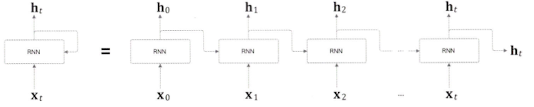
RNN
RNN 개요: “순환하는 신경망”
순환하는 신경망이란? → 반복해서 되돌아가는 신경망
- 어느 한 지점에서 시작한 것이, 시간이 지나 다시 원래 장소로 되돌아오는 것
- 그리고 이러한 과정을 계속해서 반복하는 것
이렇게 “순환하는 신경망”을 갖추기 위해서 필요한 것은? → ==닫힌 경로==가 필요함 - 닫힌 경로가 있어야, 이를 통해 데이터가 끊임없이 순환하면서 ==끊임없는 정보 갱신== 가능
- 동시에 데이터가 순환되기 때문에, ==과거의 정보를 기억함==과 동시에 최신 데이터로 갱신 가능
RNN 계층 구조
- 입력: 시계열 데이터 $x_t$, 이전 시각의 hidden state $h_{t-1}$ (둘 다 행벡터)
- 출력: hidden state $h_t$를 거쳐, 출력값 $y_t$ 생성
- 시각 별 정보 업데이트 수식: $h_t = f_{\theta}(h_{t-1}, x_t)$
- 가변적인 길이의 Sequence 자료 $x_t$ 입력
- ex) “I study math” sequence 입력 → timestep 별로 토큰화되어 단어 입력
- 매 time step $t$마다 반복적으로 수식을 적용하여 $x_t$를 처리
- $h_t = tanh(W_{hh} h_{t-1} + W_{xh} x_t+ b)$
- 실행 결과: “$h_{t-1}$이라는 상태에서 위 식의 과정을 통해 $h_t$로 갱신”
- $W_{xh}$: 입력 $x_t$를 출력 $h_t$로 변환하기 위한 가중치
- $W_{hh}$: 또 다른 입력 $h_{t-1}$을 다음 시각에 대한 출력으로 변환하기 위한 가중치
- $b$: 편향
- tanh: Activation Function
- Zero-Centered Fuction
- 동일한 파라미터를 지속적으로 이용하는 RNN의 특성 상, 안정적인 학습을 시켜주는 데 도움
- 만약, tanh 대신 Sigmoid를 활용한다면 Explode gradient(기울기 폭발) 현상이 발생할 것
- 과정 도중, ==target을 예측==하기 위하여 $h_t$를 이용하여 $y_t$를 출력할 수 있음
- 실행 결과: “$h_{t-1}$이라는 상태에서 위 식의 과정을 통해 $h_t$로 갱신”
- 가변적인 길이의 Sequence 자료 $x_t$ 입력
RNN의 Hidden State Vector 계산 상세
- RNN 모델의 기본 구조
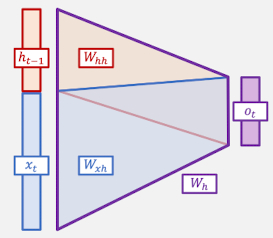
- $h_t = tanh(O_t)$
- $O_t = W_{hh}h_{t-1} + W_{xh}x_t$
- $h_{t-1}$, $x_t$를 concat하여 선형 변환 수행
- 표현: 세미콜론(;) → $h_t = tanh(W_h[h_{t-1};x_t])$

- $W_{hh}$: $h_{t-1}$을 $h_t$로 변환
- $W_{xh}$: $x_t$를 $h_t$로 변환
- $h_t = tanh(O_t)$
Rolled / Unrolled RNN
표현 방식의 차이
- Rolled 형태: 개념적 이해와 메모리 효율성에 중점
- Unrolled 형태: 학습 알고리즘 구현과 시간적 의존성 분석에 중점
==구분해서 표현하는 목적==
- 학습 알고리즘 연결
- BPTT(오차역전파)는 정의상 RNN을 ==시간으로 “unroll”하여 Chain Rule 적용== → 학습 설명과 구현상 고려사항을 다루려면 Unrolled 표현이 필요
- 자원/엔지니어링 논의
- Unrolled RNN → ==각 시점의 활성화와 그래프를 저장==해야 해 메모리가 시퀀스 길이에 비례로 늘어난다는 점을 드러내 주며, 이 때문에 실전 테크닉이 설명 가능해짐(truncated BPTT, 체크포인트, 배치구성 등)
- 개념 단순화
- Rolled 관점은 “같은 셀을 반복 사용하며 파라미터를 공유한다”는 본질을 간결히 보여 주어 모델 구조와 재사용 개념을 빠르게 이해시키는 데 적합
- Rolled 관점은 “같은 셀을 반복 사용하며 파라미터를 공유한다”는 본질을 간결히 보여 주어 모델 구조와 재사용 개념을 빠르게 이해시키는 데 적합
관점에 따른 차이(Rolled vs Unrolled)
- 계산 그래프 관점
- Rolled RNN: 순환 구조를 가진 사이클이 있는 계산 그래프
- Unrolled RNN: 비순환 방향 그래프(DAG)로 변환된 형태
- 학습 알고리즘의 필요성
- Rolled RNN: 순환 연결로 인한 사이클 때문에 표준 역전파를 직접 적용하기 어려움
- Unrolled RNN: ==시간에 따른 역전파(BPTT)==를 위해 필수적
- 매개변수 공유 표현
- Unrolled RNN: 매개변수 공유를 명확히 보여주는 것
- 모든 시간 단계에서 동일한 가중치 행렬 사용
- 시퀀스 길이에 관계없이 고정된 매개변수 수
- 일반화 능력 향상
수식 표현
- Rolled RNN → 함수 형태로 압축하여 표현, 모든 시각에서 동일한 함수가 반복적으로 적용
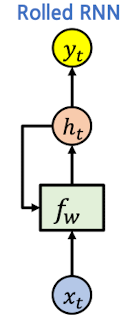
- $h_t = f_w(h_{t-1}, x_t)$
- $h_t$: New State
- $h_{t-1}$: Old State
- $x_t$: Time step t에서의 입력벡터
- $f_{w}$: 입력 t에 따른 가중치 업데이트 함수
- $h_t = f_w(h_{t-1}, x_t)$
- Unrolled RNN → 각 시간단계를 명시적으로 전개하여 표현
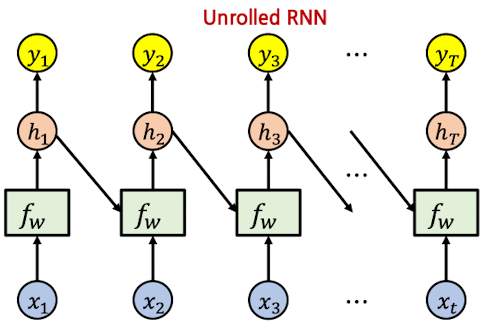
- $h_t = tanh(W_{hh}h_{t-1} + W_{xh}x_t)$
- $y_t = W_{hy}h_t$
- $h_0$: 보통 zero vector
- $h_0$: 보통 zero vector
BPTT(Backpropagation Through Time)
Unrolled RNN에서는, 일반적인 오차역전파법을 적용할 수 있음
- Forward 먼저 수행 → 이후 Backpropagation 수행
- 시간 방향(Forward)으로 펼친 신경망의 오차역전파법 → “BPTT”
BPTT의 문제점과 Truncated BPTT
- RNN에서 BPTT를 적용하기 위해서, 선제적으로 해결해야 할 문제점이 있음
→ “긴 시계열 데이터” 학습 시
- 시계열 데이터의 시간 크기가 커짐에 따라
- ==BPTT가 소비하는 컴퓨팅 자원== 증가
- 매 시각마다 RNN 계층의 중간 데이터를 메모리에 유지해 두어야 하기 때문 2. 역전파 시 기울기가 불안정
- 시계열 데이터의 시간 크기가 커짐에 따라
- BPTT의 문제점 해결을 위해, Truncated BPTT 적용
- 시간축 방향으로 과다하게 길이가 길어질 경우, 길어진 신경망을 적당한 지점에서 잘라냄
- 이렇게 잘라진 각각의 신경망에 대해 오차역전파법을 수행
- 주의) 연결을 끊을 때에는, 순전파는 끊지 않고 ==오로지 역전파만== 끊어냄
- 순전파는 그대로 유지된다는 말인즉슨, ==데이터 입력은 순서대로== 이루어져야 한다는 것
- 미래의 블록과는 독립적으로 오차역전파법 완결시킴
- Truncated BPTT 학습과정

- 1단계: 첫 번째 블록 ($x_0$ ~ $x_9$)
- $x_0$ → $x_1$ → … → $x_9$ 순전파 수행
- $h_9$까지의 loss로 역전파 수행
- 가중치 업데이트 ($W, U, b$ 갱신됨)
- $h_9$ 값을 메모리에 저장 (다음 블록에서 사용할 예정)
- 2단계: 두 번째 블록 ($x_{10}$ ~ $x_{19}$)
- 저장해둔 $h_9$를 초기 은닉상태로 사용
- $x_{10}$ → $x_{11}$ → … → $x_{19}$ 순전파 수행 ($h_9$에서 시작)
- $h_{19}$까지의 loss로 역전파 수행 (단, $h_9$ 이전으론 안 감)
- 가중치 업데이트
- 이렇게 블록 별로 계산이 이어짐
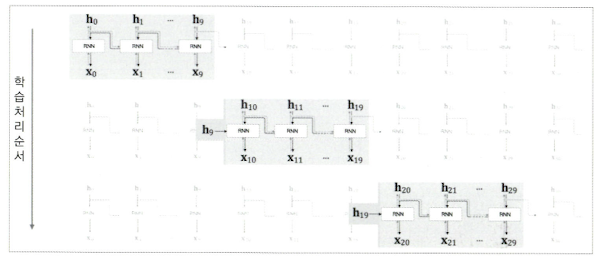
- 미니배치 학습 시
- 앞선 경우의 예시는, 배치 사이즈가 1인 경우에 해당
- 데이터를 주는 위치를 ==각 미니배치의 시작 위치==로 옮겨줌
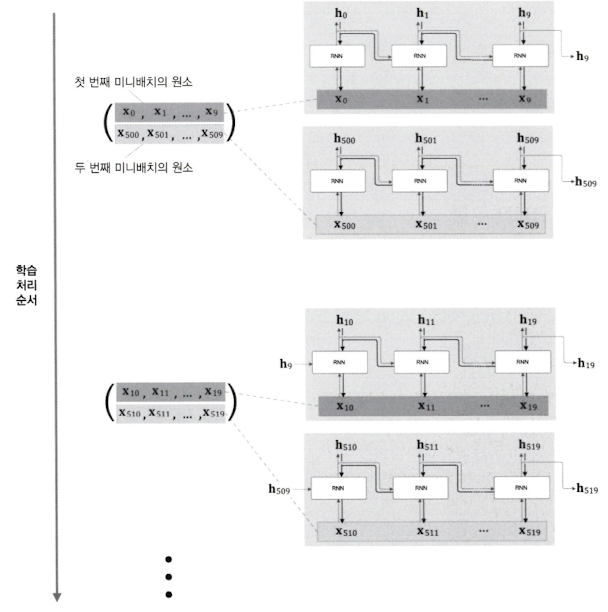
- ex) 위 그림처럼, 마찬가지로 길이가 1000인 시계열 데이터에 대해 미니배치 크기 2로 학습시키면
- 첫 번째 블록의 첫 번째 미니배치 원소는 $x_0$ , … , $x_9$
- 첫 번째 블록의 두 번쨰 미니배치 원소는 $x_{500}$ , … , $x_{509}$
- 두 번째 블록의 첫 번째 미니배치 원소는 $x_{10}$ , … , $x_{19}$
- 두 번째 블록의 두 번쨰 미니배치 원소는 $x_{510}$ , … , $x_{519}$
- ex) 위 그림처럼, 마찬가지로 길이가 1000인 시계열 데이터에 대해 미니배치 크기 2로 학습시키면
- 1단계: 첫 번째 블록 ($x_0$ ~ $x_9$)
Language Modeling
RNN과 Language Modeling
- RNN: 순환구조를 가진 신경망의 한 종류
- Language Modeling: 주어진 문맥에서 다음 토큰의 확률분포를 예측하는 확률 모델
- RNN을 수단이라 하면, Language Modeling은 수단을 통해 이루고자 하는 목적 → RNN은 LM을 구성하는 구현 방법 중 하나
RNN으로 구성한 Language Modeling 예시
Vocabulary: [h,e,l,o]
학습 문자열: “hello”
- 과정
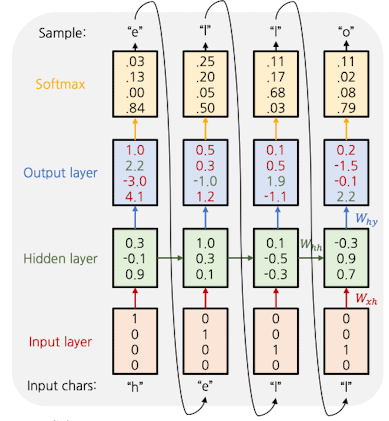
- Input Layer: “One-hot encoding”
- 각 문자를 One-hot encoding으로 입력
- 각 문자를 만약 One-hot encoding이 아닌 숫자 1,2,3으로 표현했다면, 각 문자 간 continuous한 순서가 생김 → 실제로는 문자 간 순서에 따른 index는 없음
- Hidden Layer
- Input layer의 입력 $x_t$로 Hidden state $h_t$ 계산
- $h_t = tanh(W_{hh}h_{t-1}+W_{xh}x_t)$
- Output Layer
- Hidden state $h_t$에서 출력 $y_t$ 계산
- $y_t=W_{hy}h_t$
- Activation function → “Softmax”
- 활성함수로 Softmax 적용하며 ==각 문자의 확률==을 계산해줌
- 이어 Loss 계산 및 학습(Cross-entropy)
- 추론
- 한 글자씩 생성하여 입력
- ex) “h”입력 → “e”예측 → 예측한 “e” 입력 → “l”예측 → …
- Input Layer: “One-hot encoding”
chat_bubble 댓글남기기
댓글남기기