추천시스템이란?
추천시스템의 필요성
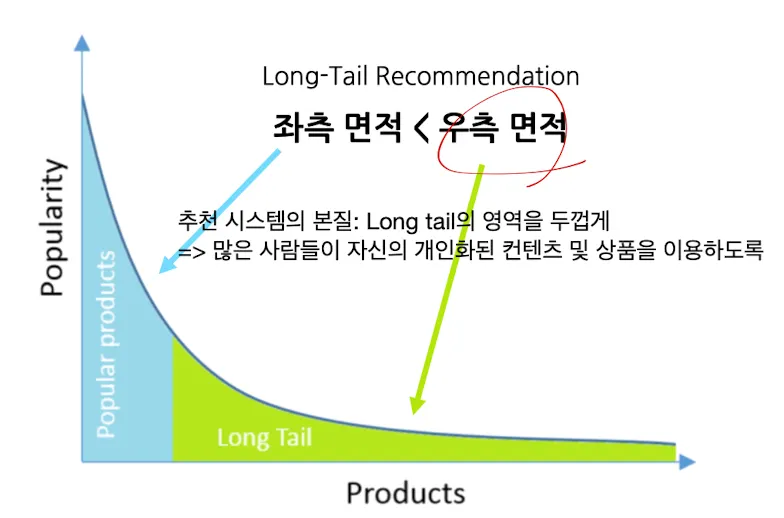
- 웹/모바일 환경은 다양한 상품 및 컨텐츠의 등장
- Few Popular Items → Long Tail Phenomenon
- Long Tail Phenomenon: 아주 다양한 아이템이 Long Tail 형태로 분포
- ex. 유튜브 동영상 추천 / SNS 친구 추천 등
추천시스템에 사용하는 데이터
- 유저 관련 정보
- 유저 프로파일링
- 식별자
- 유저 행동 정보
- 데모그래픽 정보 - 직접 받는 것이 가장 정확 but 요즘은 쉽게 제공해주려 하지 않음
⇒ 모델링이나 클러스터링 통해 수정
- 아이템 관련 정보
- 추천 아이템의 종류
- 아이템 프로파일링
- 유저-아이템 상호작용 정보
- Explicit Feedback: 직접적 피드백
- Implicit Feedback: 간접적 피드백
문제 정의
- RecSys의 목적
- 유저에 아이템 추천
- 아이템을 유저에 추천
- 유저와 아이템 간 상호작용을 평가할 score 값이 필요 ⇒ 그렇다면 score는 어떻게 구함?
- 추천 문제: Ranking or Prediction
- Ranking
- 유저에 적합할 Top K개 추천 → 이를 위한 기준 및 점수가 필요함
- score를 매기는 기준은 개인적으로 정의 가능
- 평가지표: Precision@K, Recall@K, MAP@K, nDCG@K
- Prediction
- 아이템에 대한 유저의 선호도를 정확히 예측 → 평점, 클릭 확률, 구매 확률
- Explicit feedback, Implicit feedback
- Explicit: 영화 중, 철수가 시청한 “아이언맨” 영화에 대해 내릴 평점 값 예측
- Implicit: 영희가 핸드폰을 조회하는 도중, 아이폰 12를 조회하거나 구매할 확률 값을 예측
- 평가지표: MAE, RMSE, AUC
- Ranking
추천시스템 평가
개요
- 크게 두 가지 관점에서 추천시스템 모델의 성능을 평가
- 비즈니스 / 서비스 관점
- 상품 매출 증가
- PV(Page View) 증가
- 유저의 CTR 증가
- 품질 관점
- Relevance → “추천된 아이템이 유저에게 관련이 있는가?”
- Diversity → “추천된 Top-K 아이템이 얼마나 다양한 아이템에 추천되는가?”
- Novelty → “얼마나 새로운 아이템이 추천되고 있는가?”
- Serendipity → “유저가 기대하지 못한 뜻밖의 아이템이 추천되는가?”
- 비즈니스 / 서비스 관점
Offline Test vs Online Test
- Offline Test
- 새로운 추천모델 검증을 위한 최우선 수행 단계
- 여러 유저들의 데이터를 수집하여 → train/test/valid로 나누어 → 객관적인 모델 성능 평가
- 보통 Offline Test 먼저 → 이후 Online 서빙에 투입
- 하지만, 실제 서비스 상황에서는 다양한 양상이 나타남 → “Serving Bias”
- 새로운 추천모델 검증을 위한 최우선 수행 단계
- Online Test
- Offline에서 검증된 가설 및 모델을 이용해 실제 추천 결과 서빙
- RecSys 변경 전후의 성능비교가 아닌, 대조군과 실험군의 성능을 동시에(최대한 환경을 동일하게) 평가
- 실제 서비스를 통해 얻어지는 결과로 최종 의사결정 이루어짐
-
현업 내 의사결정에 사용하는 최종 지표: 모델의 성능보다 비즈니스 및 서비스 지표 활용(매출, CTR 등)
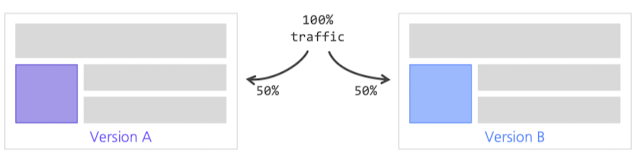
Serving Bias
- Offline Test를 거친 모델이더라도, Online 환경에서는 다르게 작동할 수 있음
- 이러한 Offline Test와 Online Test 간 차이를 Serving Bias라고 함
- RecSys 모델 학습 Flow
- Offline Test
- ML에서 모델을 테스트 및 평가하는 것과 동일
- 고정된 데이터셋(Train, Test, Valid)로 나누어 모델을 학습 및 평가를 진행
- Offline에서 성능이 우수하게 나온 모델이 실제로도 Online에 투입됨.
- Online Test
- Online에서도 동일하게, 추천된 결과를 유저에게 전달하고 피드백을 받아 모델을 재학습시킴.
- 차이점: 일방적 학습을 통해 만들어진 모델이 아닌, 유저와의 쌍방 피드백을 통해 재학습하고 모델을 발전시켜나감 → 이 과정에서 발생하는 것이 Serving Bias
- Offline Test
평가지표 종류
- 랭킹 문제
- Precision@K, Recall@K, MA@К, NDCG@K, Hit Rate
- 예측 문제
- RMSE, MAE 등
- 평가지표 상세
- Precision@K / Recall@K
- Precision@K
- 모델이 추천한 K개의 아이템 중, 실제 유저가 관심있는 아이템의 비율
- 실제 유저가 관심있는 아이템 / 추천한 K개 아이템
- Recall@K
- 유저가 관심있는 전체 아이템 중에, 모델이 추천한 아이템의 비율
- 추천한 아이템 / 유저가 관심있는 전체 아이템
- Precision@K
- Mean Average Precision(MAP) @K
- Precision/Recall에서 K개 아이템의 순서가 지표에 반영
- AP@K - 유저 “1명”에 대한 값
- 유저 1명에 대한 평균값
- Precision@1 ~ Precision@K
- MAP@K - 유저 “N명”에 대한 값
- 모든 유저에 대한 AP@K 값의 평균
- Normalized Discounted Cumulative Gain (NDCG)
- 추천시스템에서 가장 많이 사용되는 지표 중 하나
- Top K 리스트 만들어, 유저가 선호하는 아이템을 비교하여 구한 값
- 추천의 순서에 가중치를 더 많이 둠
- MAP@K처럼, 1에 가까울 수록 좋음
- NDCG Formula
- Cumulative Gain(CG)
- 상위 K개 아이템에 대하여, 관련도를 합한 것
- 순서에 따라 Discount 없이 동일하게 더한 값
- $CG_k = \sum_{i=1}^{K}rel_i$
- Discounted Cumulative Gain(DCG)
- 순서에 따라 CG를 Discount함
- $DCG_k = \sum_{i}^{K} \frac{rel_i}{\log_2{(i+1)}}$
- Ideal DCG
- 이상적인 추천이 일어났을 때의 DCG값
- 가능한 DCG값 중 최대
- $IDCG = \sum_{i}^{K} \frac{rel_i^{opt}}{\log_2{(i+1)}}$
- Normalized DCG
- 추천결과에 따라, 구해진 DCG를 IDCG로 나눈 값
- $NDCG = \frac{DCG}{IDCG}$
- Cumulative Gain(CG)
- Example → “NDCG@5 구하기”
- Relevance의 내림차순으로 정렬하는 것이 이상적
- NDCG@5 구하기
- 주어진 정보
- Ideal Order: [C(3), A(3), B(2), E(2), D(1)]
- Recommend Order: [E, A, C, D, B]
- 실제 추천(DCG@5) : E(2) → A(3) → C(3) → D(1) → B(2) 순으로 추천
- $DCG@5 = \frac{2}{\log_2{(1+1)}} + \frac{3}{\log_2{(2+1)}} + \frac{3}{\log_2{(3+1)}} + \frac{1}{\log_2{(4+1)}} + \frac{2}{\log_2{(5+1)}} = 6.64$
- Ideal 추천(IDCG@5) : C(3) → A(3) → B(2) → E(2) → D(1) 순으로 추천
- $IDCG@5 = \frac{3}{\log_2{(1+1)}} + \frac{3}{\log_2{(2+1)}} + \frac{2}{\log_2{(3+1)}} + \frac{2}{\log_2{(4+1)}} + \frac{1}{\log_2{(5+1)}} = 7.14$
- 최종 NDCG@5
- $NDCG@5 = \frac{DCG}{IDCG} = \frac{6.64}{7.13} = 0.93$
- 주어진 정보
- Precision@K / Recall@K
인기도 기반 추천
개요
- 정말 말그대로, 가장 인기있는 아이템을 추천하는 것
- ML이 아닌, 통계적으로 많은 사용자들의 선택을 받은 아이템 추천
- 인기도의 척도: 조회수, 평균평점, 리뷰 갯수, 좋아요/싫어요 갯수 등
- 서비스 초기 구축 시 많이 활용
- ML이 아닌, 통계적으로 많은 사용자들의 선택을 받은 아이템 추천
- 인기도 추천 방식 분류
- Most Popular - 조회수가 가장 많은 아이템 추천
- Highly Rated - 평균 평점이 가장 높은 아이템 추천
Most Popular
- Score Formula
- 추천 or 좋아요 갯수 기준 추천
-
ex) 뉴스 추천 → 뉴스의 가장 중요한 속성은 최신성
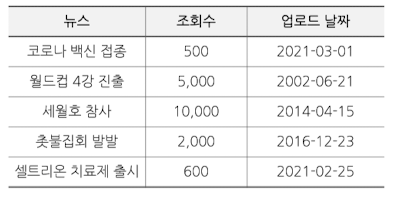
- $score = f(popularity, age)$
- score = (upvote - downvote) - time_elasped
= pageviews - time_elasped- ex) 10 pageviews / 6 hours ago ⇒ 10 - 6/4 = 8.5
- pageview가 더 빠르게 늘어난다면? ⇒ 1~2년이 지나도, 오래되더라도 같은 글이 계속 Top Rank에 나타날 것
- score = (upvote - downvote) - time_elasped
- $score = f(popularity, age)$
- Hacker News Formula
- $score = \frac{pageviews - 1}{(age+2)^{gravity}}$
- 시간이 지날수록 age 증가 → score 작아짐
- 상수 gravity(=1.8)를 이용하여 score 보정
- 아무리 pageview가 높아도, score는 거의 0에 수렴
- $score = \frac{pageviews - 1}{(age+2)^{gravity}}$
- Reddit Formula
- $score = \log_{10}{(ups-downs)} + \frac{sign(ups-downs) \cdot seconds}{45000}$
- score = popularity + 절대시간(Seconds: 최신 포스팅에 가점 부여)
- 첫번째 vote에 가장 높은 가치 부여
- vote 값이 늘어날수록 score 증가폭 작아짐
Highly Rated
- Score Formula
-
가장 높은 평점을 받은 아이템(영화 혹은 맛집) 추천
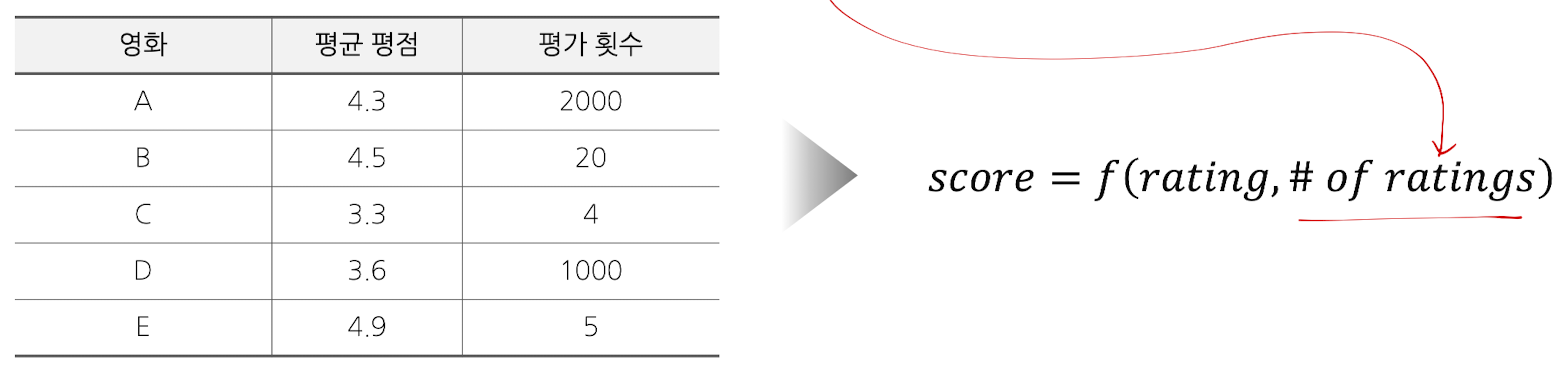
- 신뢰할 수 있는 평점인가? 판별
- 평가의 갯수가 충분한가?(#of ratings) 판별
-
- Steam Rating Formula
-
게임 플랫폼 Steam에서 활용되는 추천 방법
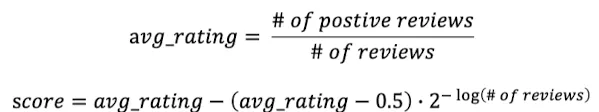
- score: 실제 사용 점수
- rating은 평균값 사용
- “# of reviews”에 따라 rating 보정
- review 갯수가 너무 적을 경우 → 0.5보다 score가 낮을 경우 조금 높게, 높을 경우 조금 낮게 보정
- review 갯수가 아주 많을 경우 → score는 평균 rating과 거의 유사(Second term이 0으로 수렴)
-
Movie Rating에 적용
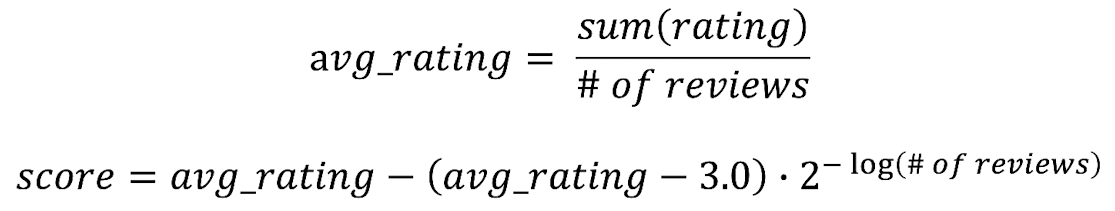
- 영화 평점은, positive/negative가 아닌 1.0~5.0의 rating 사용
- 3.0 대신 모든 평점 데이터의 평균값 사용 가능
- 역시 #of reviews 많아질 수록 평균 rating에 가까워짐
-
chat_bubble 댓글남기기
댓글남기기