Collaborative Filtering (CF)
CF 문제 정의
- CF란?
- 많은 유저들로부터 얻은 기호 정보 기반
- 유저 관심사를 자동으로 예측하는 기법
- 가정: “집단적 협업” - 유저 및 아이템이 많을 수록, 협업의 효과는 커지고 추천은 정확해질 것
- 예시: 노트북을 본 유저가
- 함께 본 다른 상품 추천
- 노트북을 구매한 유저들이 구매한 다른 상품 추천
- 예시: 노트북을 본 유저가
- 가정: “집단적 협업” - 유저 및 아이템이 많을 수록, 협업의 효과는 커지고 추천은 정확해질 것
- CF 기반 추천시스템
- 최종 목적 : “유저 u가 아이템 i에 부여할 평점 예측”
- 구성 방법
- 주어진 데이터로 유저-아이템 행렬 생성
- 이 때, 생성한 유저-아이템 행렬은 대체로 sparse한 경향을 띔 → 이를 CF 과정의 반복을 통해 보완해 나가는 것이 목표
- 유사도 기준을 정함 → 이를 기반으로 유저(or 아이템) 간 유사도 측정
- 주어진 평점 및 유사도 활용 → 행렬의 비어있는 값(평점) 예측
- 주어진 데이터로 유저-아이템 행렬 생성
- 구성 방법
- 최종 목적 : “유저 u가 아이템 i에 부여할 평점 예측”
CF 원리
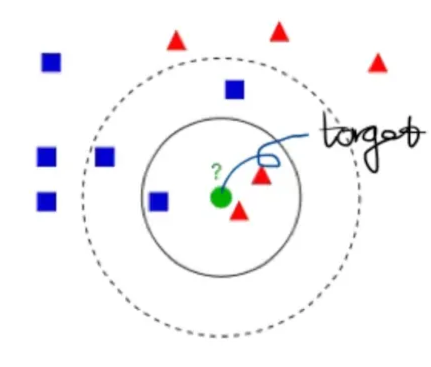
- 핵심 → 유저 A와 비슷한 취향을 지닌 유저들이 선호하는 아이템을 추천
- ex) 유저 A에게 아이템을 추천하는 상황
-
A, B는 서로 유사한 취향을 지닌 유저
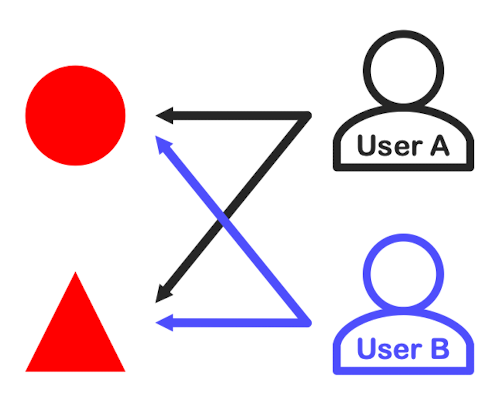
-
유저 B가 좋아하는 아이템(하늘색 사각형)은 유저 A에게 추천함
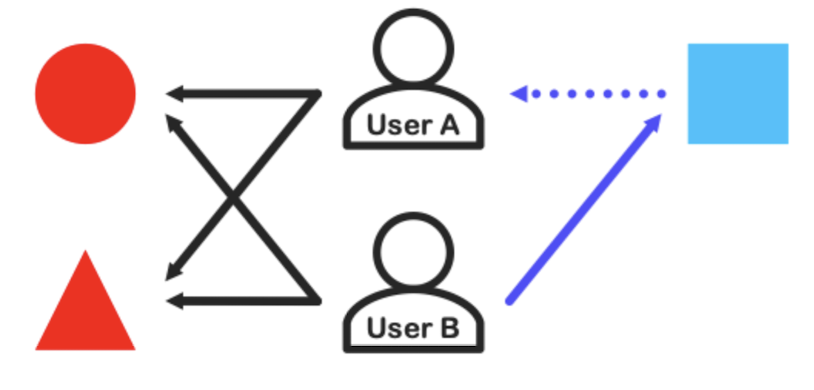
-
유저 B가 좋아하지 않는 아이템(노란색 원)은 유저 A에게도 추천하지 않음
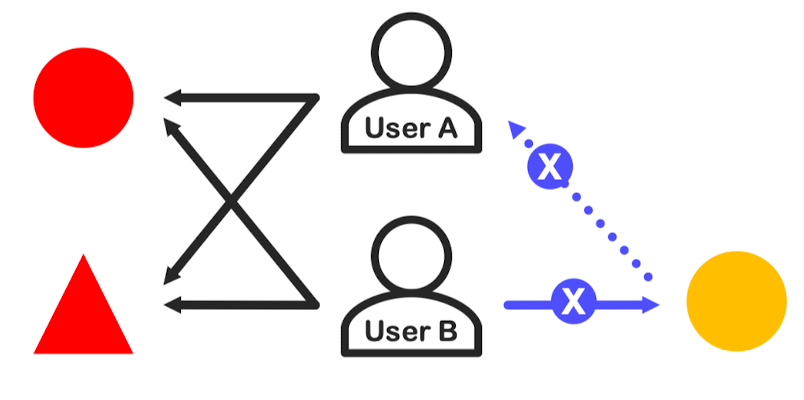
-
이렇게 CF를 활용하면, 아이템이 지닌 속성을 사용하지 않고도 높은 추천 성능을 만들어줄 수 있음
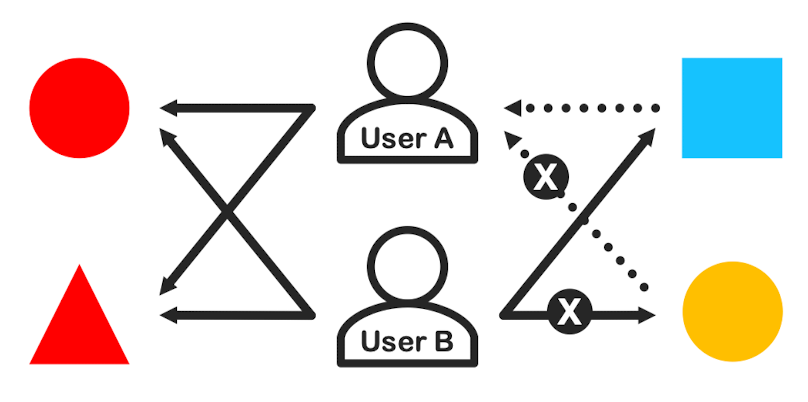
-
- ex) 유저 A에게 아이템을 추천하는 상황
CF 분류
- Neighborhood-based CF(Memory-based CF, 이웃 기반 협업 필터링) → 이번 포스트 내용
- User-based CF(UBCF)
- Item-based CF(IBCF)
- Model-based CF
- Non-parametric(KNN, SVD)
- MF(Matrix Factorization)
- DL
- Hybrid CF
- Content-based Recommendation와 결합
- 각각의 추천결과 앙상블(현업)
Neighborhood-based CF
User-based CF(UBCF)
- 유저 기반 CF
- 두 유저가 얼마나 유사한 아이템을 선호하는가?
- 유저-아이템 행렬의 row 간 유사도를 통해 추천
- 유저 간 유사도를 구한 후(row간 유사도)
- 타겟 유저와 유사도가 높은 유저의 선호템 추천
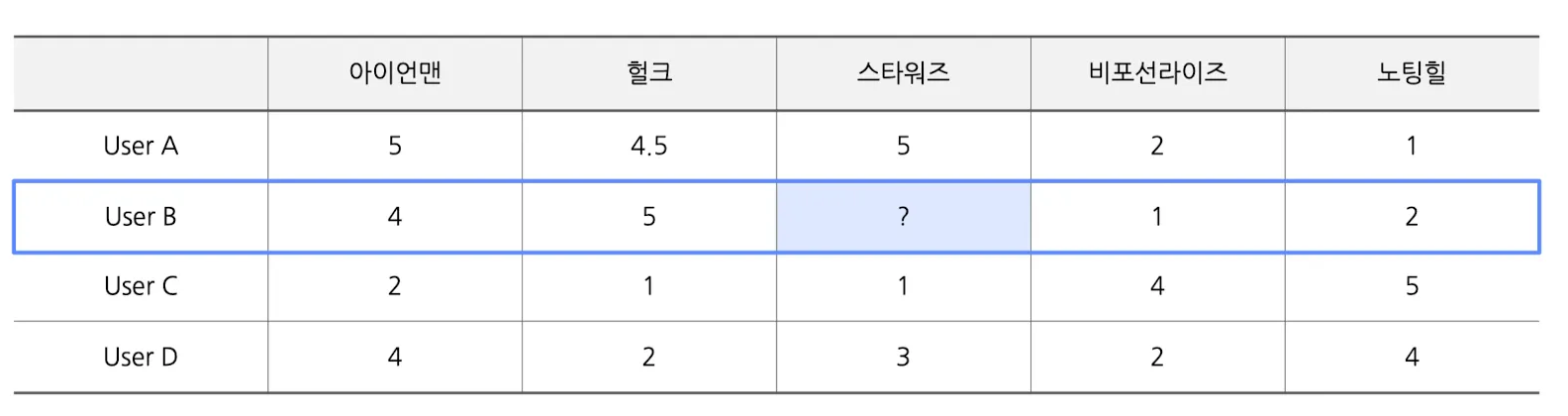
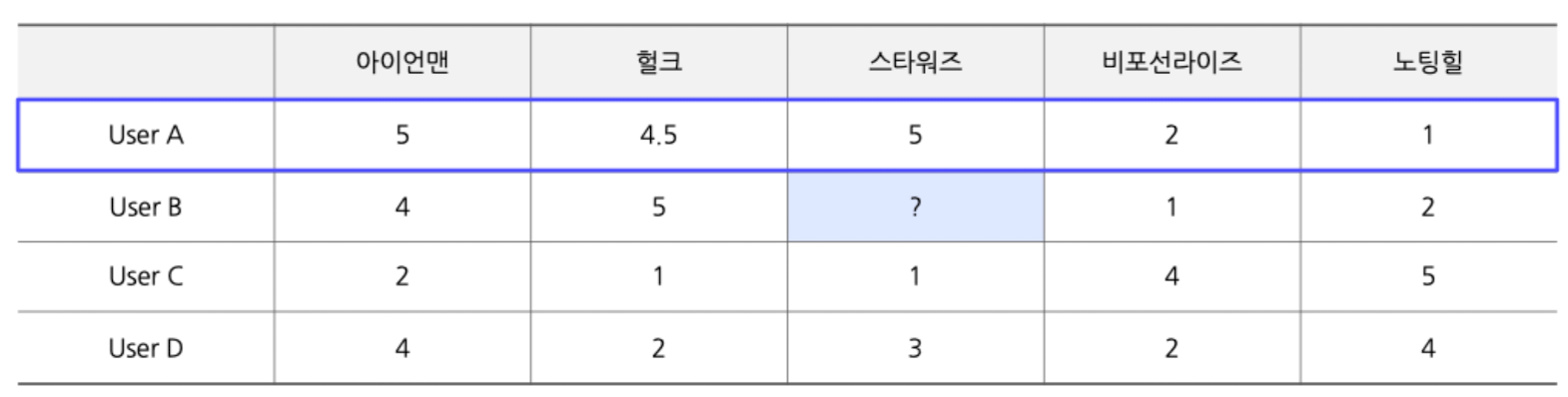
- ex) 아래 표는 유저 A, B, C, D가 관람한 영화에 대한 선호도를 표현한 데이터
- 직관적으로 B와 유사한 유저는 A
- A, B간 유사도가 높음(Highly correlated)
- “유저 B는 유저 A와 유사하게 스타워즈에 대한 선호도는 높을 것” 추측 가능 → 추천 결과로
Item-based CF(IBCF)
- 아이템 기반 CF
- 두 아이템이 유저들에게 얼마나 유사한 평점을 받았는가?
- 유저-아이템 행렬의 column간 유사도를 통해 추천
- 아이템 간 유사도 구하고,
- 타겟 아이템과 유사도가 높은 아이템 선택, 그 중 선호도가 큰 아이템 추천
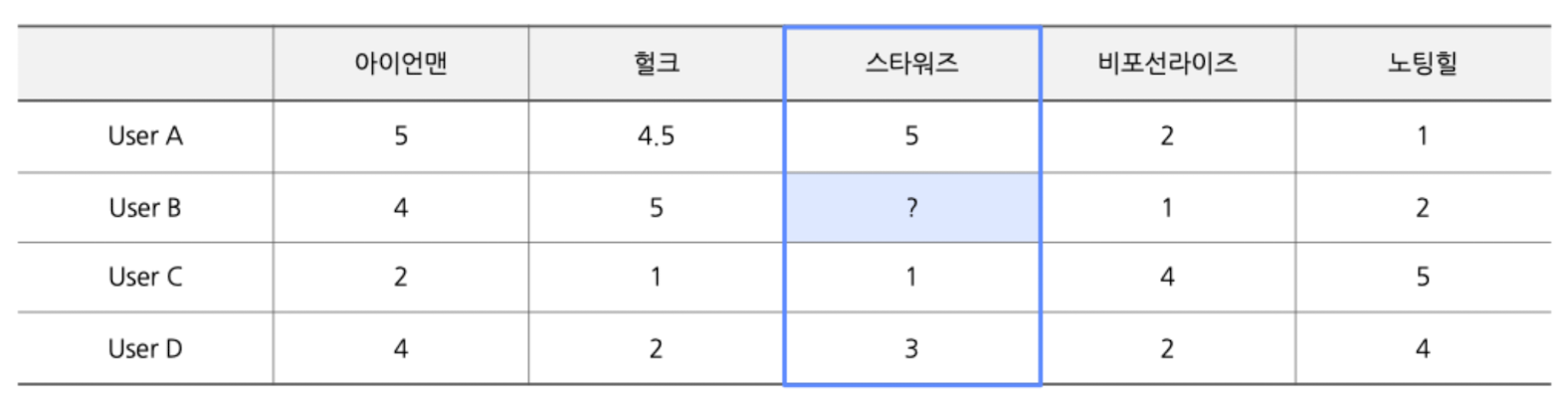
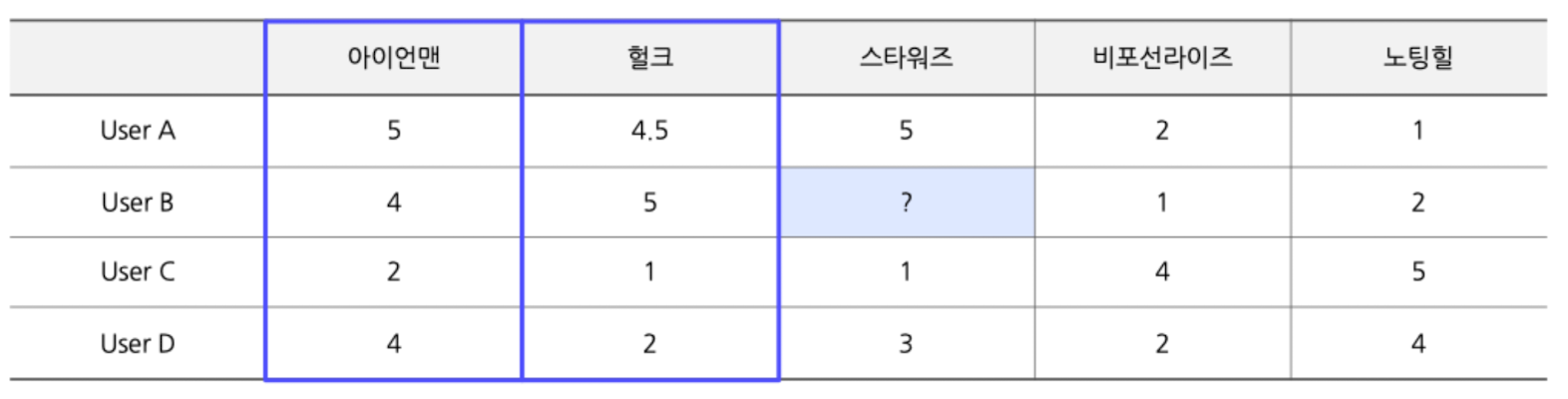
- ex) 위와 동일한 예시를, 아이템을 기준으로 비교해보면
- 스타워즈는 아이언맨, 헐크와 유사도 높음 → 추천 대상
- 또한 스타워즈는 비포선라이즈, 노팅힐과는 유사도 낮음 → 추천 비대상
Neighborhood-based CF(NBCF)
- 최종 목적: 유저 u가 아이템 i에 부여할 평점 예측
- 특징: 구현이 간단, 이해가 쉬움
- Scalability: 아이템이나 유저가 계속 늘어날 경우, 확장성이 떨어짐(차원이 늘어나므로)
- Sparsity
- 주어진 데이터(평점, 선호도)가 적을 경우, 성능 저하
- 실제로, 유저-아이템 행렬의 대부분은 비어 있음 - Sparse Matrix
- Ex. Netflix
- 유저는 100M, 영화는 500k → 유저별 시청한 영화의 갯수는 아무리 많아봐야 수백개 수준
- Ex. Netflix
- NBCF 적용 시, 적어도 Sparsity Ratio는 99.5%가 넘지 않는 것이 좋음
- 이를 만족하지 못하는 경우, Model Based를 사용해야할 정도로 정확성 떨어짐
- Scalability, Sparsity → NBCF뿐 아니라, 추천시스템에서 전반적으로 발생하는 문제
K-Nearest Neighbors CF
K-Nearest Neighbors CF (KNN CF)
- NBCF의 한계
- 아이템 $i$에 대한 평점 예측을 위해 → $\Omega_i$에 속한 모든 유저와의 유사도 구해야 함
- $\Omega_i$: 아이템 $i$에 대해 평가를 수행한 유저의 집합
- 유저가 많아질 수록, 연산은 늘어나고 성능도 떨어지게 됨
- 아이템 $i$에 대한 평점 예측을 위해 → $\Omega_i$에 속한 모든 유저와의 유사도 구해야 함
- KNN CF의 아이디어
- $\Omega_i$에 속한 유저 가운데, 유저 u와 가장 유사한 K명의 유저를 이용해 평점 예측
-
$K$ → 하이퍼파라미터, 일반적으로 25~50 많이 이용
Similarity Measure
- 개요
- 두 개체 간 유사성을 수량화하는 실수값 함수 or 척도
- 여러 정의가 있지만, 일반적으로 거리의 역수 개념 이용
- 종류
- Mean Squared Difference Similarity
- 주어진 유저-아이템 rating에 대해
- 유저
- $msd(u, v) = \frac{1}{\left\vert I_{uv}\right\vert} \cdot \sum_{i \in I_{uv}} (r_{ui} - r_{vi})^2$
- $msd_{sim}(u, v) = \frac{1}{msd(u, v) + 1}$
- 아이템
- $msd(i, j) = \frac{1}{\left\vert I_{ij}\right\vert} \cdot \sum_{i \in U_{ij}} (r_{ui} - r_{uj})^2$
- $msd_{sim}(i, j) = \frac{1}{msd(i , j) + 1}$
- 유저
- RecSys에 주로 사용되는 유사도
- 각 기준에 대한 점수차 계산
- $Similarity \propto Euclidean$
- “가장 유사하다” → MSD = 0, MSD_Sim = 1
- 주어진 유저-아이템 rating에 대해
- Cosine Similarity
- 주어진 두 벡터 $X, Y$에 대해(동일한 차원)
- $\cos(\theta) = \cos(X, Y) = \frac{X \cdot Y}{\left\vert X \right\vert \left\vert Y \right\vert} = \frac{\sum_{i=1}^{N}X_iY_i}{\sqrt{\sum_{i=1}^{N}X_i^2}\sqrt{\sum_{i=1}^{N}Y_i^2}}$
- RecSys서 가장 많이 이용
- 방향성만 반영하는 유사도(두 벡터의 각도 활용)
- 두 벡터의 방향이 얼마나 비슷한지를 나타냄
- 주어진 두 벡터 $X, Y$에 대해(동일한 차원)
- Pearson Similarity
- 주어진 두 벡터 $X, Y$에 대해
- $pearson_sim(X, Y) = \frac{\sum_{i=1}^N (X_i - \overline{X})(Y_i - \overline{Y})}{\sqrt{\sum_{i=1}^N (X_i - \overline{X})^2} \sqrt{\sum_{i=1}^N (Y_i - \overline{Y})^2}}$
- 각 벡터를 표본평균으로 정규화한 뒤, Cosine Similarity 구한 값
- 두 유사도의 크기차이 보정 → 무난한 추천 성능 발휘
- 각 벡터의 rating 크기 차이를 고려할 수 있는 유사도 지표
- 직관적 의미
- (X, Y가 함께 변하는 정도) / (X, Y가 따로 변하는 정도)
- 주어진 두 벡터 $X, Y$에 대해
- Jaccard Similarity
- 주어진 두 집합 $A, B$에 대하여
- $J(A, B) = \frac{\left\vert A \cap B \right\vert}{\left\vert A \cup B \right\vert} = \frac{\left\vert A \cap B \right\vert}{\left\vert A \right\vert + \left\vert B \right\vert - \left\vert A \cap B \right\vert}$
- 집합의 개념을 사용한 유사도
- 두 집합이 같은 아이템을 얼마나 공유하고 있는가를 나타냄
- 모두 같으면 1
- 모두 다르면 0
- 두 집합이 같은 아이템을 얼마나 공유하고 있는가를 나타냄
- 위의 Cosine 및 Pearson 유사도와 달리, 길이(차원)이 달라도 유사도 계산 가능
- 주어진 두 집합 $A, B$에 대하여
- Mean Squared Difference Similarity
Rating Prediction(CF를 이용한 실제 평점 에측)
UBCF
- Absolute Rating
-
문제 - 스타워즈 영화에 대한 User B의 평점을 예측해보자
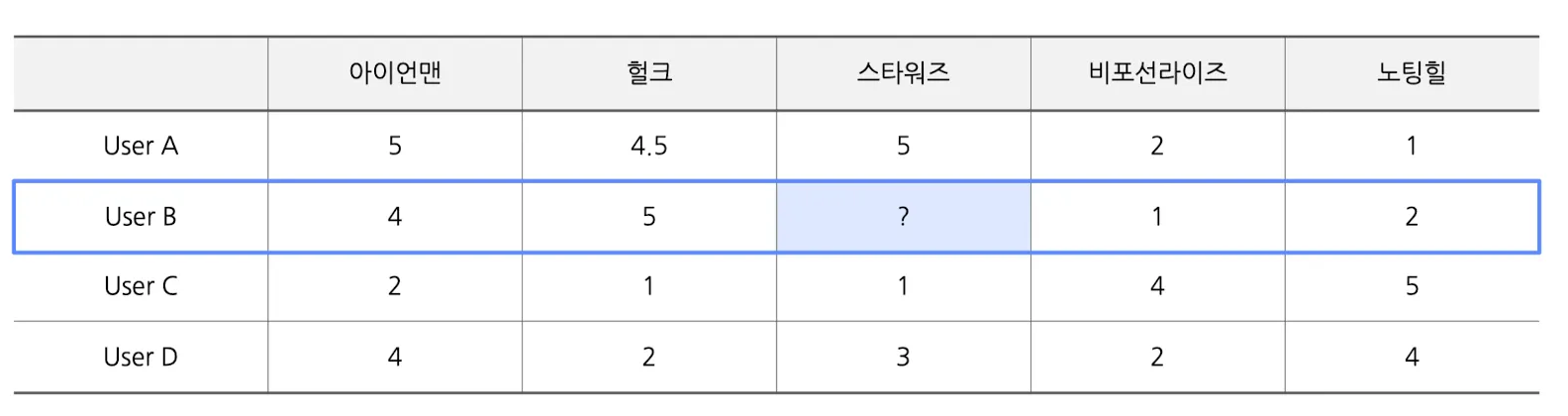
- UBCF를 활용한 예측 과정
- 스타워즈에 대한 다른 유저들의 rating을 평균냄
- 유저 B의 입장에서, 유저 A/C/D의 rating을 반영하는 것은 적절치 못함
- 왜냐? 각각 다른 취향을 지닌 유저이기 때문
-
그렇기 때문에 → Weighted Average 적용
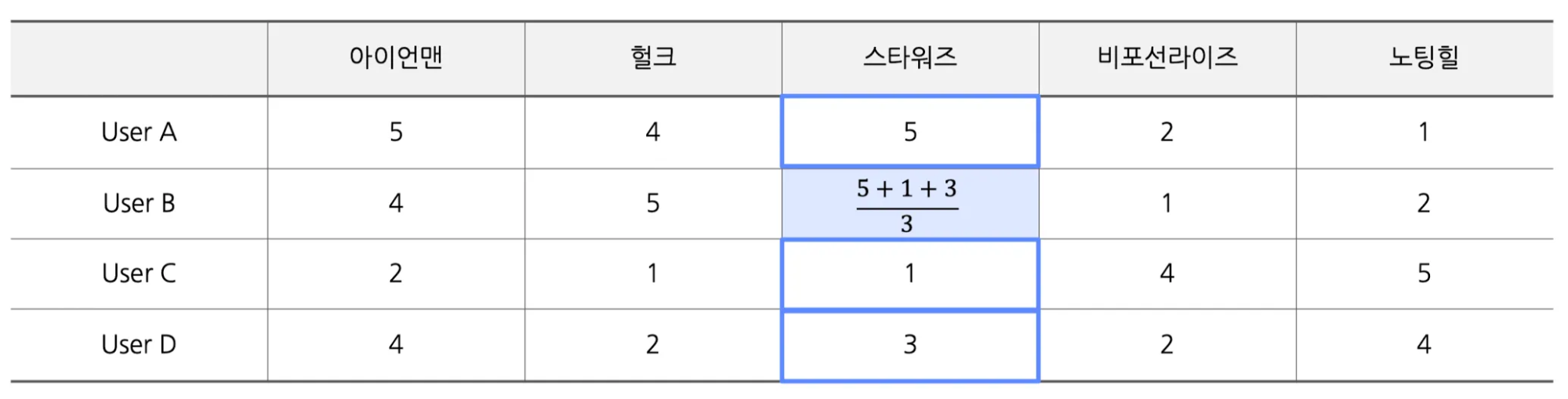
- Weighted Average 적용
- 유저 B의 입장에서
- 유저 A → 본인과 유사 → 많이 반영
- 유저 C → 본인과 다름 → 적게 반영
- 가중 평균 적용
- 유저 B와 유저 A(0.95), C(0.6), D(0.85)의 유사도를 반영 → 평점 예측
- $\frac{0.95 \cdot 5 + 0.6 \cdot 1 + 0.85 \cdot 3}{0.95+0.6+0.85} = 3.3$
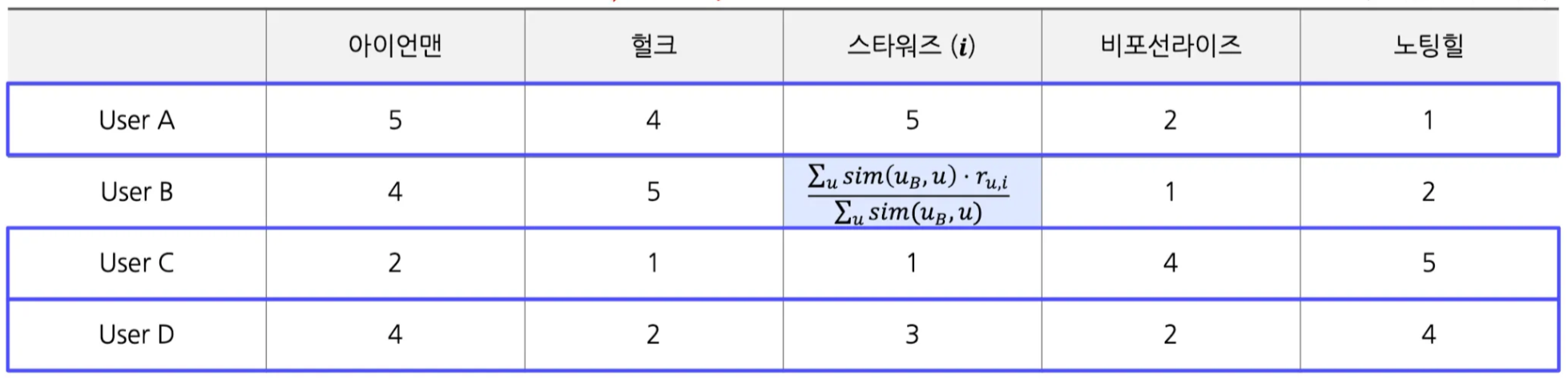
- 유저 B의 입장에서
- 스타워즈에 대한 다른 유저들의 rating을 평균냄
- 일반화된 경우에 대해, UBCF를 적용할 경우
- 전체 유저 $U$, 아이템 $I$에 대한 평점 데이터가 존재할 때, 유저 u의 아이템 i에 대한 평점 $\hat{r}(u, i)$를 예측하는 task
- 아이템 $i$에 대한 평점 존재
- 유저 $u$와 유사한 유저들의 집합 $\Omega_i$
- UBCF 적용 → Weighted Average 적용
- Average
- $\hat{r}(u, i) = \frac{\sum_{u^{\prime} \in \Omega_i}r(u^{\prime}, i)}{\left\vert \Omega_i \right\vert}$
- Weighted Average - “target 유저-비교 대상 유저”간 유사도 값 추가
- $\hat{r}(u, i) = \frac{\sum_{u^{\prime} \in \Omega_i} sim(u, u^{\prime})r(u^{\prime}, i)}{\sum_{u^{\prime} \in \Omega_i} sim(u, u^{\prime})}$
- Average
- 전체 유저 $U$, 아이템 $I$에 대한 평점 데이터가 존재할 때, 유저 u의 아이템 i에 대한 평점 $\hat{r}(u, i)$를 예측하는 task
- Absolute Rating의 한계점
- 유저가 평점을 제공하는 기준이 제각기 다름
- 같은 5점이라도, 엄격한 유저가 부여한 5점과 후한 유저가 부여한 5점은 가중치가 다름
- 고로, 유저간 편차 반영이 어려움
- ex) 긍정적 유저 vs 부정적 유저
- 긍정적 유저: 대부분 5점 부여, 부정적 평가로 3점 부여
- 부정적 유저: 대부분 1~2점 부여, 가끔 좋은 평가가 하고 싶을 때 4점 부여
- 이렇게, 절대적으로 같은 점수라도 유저간 상대적인 의미는 차이가 있음 → “Relative Rating(상대적 평점)이 필요한 이유”
-
- Relative Rating
- 개념
- 유저의 평균 평점에서 얼마나 높은지(혹은 낮은지), 그 편차값(Deviation)을 활용
- 위의 긍정적 유저 vs 부정적 유저 예시에서 볼 수 있듯,
- 어떤 유저는 평균 평점이 2.5점인데 5점을 주었다면 아주 높게 평가한 것
- 모든 아이템의 평점을 5점으로 주는 유저는, 아이템 간 비교가 어려움
- 수식
- 모든 평점 데이터를 deviation으로 변경, 원래의 rating값 대신 deviation값 예측
- $dev(u, i) = r(u, i) - \overline{r_u} $
- $for \ known \ rating$
- predicted rating = 유저 평균 rating + predicted deviation
- 유저 평균 rating: $\overline{r_u}$
- predicted deviation: $\widehat{dev}(u, i) = \frac{\sum_{u^{\prime} \in \Omega_{i}} dev(u^{\prime}, i)}{\left\vert \Omega_{i} \right\vert} = \frac{\sum_{u^{\prime} \in \Omega_{i}} r(u^{\prime}, i) - \overline{r_{u^{\prime}}} }{\left\vert \Omega_{i} \right\vert}$
- Predicted Rating → $\hat{r}(u, i) = \overline{r_u} + \frac{\sum_{u^{\prime} \in \Omega_{i}} r(u^{\prime}, i) - \overline{r_{u^{\prime}}} }{\left\vert \Omega_{i} \right\vert} = \overline{r_u} + \widehat{dev}(u, i)$
- 모든 평점 데이터를 deviation으로 변경, 원래의 rating값 대신 deviation값 예측
- 개념
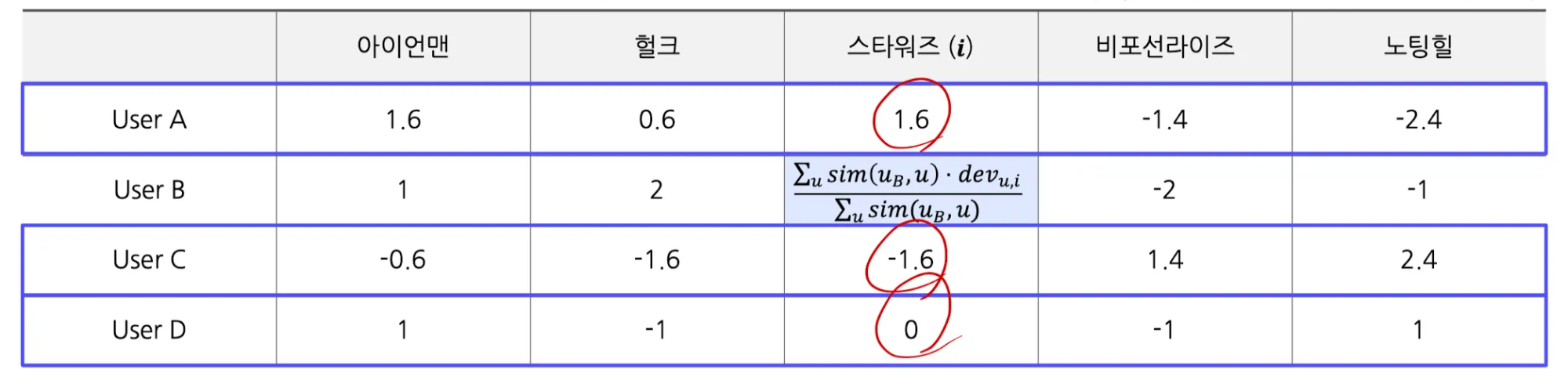
- 예시 문제(Absolute Rating과 동일) → 유저 B의 스타워즈에 대한 deviation 평점 예측
- predicted deviation: $\frac{1.6 \cdot 0.95 + (-1.6) \cdot (0.6) + 0 \cdot 0.85}{0.95+0.6+0.85} = 0.23$
- 유저 B의 평점 평균: 3.0
-
Relative Rating → 0.23+3.0=3.23
- Absolute Rating vs Relative Rating
- 수식을 통한 비교
- Absolute Rating
- $\hat{r}(u, i) = \frac{\sum_{u^{\prime} \in \Omega_i} sim(u, u^{\prime})r(u^{\prime}, i)}{\sum_{u^{\prime} \in \Omega_i} sim(u, u^{\prime})}$
- Relative Rating
- $\hat{r}(u, i) = \frac{\sum_{u^{\prime} \in \Omega_i} sim(u, u^{\prime}){r(u^{\prime}, i)-\overline{r_{u^{\prime}}}}}{\sum_{u^{\prime} \in \Omega_i} sim(u, u^{\prime})}$
- Absolute Rating
- 차이점은, 원래의 rating 값 대신 deviation이 적용되었다는 것 ( $r(u^{\prime}, i)-\overline{r_{u^{\prime}}}$ )
- 수식을 통한 비교
IBCF
- 개요
- 원리는 UBCF와 동일
- 유저 기준 rating 비교에서, 아이템 기준 rating 비교로 바뀐 것일 뿐
- 두가지 평점 기준(Absolute Rating, Relative Rating)
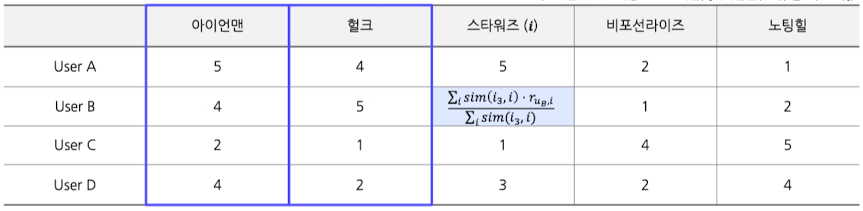
- 문제 - 타 아이템에 대한 선호도를 이용하여, 스타워즈에 대한 유저 B의 선호도 예측
- Absolute Rating (Weight Average)
- 아이언맨과 헐크의 평점을 활용해서, 스타워즈 평점 예측 (2-NN)
- 아이언맨-스타워즈 유사도 : 0.9 / 헐크-스타워즈 유사도 : 0.95
- 유저 B의 스타워즈 선호도 예측 → $\frac{0.9 \cdot 4 + 0.95 \cdot 5}{0.9 + 0.95} = 4.5$
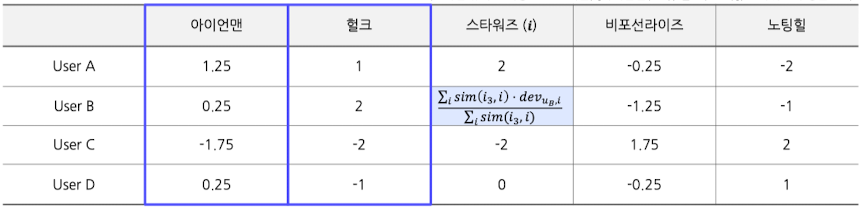
- Relative Rating (Using Deviation)
- 마찬가지로, 아이언맨과 헐크의 평점을 활용해서 스타워즈 평점 예측 (2-NN)
- 아이템 간 편차를 반영한, 유저 B의 스타워즈 선호도 예측
- $\frac{0.9 \cdot 0.25 + 0.95 \cdot 2}{0.9 + 0.95} = 1.15$
- 최종 예측 평점: 1.15+3.0(유저 B의 평점 평균) = 4.15
- Absolute Rating (Weight Average)
- 수식 비교 (Absolute vs Relative)
- $\Phi_u$: 유저 $u$가 평가한 아이템들의 집합
- 위 예시: K-2NN(아이언맨, 헐크)
- Absolute Rating
- $\hat{r}(u, i) = \frac{\sum_{i^{\prime} \in \Phi_u} sim(i, i^{\prime})r(u, i^{\prime})}{\sum_{i^{\prime} \in \Phi_u} sim(i, i^{\prime})}$
- Relative Rating
- $\hat{r}(u, i) = \frac{\sum_{i^{\prime} \in \Phi_u} sim(i, i^{\prime}){r(u, i^{\prime}) - \overline{r_i^{\prime}}}}{\sum_{i^{\prime} \in \Phi_u} sim(i, i^{\prime})}$
- $\Phi_u$: 유저 $u$가 평가한 아이템들의 집합
Top-N Recommendation
- 개요
- CF의 목적: 유저 u가 아이템 i에 부여할 평점 예측
- RecSys의 목적: 예측 평점이 높은 아이템을 유저에게 추천하는 것 ⇒ Top-N Recommendation
- 방법 상세
- 타겟 유저에 대한 예측 평점 계산
- 평점 높은 순으로 정렬
- 상위 N개 추천 (Top-N Rec)
chat_bubble 댓글남기기
댓글남기기