
- 정밀도(precision)란?
- 의도한 숫자를 얼마나 정확하게 표현할 수 있는가? 를 나타낸 수치
- ex) $\pi$의 값을 나타낼 때
- 고정밀도 표현: 3.141592(상대적으로 작은 오차)
- 저정밀도 표현: 3(상대적으로 큰 오차)
컴퓨터 과학에서, 숫자의 정밀도에 따른 특징
-
낮은 정밀도로 숫자를 표현한 경우,
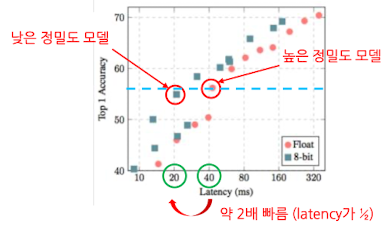
- 계산 속도 향상(최대 2.3배 → 이는 자료형에 따른 수치)
- 오차 발생(성능 감소)
- 메모리 사용량 감소(최대 1/4로 절약 가능)
- Quantization의 목적
- 오차를 최소화하면서
- 낮은 정밀도 표현을 찾아 메모리 및 연산속도 효율을 추구
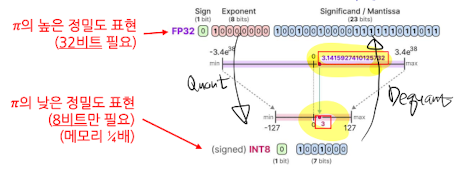
- ex) $\pi$를 양자화 할 경우
- Quantization: 32비트에서 8비트로 → 메모리 1/4 절감
- Dequantization: 8비트에서 32비트로 → 메모리 4배 소모
- Quantization 구현 방법
- 양자화 구현을 위해서는, 높은 정밀도 값을 적절한 낮은 정밀도 값에 mapping하는 함수가 필요함
-
“Quantization Mapping”
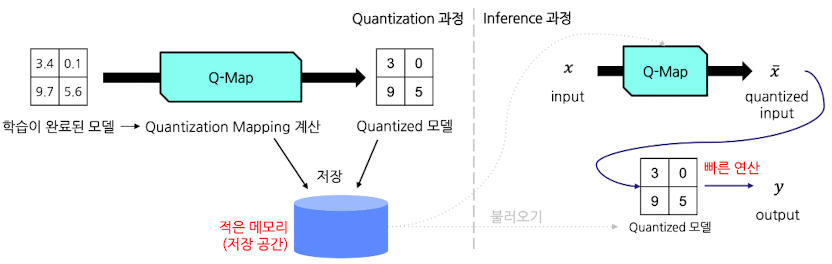
- 올바른 계산을 위해서는 Dequantization 과정도 필수적
컴퓨터 과학에서, 숫자를 표현하는 방법
- 기본적으로, 컴퓨터는 이진법을 통해 숫자를 표현함
- 몇 개의 0과 1만을 사용해 표현
- 여기서 ‘몇 개’는 곧 비트(bit)수
- Float vs Integer
- 소수점이 없는 정수일 경우, Integer 사용
- 소수점이 있는 실수는 Floating Point(FP, 부동소수점) 사용
- ML의 경우 대부분 실수 형태의 데이터
-
숫자표현 ex) INT8 기준 숫자 표현 방법
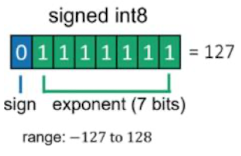
- 부호(sign): 1비트
- 값(exponent): 7비트
- 표현 범위: -127~128
-
숫자 형태변환 ex) FP32로 표현된 실수 데이터
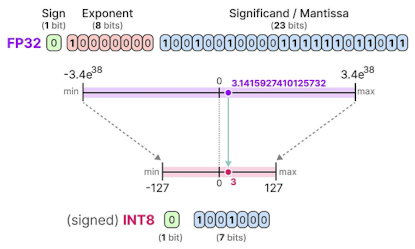
- Quantization의 목적: 오차를 최소화 하면서, FP16 혹은 INT8 등의 형태로 변환하는 것
- 위 그림처럼, FP32를 INT8로 나타낼 수 있다면
- 메모리: 32비트 → 8비트 (75% 절약)
- 계산속도: 약 2배 증가
- 실제 CPU·GPU에서는 연산 유닛 구조, 파이프라인, 명령어 세트 때문에 INT8 전용 연산에 쓸 수 있는 하드웨어 자원이 FP32만큼 넉넉하지 않음 → 보통 2배 안팎의 처리량 증가만 나온다고 알려져 있음
- 또한 데이터를 가져온 뒤 실제 곱셈·덧셈을 하는 연산 유닛의 처리 속도가 그만큼(4배) 올라가지 못함 → 전체적으로 보면 “메모리는 4배 여유, 계산은 2배 정도” 수준에서 타협되는 경우가 많음
-
비트수 별 숫자의 표현 가능 범위
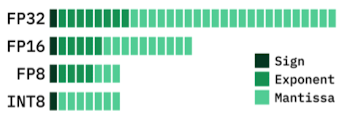
- 정수형(INT) 기준 범위
- INT8: -128 부터 127까지
- 부호 1비트, 값 7비트
- 7비트는 $2^7=128$가지 숫자 표현 가능
- 값의 범위: [-128, 127]
- INT16: -32768 부터 32767까지
- INT32: -2147483648 부터 214748367까지
- INT8: -128 부터 127까지
- 부동소수점(FP) 기준 범위 → 정수형과 달리, 정확한 값 대신 대략 적인 범위의 실수를 다룸
- FP16
- 대략 $\pm 10^5$
- 정규화된 값 기준: 대략 $\pm 6 \times 10^{-5}$ 부터 $\pm 6 \times 10^{4}$까지
- FP32
- 대략 $\pm 3.4 \times 10^{38}$
- 정규화된 값 기준: 대략 $\pm 1.2 \times 10^{-38}$ 부터 $\pm 3.4 \times 10^{38}$까지
- FP16
- (당연히) 많은 비트를 소모할 수록, 그 정밀도와 범위가 늘어남 → 표현력 증가
- ex) 비트수에 따른 $\pi$값 표현 정밀도
- FP64의 $\pi = 3.141592653589793$
- FP32의 $\pi = 3.1415927$
- INT8의 $\pi= 3$
- ex) 비트수에 따른 $\pi$값 표현 정밀도
- 정수형(INT) 기준 범위
- 숫자 형식 변환 예시
- FP32로 표현된 $350.5, 1.5, -350.5$ ⇒ “INT8로 표현하기”
- INT8이 표현 가능한 숫자의 범위: $[-128, 127]$
- $350.5 > 127$ → 단순 반올림으로는 숫자 범위 문제 해결 불가
- 방법1) INT8 범위 내에 넣기 위해, 3으로 나누고 반올림
- 변환값: $117, 0, -117$
- 복구값: $351, 0, -351$ (다시 3 곱해줌)
- 오차합: $\left\vert -0.5 \right\vert + \left\vert 1.5 \right\vert + \left\vert 0.5 \right\vert = 2.5$
- 방법2) 2.76로 나누고 반올림 (2.76이라는 값은, 변환값을 127에 맞추기 위함 - 나누었을때 127이 되도록)
- 변환값: $127, 1, -127$
- 복구값: $351, 0, -351$ (다시 2.76 곱해줌)
- 오차합: $\left\vert -0.02 \right\vert + \left\vert -1.26 \right\vert + \left\vert 0.02 \right\vert = 1.3$
- Quantization의 목적 → 어떠한 방법으로도, 자료형을 가벼운 것으로 변환해 주면서도 오차합을 줄여 나가는 것
- FP32로 표현된 $350.5, 1.5, -350.5$ ⇒ “INT8로 표현하기”
- 정확도 오차합에 따른 Quantization 성능 차이
- Quantization의 에러가 커질수록 성능은 저하함(당연)
- 가장 큰 문제는, 여러 번 Quantization이 수행됨에 따라 생성되는 작은 오차들이, 여러 층을 거치면서 누적되고 커진다는 것
- 특히, 의료/자율주행과 같은 정밀도가 중요한 분야에서는 이 오차 누적이 매우 치명적
- 뉴런 비활성화: 작은 양수를 음수로 오변환한 경우, ReLU 함수가 이를 0으로 만들어 비활성화
Quantization Mapping
개요
- 정확도가 높은 데이터를 낮은 데이터로 대응시키는 Quantization 계산식임
- ex) 직전의 예시처럼 FP32로 표현된 데이터를 INT8로 표현하는 과정에서, “INT8 범위 내에 넣기 위해 3으로 나누고 반올림 하거나 2.76로 나누고 반올림하는 행위”
- 데이터 Mapping: 전체 데이터 단위로 mapping 생성
- 파라미터 Mapping: (일반적으로) 레이어 단위로 mapping 생성
- Mapping example
- 점수 범위: 70점-320점
- 백분율 변환성적 범위: 0-100
- 방법: “Projection 활용” → 가장 좋은 기록(320점): 100 / 가장 나쁜 기록(70점): 0
Mapping 방법
-
대칭성에 따른 mapping 방법 분류
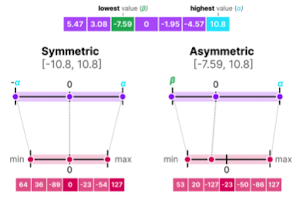
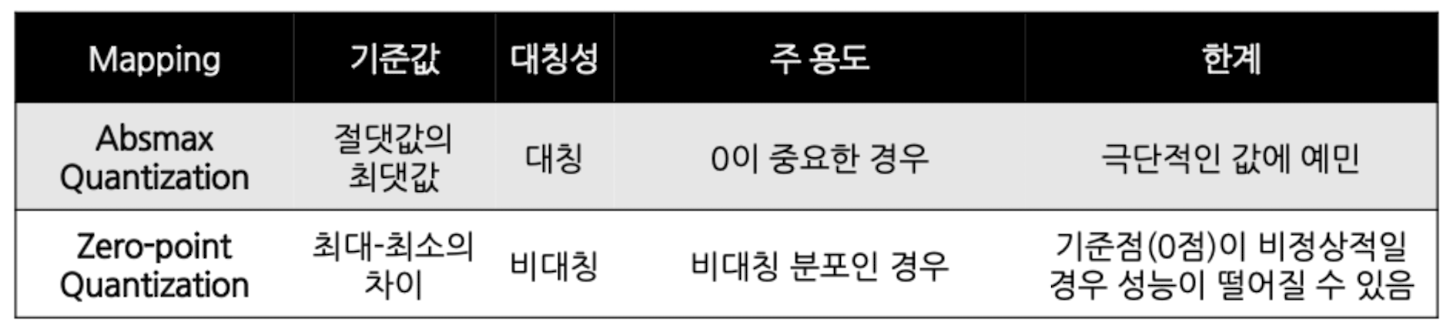
- Absmax Quantization (symmetric)
- 0을 기준으로, 변환 후 값들의 범위가 좌우 대칭이 되도록 변환
- 대칭적인 분포, 0을 0으로 mapping해주는 것이 효과적일 경우 활용
- Zero-point Quantization (asymmetric)
- 0을 고려하지 않고, 전체 범위를 균일하게 변환
- 0이 0으로 mapping됨을 보장할 수 없는 경우
- ReLU: 비대칭적인 양자화 방법이 더 오차가 적음(양수 값만 활용하기 때문)
- Absmax Quantization (symmetric)
-
양자화 시, 저장하는 파라미터 종류
- 양자화 과정: 양자화, 양자화시킨 값 저장, 양자화 시킨 값을 다시 복원(역양자화, Dequantization)
- 양자화 과정에서, 저장해야 하는 파라미터
- Quantized value($X_{quant}$) → 실제 양자화 과정을 거쳐서 도출된 값
- Scale factor($s$) → 기울기
- zero-point($z$) → 0을 양자화한 이후의 위치(Dequantization에 활용)
- 양자화, 역양자화 수식 표현
- $X_{quant} =$ round $(\frac{X}{s}+z)$
- 스케일을 조정하고($\div s$)
- 원점이동($+z$)
- 여기에 반올림하여 최종 정수 값 도출
- $X_{dequant} = s \times (X_{quant}-z)$
- 다시 원점만큼 돌아가고($-z)$
- 스케일을 복원시킨 다음($\times s$)
- 원래의 값 다시 복원($X_{dequant}$)
- $X_{quant} =$ round $(\frac{X}{s}+z)$
Absmax Quantization
- $s, z$만 있으면 모든 값 양자화/역양자화 가능
- $X$: 원본 데이터, $X_{quant}$: 양자화된 값, $X$: 복원된 값(역양자화 값)
- 과정
- 주어진 원본 데이터 집합에서, 절댓값의 최댓값 도출(absmax) → 이 값이 “기준값”이 됨
- 기준값에서 두배를(x2) 한 값이, 양자화 후 -127 부터 127 사이(INT8 기준)에 들어오도록 scaling
- $s = \frac{max \left\vert X \right\vert}{127}$
- 비율대로 다른 값들도 마찬가지로 INT8 내에서 조정
- Absmax는 대칭 방식의 양자화 기법이기에, $z = 0$ 임
-
Absmax 양자화 계산 예시
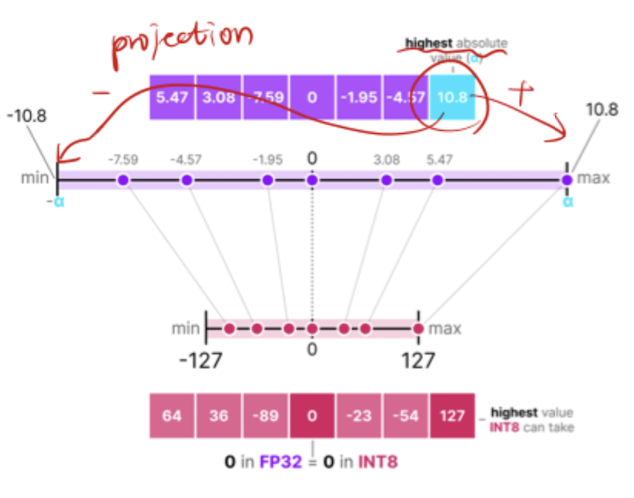
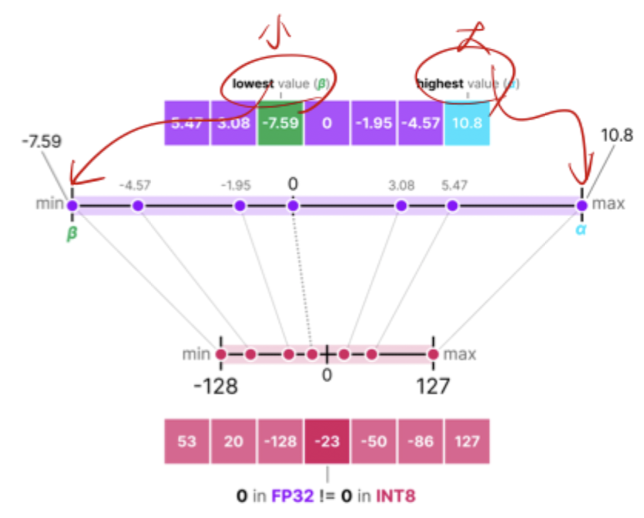
- 주어진 데이터: $X = [5.47, 3.08, -7.59, 0, -1.95, -4.57, 10.8]$ → absmax(X) = 10.8
- $s$값 계산
- $s = \frac{max \left\vert X \right\vert}{127} = \frac{10.8}{127}$
- Quantization
- $X_{quant} = round(\frac{1}{S} \times X + z) = round(\frac{127}{10.8} \times (-7.59)) \approx -89$
- 양자화된 데이터 결과
- $X = [64, 32, -89, 0, -23, -54, 127]$
- 부동소수 없이 모두 정수로 저장(INT8로 변환했기에)
- 양자화 된 값들을 다시 역양자화
- $X_{dequant} = s \times (X_{quant} - z) = \frac{10.8}{127} \times -89 \approx -7.57$
- 모든 데이터 역양자화 완료하면: $X = [5.44, 3.06, -7.57, 0, -1.96, -4.59, 10.8]$
- 결과 정리
- 주어진 데이터: $X = [5.47, 3.08, -7.59, 0, -1.95, -4.57, 10.8]$
- 양자화 데이터: $X = [64, 32, -89, 0, -23, -54, 127]$
- 복원(역양자화) 후 데이터: $X = [5.44, 3.06, -7.57, 0, -1.96, -4.59, 10.8]$
- 발생한 오차(MSE): 약 0.0028
- 양자화 파라미터 정리
- 양자화 데이터: $X = [64, 32, -89, 0, -23, -54, 127]$
- 기존 데이터: FP32, 양자화 데이터: INT8
- 메모리 절약 양: 1/4 절감
- Scale factor: $\frac{10.8}{127}$
- Zero-point: 0(Absmax는 대칭 기법)
- 양자화 데이터: $X = [64, 32, -89, 0, -23, -54, 127]$
Zero-point Quantization
- (INT8인 경우) 전체 데이터에서, 최댓값이 127 / 최솟값이 -128이 되도록 $s, z$ 계산
- $s$: 양자화 대상인 값들의 범위에 대한 양자화하고자 하는 자료형에 대한 범위
- $s=\frac{max X - min X}{127-(-128)}$
- $z = -128-round(\frac{minX}{s})$
- $min X$값을 -128에 고정시킬 때의 $z$값 계산
- $s$: 양자화 대상인 값들의 범위에 대한 양자화하고자 하는 자료형에 대한 범위
-
Zero-point 양자화 계산 예시
- $X = [5.47, 3.08, -7.59, 0, -1.95, -4.57, 10.8]$
- $s, z$ 계산
- $s = \frac{max X - minX}{127-(-128)}=\frac{10.8-(-7.59)}{255}=\frac{18.39}{255}$
- $z = -round(\frac{minX}{s})-128 = -round(\frac{255}{18.39} \times{-7.59}) -128 = -23$
- Quantization
- $X_{quant} = round(\frac{X}{S}+z) = round(\frac{255}{18.39} \times X - 23) \approx -128$
- 모든 값을 양자화 해주면
- $X = [53, 20, -128, -23, -50, -86, 127]$
- Dequantization
- $X_{dequant} = s \times (X_{quant}-z)=\frac{18.39}{255} \times(-128 -(-23))$
- 복원 완료된 $X$: $[5.44, 3.06, -7.57, 0, -1.96, -4.59, 10.8]$
- 결과 정리
- 주어진 데이터: $X = [5.47, 3.08, -7.59, 0, -1.95, -4.57, 10.8]$
- 양자화 데이터: $X = [53, 20, -128, -23,-50, -86, 127]$
- 복원(역양자화) 후 데이터: $X = [5.44, 3.06, -7.57, 0, -1.96, -4.59, 10.8]$
- 발생한 오차(MSE): 약 0.0019
- 양자화 파라미터 정리
- 양자화 데이터: $X = [53, 20, -128, -23,-50, -86, 127]$
- 기존 데이터: FP32, 양자화 데이터: INT8
- 메모리 절약 양: 1/4 절감(Absmax와 동일)
- Scale factor: $\frac{18.39}{255}$
- Zero-point: -23
- 양자화 데이터: $X = [53, 20, -128, -23,-50, -86, 127]$
Absmax vs Zero-point
- Absmax의 한계점은, Clipping 기법을 통해 해결 가능
Clipping
- 개요
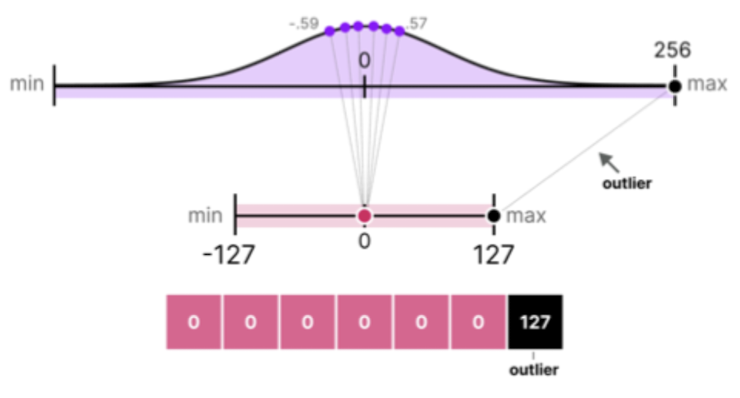
- 극단적인 outlier 값의 영향을 줄이기 위한 기술
- 일정 범주 초과시, 같은 값으로 취급
- 예시
- $X = [-0.59, -0.21, -0.07, 0.13, 0.28, 0.57, 256]$
- 위 데이터 집합에서는, 256이 극단적으로 큰 값(Outlier 값)
-
Outlier 값을 Quantize 하기위해 나머지 값을 모두 0으로 mapping
- Calibration
- 위와 같은 예시처럼, outlier를 제외한 대부분의 값이 0으로 mapping되면 나머지 데이터들이 무의미한 수준이 되어 버림
- 그렇기에, Outlier를 제외한 나머지 값들도 적절하게 qunatize하기 위해 적절한 범주를 찾는 과정을 Calibration이라고 함
- 보통 경험적으로 찾음
- 예시) 위와 같은 예시에서, 범위를 $[-5, 5]$로 둔다면?
- Outlier를 제외한 나머지 값들이 0으로 mapping 되는것을 방지
chat_bubble 댓글남기기
댓글남기기