1. Tensor의 생성
1.1 특정한 값으로 초기화된 Tensor 생성, 변환
- 0으로 초기화된 Tensor 생성: zeros
- 1-D Tensor (5) :
a = torch.zeros(5) - 2-D Tensor (2x3) :
b = torch.zeros([2, 3]) - 3-D Tensor (3x2x4) :
c = torch.zeros([3, 2, 4])
- 1-D Tensor (5) :
- 0으로 초기화되어 있고, 크기와 자료형이 같은 Tensor 생성: zeros_like
- Like Tensor e :
g = torch.zeros_like(e)
- Like Tensor e :
- 1로 초기화된 Tensor 생성: ones
- 1-D Tensor (5) :
a = torch.ones(5) - 2-D Tensor (2x3) :
b = torch.ones([2, 3]) - 3-D Tensor (3x2x4) :
c = torch.ones([3, 2, 4])
- 1-D Tensor (5) :
- 1로 초기화되어 있고, 크기와 자료형이 같은 Tensor 생성: ones_like
- Liken Tensor b :
h = torch.ones_like(b)
- Liken Tensor b :
1.2 난수로 초기화된 Tensor 생성
- [0, 1] 구간의 연속균등분포 난수 Tensor 생성: rand
- 1-D :
i = torch.rand(3) - 2-D :
j = torch.rand([2, 3])
- 1-D :
- 표준정규분포에서 추출한 난수 Tensor 생성: randn
- 1-D :
k = torch.randn(3) - 2-D :
I = torch.randn([2, 3])⇒ dtype을 torch.int로 지정하면 오류 발생
- 1-D :
- 연속균등분포에서 추출한 난수로 생성하고, 크기와 자료형이 같은 Tensor 생성: rand_like
- Like Tensor k :
m = torch.rand_like(k)
- Like Tensor k :
- 표준정규분포에서 추출한 난수로 생성하고, 크기와 자료형이 같은 Tensor 생성: randn_like
- Like Tensor i :
n = torch.randn_like(i)
- Like Tensor i :
- 연속균등분포 & 표준정규분포 - 자세한 내용은 ML for RecSys 파트에서
- 연속균등분포
- 표준정규분포
- 연속균등분포
1.3 지정된 범위 내에서 초기화된 Tensor 생성
- 간격이 int(int64) - 1에서 11까지 2씩 증가하는 1-D Tensor
o = torch.arange(start = 1, end = 11, step = 2)
- 간격이 float (float) - 1에서 4까지 0.5씩 증가하는 1-D Tensor
o = torch.arange(start = 1, end = 4, step = 0.5)
1.4 초기화되지 않은 Tensor 생성
- 초기화되지 않은 Tensor
- “초기화 되지 않았다” → 생성된 Tensor의 각 요소가 명시적으로 다른 특정 값으로 설정되지 않았음을 의미 → 초기화되지 않은 Tensor 생성 시, 해당 Tensor는 메모리에 이미 존재하는 임의의 값들로 채워짐
- 초기화 되지 않은 Tensor를 사용하는 이유
1) 성능 향상 : Tensor 생성 직후 곧바로 다른 값으로 덮어쓸 예정인 경우 → 불필요한 자원 소모 감소
2) 메모리 사용 최적화 : (큰 Tensor 다룰 때) 불필요한 초기화는 곧 불필요한 자원(메모리 사용량) 소모
- 초기화 되지 않은 Tensor 생성
- 1-D :
q = torch.empty(5)
- 1-D :
- 초기화 되지 않은 Tensor를 다른 데이터로 수정
- 1-D : 기존 Tensor 수정 vs 새로운 Tensor 생성
q.fill_(3.0)⇒ "in-place 연산" : 기존 Tensor 수정, (당연히) 메모리 주소 유지q.fill(3.0)⇒ "일반 연산" : 새 Tensor 생성, 메모리 주소 바뀜
- 1-D : 기존 Tensor 수정 vs 새로운 Tensor 생성
1.5 list, Numpy 데이터로부터 Tensor 생성
- List vs Numpy
- 공통: 여러 값을 순차적으로 저장할 수 있음
- 차이: Numpy는 대규모 수치 데이터에 대한 연산 및 조작에 적합
- List s를 Tensor t로 생성
- list는 여러 값을 순차적으로 저장 가능한 가변적인 컨테이너 데이터타입 → list를 tensor로 생성 가능
t = torch.tensor(s)
- 2-D Matrix Numpy u에서 Tensor v로 생성
u = np.array([[0, 1], [2, 3]])- u to v:
v = torch.from_Numpy(u) - 정수형 → 실수형 타입 캐스팅:
v = torch.from_Numpy(u).float()
- u to v:
1.6 CPU Tensor 생성
- 정수형 CPU Tensor 생성: FloatTensor
w = torch.IntTensor([1, 2, 3, 4, 5])
- 실수형 CPU Tensor 생성: IntTensor(부호 있는 32bit 실수)
x = torch.FloatTensor([1, 2, 3, 4, 5])
- 기타 정수, 실수형 CPU Tensor 생성
1) 8비트 부호 없는 정수형: torch.ByteTensor
2) 8비트 부호 있는 정수형: torch.CharTensor
3) 16비트 부호 있는 정수형: torch.ShortTensor
4) 64비트 부호 있는 정수형: torch.LongTensor
5) 64비트 부호 있는 실수형: torch.DoubleTensor
1.7 Tensor의 복제
- 1-D Tensor x 에 대해,
y = x.clone()z = x.detach()→ x를 계산 그래프에서 분리하여 새로운 Tensor z에 저장
1.8 CUDA Tensor 생성과 변환 → PyTorch 최대장점
- GPU? - “그래픽 처리 장치”
- AI의 대규모 데이터 처리와 복잡한 계산을 위해 사용
- 병렬처리작업: GPU의 수천개의 코어가 대량의 연산을 동시에 수행
- 속도: GPU의 병렬 처리 능력으로, AI 모델의 훈련 및 추론 속도 대량 향상
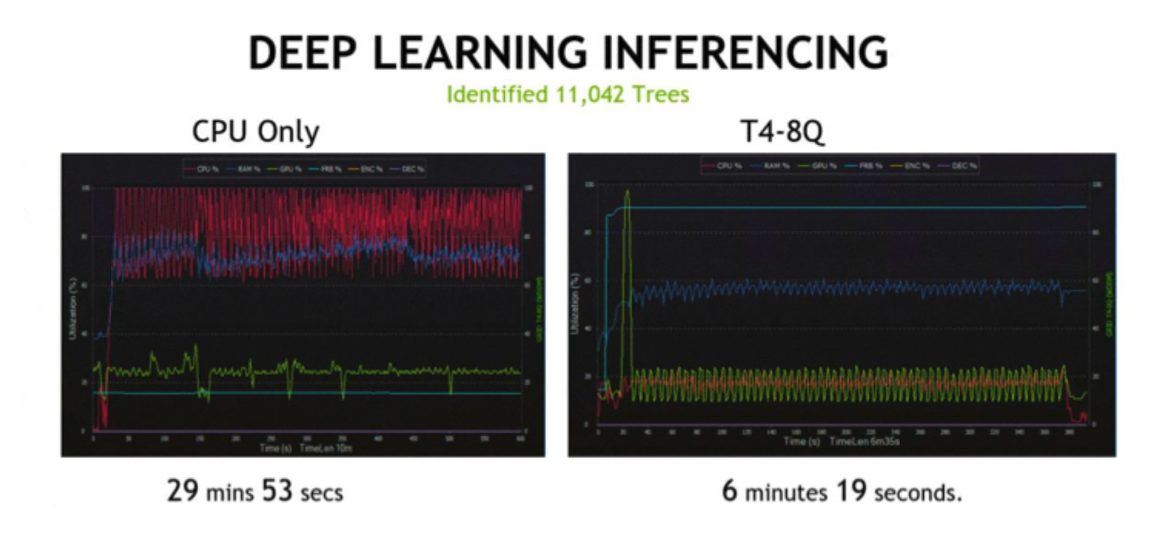
- AI의 대규모 데이터 처리와 복잡한 계산을 위해 사용
- Tensor가 위치한 현재 디바이스 확인: device
a.device
- CUDA 기술 사용 가능 환경인지 확인: cuda.is_available()
torch.cuda.is_available()
- CUDA device 이름 확인: get_device_name
torch.cuda.get_device_name(device=0)
- Tensor를 GPU에 할당: .to('cuda') / .cuda()
b = torch.tensor([1, 2, 3, 4, 5]).to(’cuda’) / .cuda().to('a'): a 장치로 Tensor 이동
- 사용 가능한 GPU 개수 확인: cuda.device_count()
torch.cuda.device_count()
- GPU 할당된 Tensor를 CPU Tensor 변환: .to(device = ‘cpu’) / .cpu()
c = b.to(device = ‘cpu’)c = b.cpu()
chat_bubble 댓글남기기
댓글남기기