연관분석(Association Analysis)
개요
- 추천시스템의 가장 고전적인 방법론
- 연관규칙(Association Rule), 탐색 알고리즘
연관 규칙 분석(Association Rule Analysis, 장바구니 분석 / 서열 분석)
- 하나의 연속된 거래들 사이의 규칙 발견을 위해 적용(상품의 구매, 조회 등)
- 주어진 거래에 대해, 하나의 상품이 등장했을 때 다른 상품과 같이 등장하는 규칙을 찾는 것
-
ex) 아래와 같이, 5개의 거래 기록이 있음
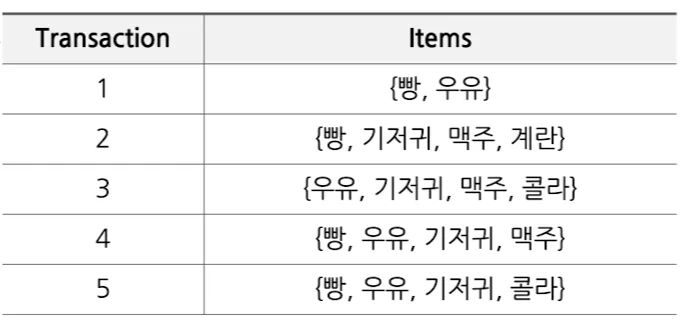
- 연관규칙의 예시
- {기저귀}를 구매할 때 → {맥주}를 구매한다
- {우유, 빵}을 구매할 때 → {계란, 콜라}를 구매한다
- {맥주, 빵}을 구매할 때 → {우유}를 구매한다
- 화살표가 인과관계를 의미하는 것은 아님, 같은 거래 안에 상호 제품이 같이 등장하는 가에 관한 여부
- 연관규칙의 예시
-
연관 규칙
- 규칙 vs 연관규칙
- 규칙: IF (condition) → THEN (result)
- 연관 규칙(Association Rule): 특정 사건 발생 시, 함께 빈번히 발생하는 또 다른 사건의 규칙
- Itemset: IF와 THEN을 각각 구성하는 상품들의 집합(서로소 만족)
-
빈발 집합(Frequent Itemset)
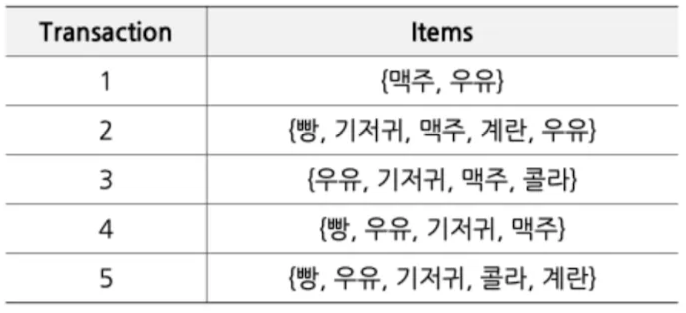
- itemset: 1개 이상의 item 집합(set)
- support count($\sigma$)
- 전체 transaction data에서 itemset이 등장하는 횟수
- ex) $\sigma$({빵, 우유}) = 3 → Transaction 2,4,5에서 등장
- support
- 전체 transaction에서 해당 itemset이 등장하는 비율
- ex) support({빵, 우유}) = 3 / 5 = 0.6
- frequent itemset (↔infrequent itemset)
- minimum support(유저가 직접 지정)값 이상의 itemset
연관 규칙의 척도
- support, confidence, lift
- Frequent itemset 사이의 연관규칙 → measurement 필요!
- $X$ → $Y$가 존재할 경우 ($X$, $Y$: itemset, $N$: transaction 갯수)
- 연관규칙 척도 상세
- Support
- 전체 거래(transaction, $N$) 중, 특정 아이템셋($X$, $Y$)이 얼마나 자주 등장하는지에 대한 비율
- X와 Y의 교집합
- 목적
- 전체 N개의 transaction에 대해 해당 아이템셋(X, Y)의 빈도 측정 → 자주 발생하는 패턴 확인
- 불필요한 연산을 줄일 때
- 수식
- 아이템셋 개별 정의
- $s(X) = \frac{n(X)}{N} = P(X)$
- 연관규칙 정의
- $s(X \rightarrow Y) = \frac{n(X \cup Y)}{N} = P(X \cap Y)$
- “동시에 등장할 확률”
- 아이템셋 개별 정의
- 전체 거래(transaction, $N$) 중, 특정 아이템셋($X$, $Y$)이 얼마나 자주 등장하는지에 대한 비율
- Confidence
- $X$가 발생한 거래 중, $Y$가 발생한 거래의 비율 → 높을 수록 유용한 규칙
- $X$에 대한 $Y$의 조건부 확률
- 목적
- 연관 규칙의 신뢰도를 평가 ($X$ 발생 시, $Y$가 발생할 가능성 측정)
- 값이 높을수록, $X$가 $Y$의 발생을 잘 예측함
- 수식
- $c(X \rightarrow Y) = \frac{n(X \cup Y)}{n(X)} = \frac{s(X \rightarrow Y)}{s(X)} = \frac{P(X \cap Y)}{P(X)} = P(Y \vert X)$
- $X$가 발생한 거래 중, $Y$가 발생한 거래의 비율 → 높을 수록 유용한 규칙
- Lift
- “$X \rightarrow Y$”가 발생할 확률이, $Y$가 독립적으로 발생할 확률과 비교하여 얼마나 더 큰지
- Confidence / $Y$ 등장 확률
- 목적
- $X$, $Y$가 독립인지 종속인지 확인 ($l$ : lift)
- $l = 1$ : $X$, $Y$는 독립
- $l > 1$ : $X$, $Y$가 양의 상관관계
- $l < 1$ : $X$, $Y$가 음의 상관관계
- $X$, $Y$가 독립인지 종속인지 확인 ($l$ : lift)
- 수식
- $l(X \rightarrow Y) = \frac{P(Y \vert X)}{P(Y)} = \frac{P(X \cap Y)}{P(X)P(Y)} = \frac{s(X \rightarrow Y)}{s(X)s(Y)} = \frac{c(X \rightarrow Y)}{s(Y)}$
- $l(X→Y)=\frac{confidence(X→Y)}{support(Y)}$
- “$X \rightarrow Y$”가 발생할 확률이, $Y$가 독립적으로 발생할 확률과 비교하여 얼마나 더 큰지
- Support
- 연관 규칙 활용에서, Support / Confidence / Lift 사용방법
- Item 숫자가 많아질 수록, 가능한 itemset에 대한 연관 규칙의 숫자가 기하급수적으로 늘어남
- 사용방법
- minimum support / confidence로 의미 없는 연관규칙 screen out
- 전체 transaction 중, 너무 적게 등장하거나 조건부 확률이 아주 낮은 rule 필터링
- Lift 값으로 내림차순 정렬 → 의미 있는 연관규칙이 무엇인지 평가
- Lift값이 크다는 것은, 곧 해당 연관규칙을 구성하는 antecedent ($X→Y$에서 $X$)및 consequent($X→Y$에서 $Y$)가 연관성이 높고 유의미하다는 뜻
- minimum support / confidence로 의미 없는 연관규칙 screen out
연관 규칙 탐색
- Mining Association Rules
- 주어진 transaction 중, 아래 조건을 만족하는 가능한 모든 연관 규칙 찾기
- support ≥ minimum support
- confidence ≥ minimum confidence
- 위 조건을 만족하는 모든 연관 규칙을 찾는 알고리즘? → “Brute-force Approach”
- 가능한 모든 연관 규칙 나열
- 모든 연관 규칙에 대해, 각 개별로 support 및 confidence 계산
- minimum support, confidence를 만족하는 규칙들만 남기고 전부 제거
- ex) 개별 transaction의 아이템을 모두 확인 → 모든 itemset의 support값을 계산
- $Complexity \sim O(NWM)$, $M=2^d$ ($d$: “# of unique items”)
- 가장 큰 문제는 “$M$” → $d$(unique item)값의 증가에 따라, $M$값이 기하 급수적으로 증가 → 제한 시간 내 의미있는 연관규칙을 찾아내는 것이 거의 불가능
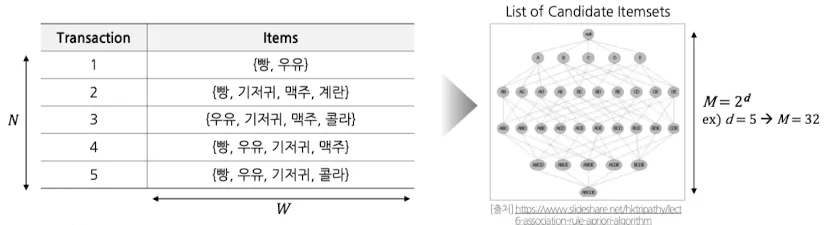
- 효율적인 Association Rule Mining을 위한 두 가지 스텝
- **Frequent itemset Generation → 이 단계에서 발생하는 task의 computation cost가 중요 **
- minimum support 이상의 모든 itemset 생성
- 이 단계에서, 효율적인 계산을 수행하는 것이 가장 중요
- 가능한 후보 itemset($M$)의 갯수 줄이기
- 완전 탐색: $M=2^d$
- Apriori 알고리즘(가지치기 활용, 탐색해야 하는 $M$의 갯수 줄임)
- 탐색하는 transaction($N$)의 숫자 줄이기
- itemset의 크기가 커짐에 따라, 전체 $N$개 transaction보다 적은 갯수 탐색
- DHP(Direct Hashing & Pruning) 알고리즘
- 탐색 횟수($NM$) 줄이기
- 효율적 자료구조 활용 → 후보 itemset 및 transaction을 저장
- 모든 itemset과 transaction 조합에 대해 탐색하지 않아도 됨
- FP-Growth 알고리즘
- 가능한 후보 itemset($M$)의 갯수 줄이기
- Rule Generation
- minimum confidence 이상의 association rule 생성
(단, rule을 이루는 antecedent 및 consequent는 서로소 만족)
- minimum confidence 이상의 association rule 생성
- **Frequent itemset Generation → 이 단계에서 발생하는 task의 computation cost가 중요 **
- 주어진 transaction 중, 아래 조건을 만족하는 가능한 모든 연관 규칙 찾기
TF-IDF를 활용한 콘텐츠 기반 추천
개요
- 텍스트 데이터를 다루는 가장 기본적인 방법 → 문서에서 단어의 중요도를 측정하는 통계적 방법
- 컨텐츠 기반 추천 (Contents-based Recommendation)
-
임의의 유저 $x$에게, 해당 유저가 과거에 선호한 아이템과 비슷한 아이템을 추천
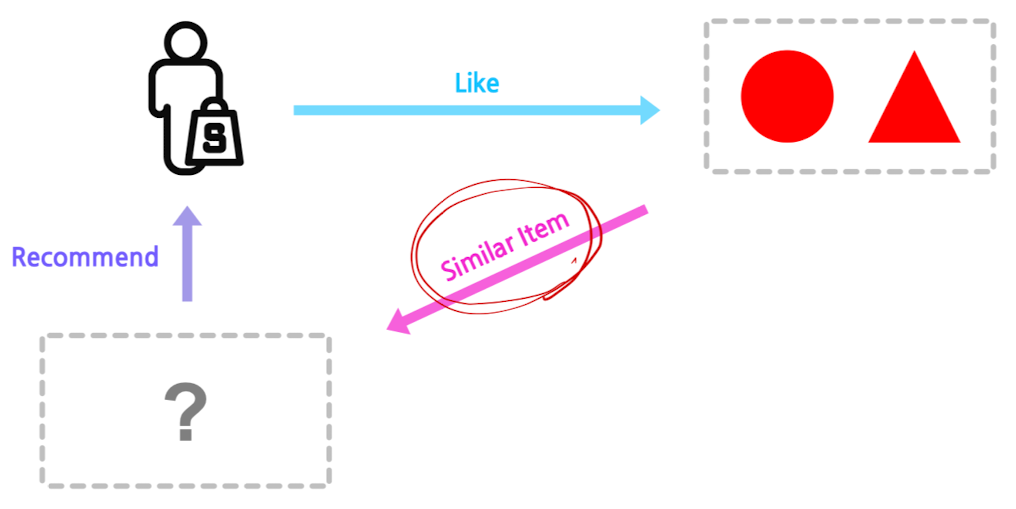
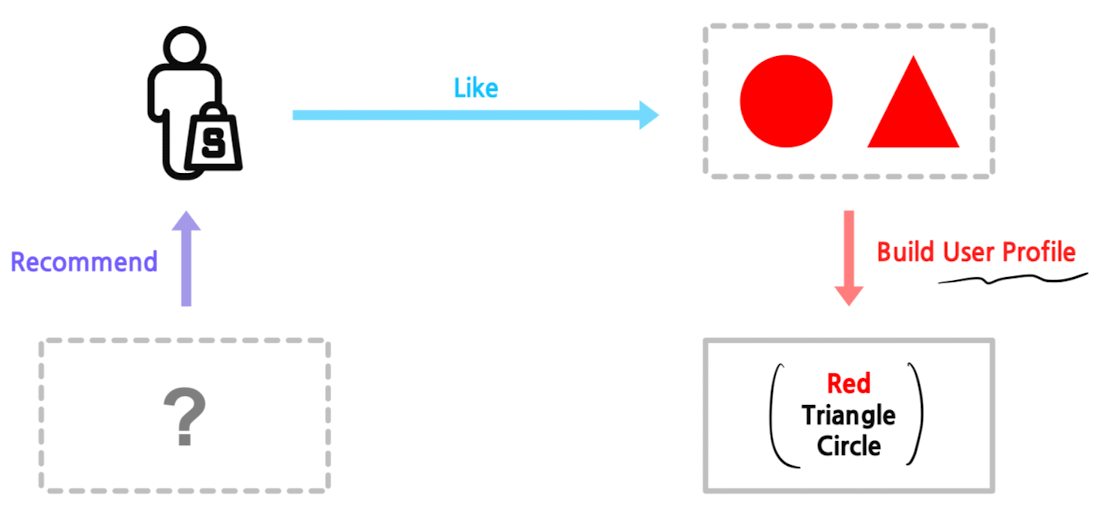
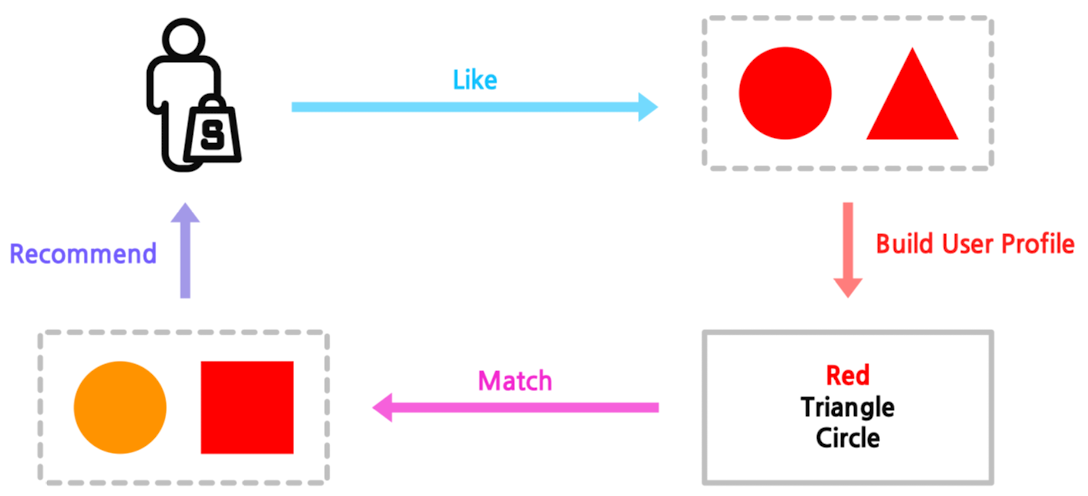
-
- 장점
- 다른 유저의 데이터가 필요하지 않음
- 새로운 아이템 / 인기도가 낮은 아이템 추천 가능 (CF 모델에 비한 장점)
- 추천의 이유를 설명 가능함
- 단점
- 아이템에 대한 적합한 feature를 찾는 것이 어려움
- 동일한 분야 및 장르의 추천만 계속 나옴
- 타 유저 데이터 활용 불가
Item Profile
- 추천 대상이 되는 아이템의 feature로 구성
- Vector 형태로 편리하게 표현 ⇒ 아이템이 지닌 다양한 feature를 표현하기 가장 편한 방법
- 하나의 feature가 1개 이상의 vector dimension에 표현
- 이진값 혹은 실수값
- Vector 형태로 편리하게 표현 ⇒ 아이템이 지닌 다양한 feature를 표현하기 가장 편한 방법
- TF-IDF for Text Feature
- 문서는, 중요한 단어들의 집합
- 이렇게, 문서 안에 포함된 중요한 단어들에 스코어를 매겨서 단어에 대한 중요도를 표현
- 이때, 가장 많이 활용하는 방법이 TF-IDF
- TF-IDF(Term Frequency - Inverse Document Frequency)
- TF (Term Frequency)
- 정의
- 문서 d에 단어 w가 등장하는 횟수
- “특정 단어가 한 문서에서 얼마나 자주 등장했는가”
- 수식
- $TF(t,d) = \frac{f(t, d)}{n(d)}$
- $f(t, d)$: 특정 단어 t가 문서 d에서 등장한 횟수
- $n(d)$: 문서 d의 전체 단어 수
- 예시
- 문서 d: “the cat sat on the mat”
- 단어 t: “cat”
- $f(t, d) = 1, n(d) = 6$
- $TF(cat, d) = \frac{1}{6}$
- 정의
- IDF (Inverse Document Frequency)
- 정의
- 전체 문서 가운데 단어 w가 등장한 비율의 역수
- “특정 단어가 여러 문서에서 얼마나 드물게 등장했는가”
- 수식
- $IDF(t, D) = \log{\frac{N}{1 + df(t)}}$
- IDF값의 변화가 크기 때문에, smoothing을 위해 Log 사용
- $N$ : 전체 문서의 수
- $df(t) + 1$ : 특정 단어 t가 등장한 문서의 수 (Document Frequency)
- 1을 더해 분모가 0이 되는 것을 방지\
- $IDF(t, D) = \log{\frac{N}{1 + df(t)}}$
- 특징
- 자주 등장하는 단어(“the”, “is”, “on” 등)는 중요도 낮음
- 특정 문서에서만 등장하는 단어가 중요도 높음
- 예시
- 전체 문서 $N=10$
- “cat”이 등장한 문서의 수 $df(cat)=2$
- $IDF(cat, D) = \log{\frac{10}{1 + 2}} = \log{\frac{10}{3}} \approx 0.477$
- 정의
- TF-IDF
- 추천 알고리즘에서의 활용
- 문서 간 유사도를 기반으로 추천
- 수식
- $TF\text{-}IDF(t, d, D) = TF(t, d) \times IDF(t, D)$
- 예시
- $TF(cat,d)=0.167$
- $IDF(cat,D)=0.477$
- $TF\text{-}IDF(cat,d,D)=0.167×0.477≈0.0798$
- 특징
- 높은 TF-IDF
- 해당 단어가 특정 문서에서는 많이 등장하지만, 다른 문서에서는 드물게 등장함.
- 이 단어는 문서를 대표하는 중요한 단어일 가능성이 높음.
- 낮은 TF-IDF
- 해당 단어가 모든 문서에서 자주 등장하거나, 특정 문서에서 거의 등장하지 않음.
- 이 단어는 문서를 대표하지 않으며, 중요도가 낮음.
- 높은 TF-IDF
- 한계점
- 문맥 정보 부족
- 단어의 순서나 문맥을 고려하지 않음.
- ex) “apple”이라는 단어가 기술 문서와 음식 문서에서 다르게 쓰일 수 있음.
- 동의어 문제
- 유사한 의미의 단어를 다르게 처리
- ex) “car”와 “automobile”은 같은 의미지만 별개의 단어로 처리됨
- 희소 표현
- 대규모 문서 집합에서 계산된 TF-IDF 행렬은 매우 희소(Sparse)하게 나타남
- 문맥 정보 부족
- TF (Term Frequency)
- TF-IDF의 적용
-
문서 d에 등장하는 단어 w에 대해, → 단어 w가 문서 d에 많이 등장하며 (TF)
→ 단어 w가 전체 문서 D에는 적게 등장한다면 (IDF)
**⇒ 단어 w는 문서 d를 설명하는 중요한 feature **(=TF-IDF 값이 높음)
-
-
TF-IDF 적용 예시
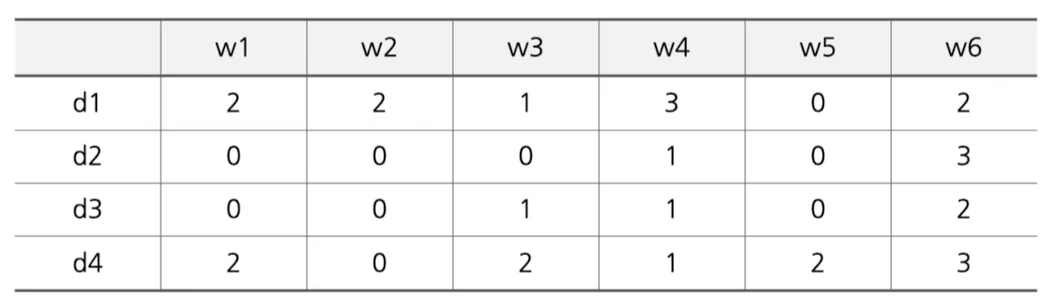
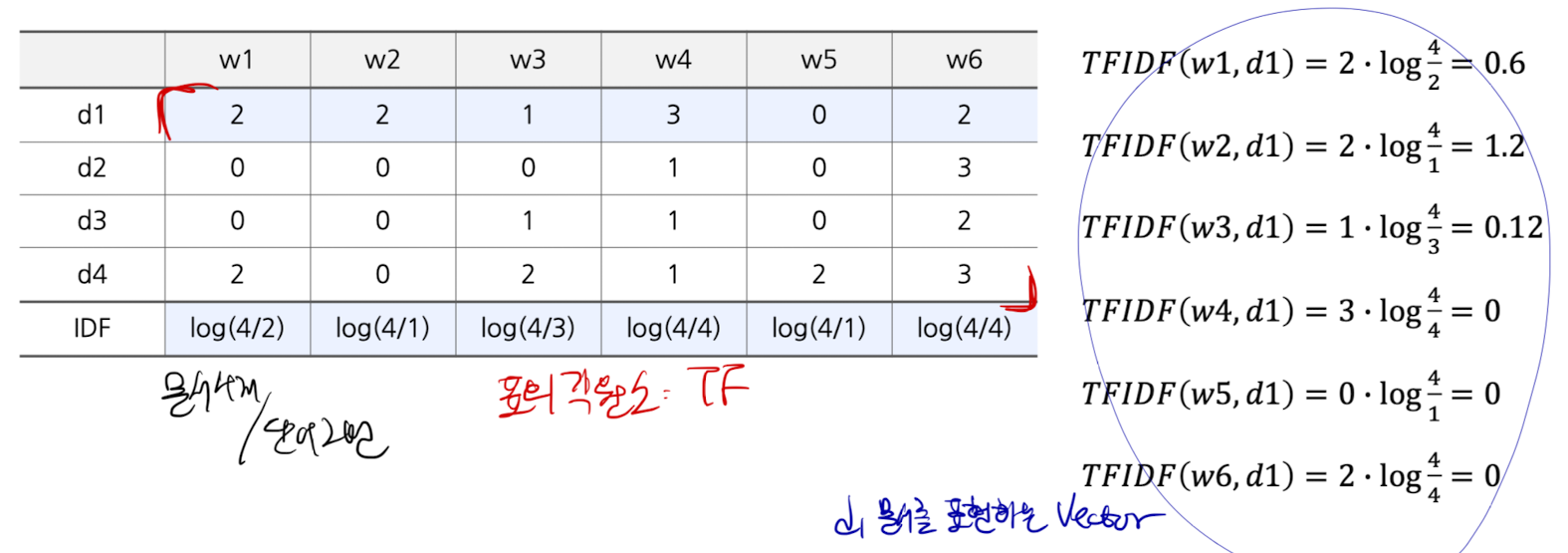
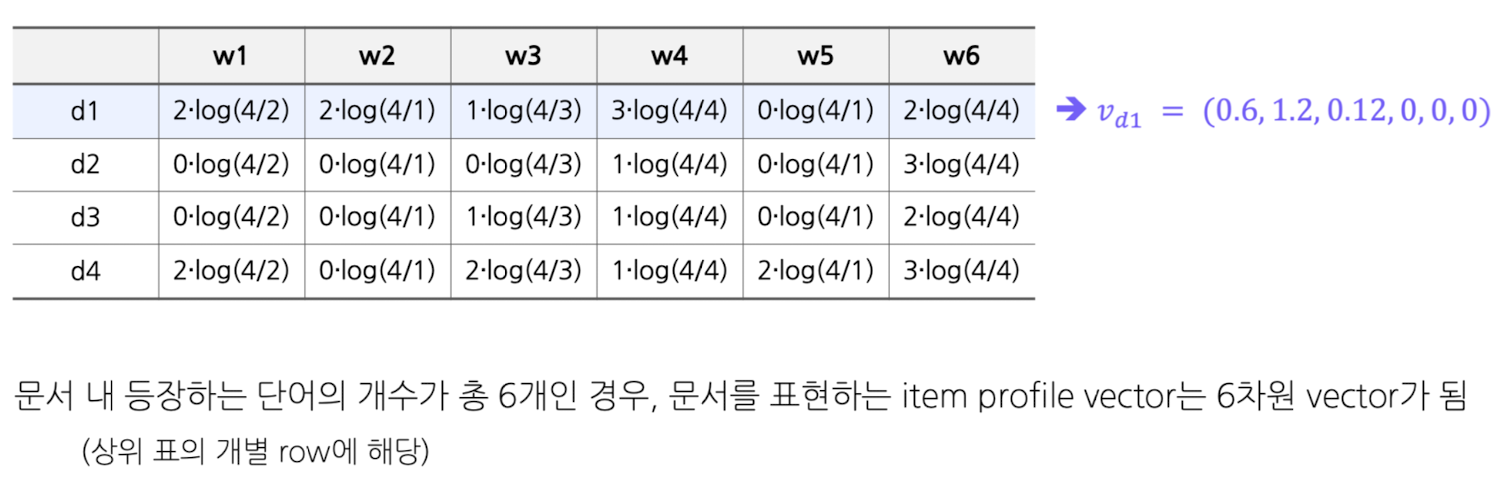
User Profile 기반 추천
- Item Profile을 구축했다면 ⇒ 이제는 유저에게 아이템을 추천해야 함
- 이를 위해, User Profile을 구축해줘야 함
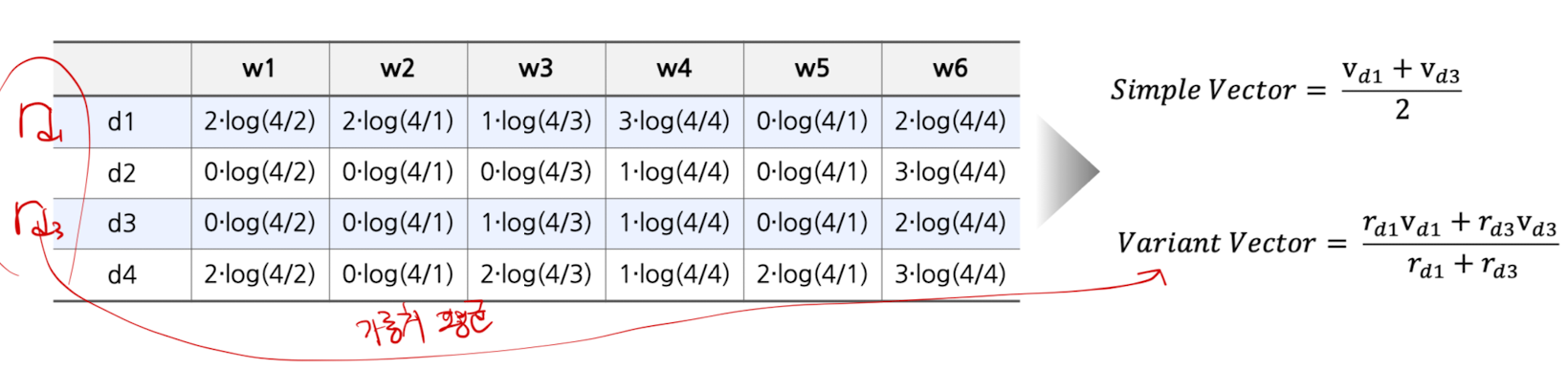
- User Profile
- 각 유저의 Item List, 해당 리스트 안에는 TF-IDF를 통해 표현된 Item Vector들로 구성
- Item Vector들을 통합하여 User Profile 구성
- Simple User Profile: 유저가 선호하는 Item Vector 전체 평균값 사용
- Variant User Profile: 유저가 아이템에 내린 선호도로 정규화한 평균값 사용
-
ex) 만약, 유저가 $d_1$, $d_3$를 선호한다면?
- Cosine Similarity
- 두 벡터의 각도를 활용(Cos 2법칙) → 두 벡터가 가리키는 방향의 유사도 표현
- RecSys에서 가장 많이 활용
- 수식
- $\cos(\theta) = \cos(X, Y) = \frac{X \cdot Y}{\left\vert{X}\right\vert \left\vert{Y}\right\vert} = \frac{\sum_{i=1}^{N} X_i Y_i}{\sqrt{\sum_{i=1}^{N} X_i^2} \sqrt{\sum_{i=1}^{N} Y_i^2}}$
- 활용도
- User vector ↔ item vector 간 거리 계산
- $score(u, i) = cos(u, i) = \frac{u \cdot i}{\left\vert{u}\right\vert \left\vert{i}\right\vert}$
- 유사도 값이 클수록, 해당 아이템이 유저에게 관련성이 높다는 의미
(score 값이 가장 높은 아이템부터 추천)
- 유사도 값이 클수록, 해당 아이템이 유저에게 관련성이 높다는 의미
Rating 예측하기
- 상황 별 Rating 예측하기
- User가 선호하는 item의 벡터정보를 활용하여 정확한 평점 예측
- 유저 $u$가 맞닥뜨린 임의의 아이템 $i^{\prime}$에 대한 평점 예측
- 유저 $u$, 선호하는 아이템 $I = { i_1, \cdots,i_N}$, 아이템 벡터 $V={v_1,\cdots,v_N}$
- 목적
- 평점 $r_{u, i}$ → $i^{\prime}$에 대한 평점 예측
- 평점 예측 과정(추천 과정)
- $i^{\prime}$과 $I$에 속한 아이템 $i$ 간 유사도 계산: 코사인 유사도
- $sim(i, i^{\prime}) = cos(v_i, v_i^{\prime})$
- $sim(i, i^{\prime})$를 가중치로 활용하여 $i^{\prime}$의 평점 추론 → “$r_{u,i}$에 대한 가중평균”
- $prediction(i^{\prime}) = \frac{\sum_{i=1}^N sim(i, i^{\prime} )\cdot r_{u, i}}{\sum_{i=1}^N sim(i, i^{\prime})}$
- $i^{\prime}$과 $I$에 속한 아이템 $i$ 간 유사도 계산: 코사인 유사도
- 유저 $u$가 맞닥뜨린 임의의 아이템 $i^{\prime}$에 대한 평점 예측
- 영화 평점 예측하기
- 특정 유저가 선호한 영화 3개 $m_1, m_2, m_3$에 대한 평점 및 아이템 벡터
- $m_1$
- $r_{m_1} = 3.0, v_{m_1} = [0.2, 0.4, 1.2, 1.5]$
- $m_2$
- $r_{m_2} = 2.5, v_{m_2} = [0.4, 0.7, 0.3, 0.5]$
- $m_3$
- $r_{m_3} = 4.0, v_{m_3} = [0.3, 1.2, 1.0, 1.0]$
- $m_1$
- 평점을 예측하려는 영화 $m_4$의 아이템 벡터 $v_4 = [0.4, 1.4, 3.1, 1.0]$이라면
- $m_4, m_1$간 아이템(영화) 유사도
- $sim(m_4, m_1) = cos(v_{m_4}, v_{m_1}) = 0.83$
- $m_4, m_2$간 아이템(영화) 유사도
- $sim(m_4, m_2) = cos(v_{m_4}, v_{m_2}) = 0.72$
- $m_4, m_3$간 아이템(영화) 유사도
- $sim(m_4, m_3) = cos(v_{m_4}, v_{m_3}) = 0.88$
- $m_4, m_1$간 아이템(영화) 유사도
- 최종 예측 평점 $prediction(m_4)$ → “$m_4$에 대한 가중평균”
- $prediction(m_4) = \frac{0.83\cdot3.0 + 0.72 \cdot 2.5 + 0.88 \cdot 4.0}{0.83 + 0.72 + 0.88} = 3.2$
- 특정 유저가 선호한 영화 3개 $m_1, m_2, m_3$에 대한 평점 및 아이템 벡터
- User가 선호하는 item의 벡터정보를 활용하여 정확한 평점 예측
chat_bubble 댓글남기기
댓글남기기