RNN의 문제점: Exploding Gradient / Vanishing Gradient
RNN의 가장 큰 문제점은 시계열 데이터의 ==장기 의존 관계를 학습하지 못하==는 데에 있다.
BPTT 중에 파라미터를 업데이트하면서 ==기울기 소실(Vanishing Gradient)== 혹은 ==기울기 폭발(Exploding Gradient)==이 일어나기 때문이다.
Exploding / Vanishing Gradient
발생원인
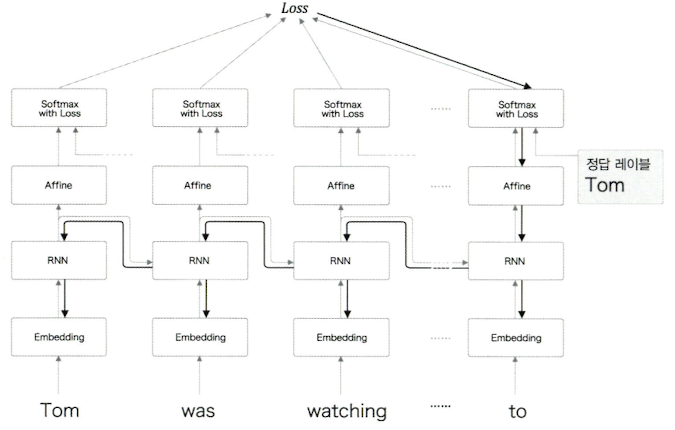
- 정답 레이블이 ‘Tom’임을 학습할 때에는 중요한 것은 RNN계층이 과거 방향으로 “의미 있는 기울기”를 전달하는 것임
- 기울기에는 학습해야 할 의미있는 정보가 담겨 있고, 이를 과거로 전달하면서 장기 의존 관계 학습
- 그렇기 때문에, 이 기울기가 과거로 전달되는 도중 사그라들면 장기 의존 관계를 학습할 수 없게됨
- 하지만, RNN같은 아직 단순한 계층들에서는 기울기가 여러 번 전달되는 과정에서는 기울기가 0으로 수렴하거나 무한대로 발산하게 됨 → 기울기 폭발 / 소실 현상의 발생
RNN 학습 예시
개요
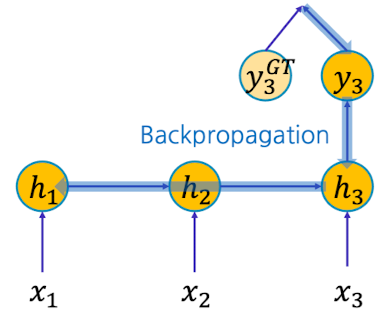
- $h_1 = tanh(ah_0 + bx_1 + c)$
- $h_2 = tanh(ah_1 + bx_2 + c)$
- $h_3 = tanh(ah_2 + bx_3 + c)$
- $y_3 = dh_3 + e$
Backpropagation 수행 $f = y_3$ 라 놓으면, $\frac{df}{dh_1}$을 구하여 역전파 계산
- $\frac{df}{dh_1} = \frac{df}{dh_3} \times \frac{dh_3}{dh_2} \times \frac{dh_2}{dh_1}$
- $\frac{df}{dh_3} = \frac{d(dh_3+e)}{dh_3} = \frac{d}{1} = d$
- 정리: $\frac{df}{dh_1} = d \times \frac{dh_3}{dh_2} \times \frac{dh_2}{dh_1}$
- $\frac{dh_3}{dh_2} = \frac{d(tanh(ah_2 + bx_3 + c))}{dh_2}$
- $X = ah_2 + bx_3 + c$ 치환하면
- $\frac{dh_3}{dh_2} = \frac{dX}{dh_2} = (1-{tanhX}^2) \centerdot a = a(1-{h_3}^2)$
- 정리: $\frac{df}{dh_1} = d \times a(1-{h_3}^2) \times \frac{dh_2}{dh_1}$
- $\frac{dh_2}{dh_1} = a(1-{h_2}^2)$
- 정리: $\frac{df}{dh_1} = d \times a(1-{h_3}^2) \times a(1-{h_2}^2)$
- $\frac{df}{dh_1} = d \times a(1-{h_3}^2) \times a(1-{h_2}^2)$
- 여기서 문제가 되는 항은 $a$
- Timestep이 점점 길어질 수록, a의 지수는 점점 증가
- $\vert a \vert > 1$ → $\lim_{n\to\infty} a^n = \infty$ → “Exploding Gradient”
- $\vert a \vert < 1$ → $\lim_{n\to\infty} a^n = 0$ → “Vanishing Gradient”
Exploding / Vanishing Gradient in RNN
- RNN: $h_t = tanh(W_{hh}h_{t-1} + W_{xh}x_t + b)$
- 첫 Hidden-state vector에 $W_{hh}$ 반복적으로 곱하는 것과 유사
- $h_t \propto W_{hh}^{t-1}\, h_1$
- $h_t$ 벡터에 대해
- $tanh$에 대한 Backprop 계산
- $W_{hh}$에 대한 Backprop 계산
- $W_{hh}$: 마치 FCN 계산과 유사
- gap만큼($t-1$) 반복
- $h_t \propto W_{hh}^{t-1}\, h_1$
- $W_{hh}$가 Eigencomposition을 통해 $VDV^{-1}$로 분해 가능하다고 가정하면
- $W_{hh}^{t-1}h_1= VD^{t-1}V^{-1}h_1$
- 행렬 $D$ → Eigenvalue의 대각 행렬 → Eigenvalue의 지수승($t-1$) 곱함
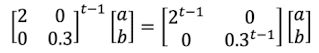
- $2^{t-1}$과 곱해지는 $a$는 Exploding Gradient: Eigenvalue의 절댓값이 1보다 큼
- 완벽하진 않지만, 해결책: threshold (gradient cliping) → Gradient가 증가하는 한계점을 잡아줌
- $0.3^{t-1}$과 곱해지는 $b$는 Exploding Gradient: Eigenvalue의 절댓값이 1보다 작음
- $2^{t-1}$과 곱해지는 $a$는 Exploding Gradient: Eigenvalue의 절댓값이 1보다 큼
chat_bubble 댓글남기기
댓글남기기