Recommender System with DL
추천시스템에서 딥러닝을 활용하는 이유
1) Nonlinear Transformation
- Deep Neural Network를 통해 데이터의 비선형성(Non-linearity)을 효과적으로 표현하기 위함
- 이러한 비선형성을 추천모델에 추가해 줌으로서, 복잡한 user-item interaction pattern을 효과적으로 모델링하여 유저의 선호도를 예측
- Deep Learning을 통해, 할 수 있기를 기대 추천 모델의 단순함을 DNN을 통해 해결
2) Representation Learning
- DNN은 raw data로부터 feature representation을 학습하여 사람이 직접 feature를 설계하지 않아도 됨
- 이를 통해, 다양한 종류의 정보를 추천 시스템에 활용할 수 있음: 텍스트/이미지/오디오 등
3) Sequence Modeling
- DNN은 sequential modeling task에 성공적으로 적용된 사례가 있음: 자연어 처리 / 음성 신호 처리 등 → 추천시스템의 sequential modeling task에 대해서도 동일한 효과를 보기 위함
- Next-item prediction / Session-based recommendation 등
4) Flexibility
- Deep Learning은 다양한 프레임워크 오픈(PyTorch / Tensorflow 등)
- 추천 시스템 모델링의 flexibility가 높으며, 더 효율적으로 서빙 가능함
Recommender System with MLP
MLP란?
- 다중 퍼셉트론, Multi-Layer Perceptron
- Perceptron 여러 개로 이루어진 layer 여러 개를 순차적으로 이어 놓은 Feed-Forward Network
- Input Layer / Hidden Layer / Output Layer로 구성
- Input Layer(입력층): 데이터를 받아들이는 층
- Hidden Layer(은닉층): 입력층-출력층 간 중간 처리 계층(1개 이상)
- Output Layer(출력층): 최종 결과를 출력하는 층
Neural Collaborative Filtering(NCF)
개요
- MF의 한계를 지적 → 신경망 구조를 사용하여 더욱 일반화된 모델 제시
- NCF 논문에서 제시하는, MF의 한계점
- user-item embedding의 선형 조합 → user-item 간 복잡한 관계를 표현하는 것에 한계
-
Example in Paper
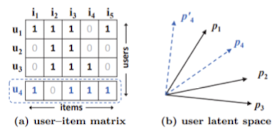
- 기존, 3명의 사용자에 대한 user-item Matrix가 있음
- user 1,2,3에 대한 벡터를 표현한 공간이 → 우측 그림의 latent space
- 이 상황에서, 새롭게 user 4가 등장한다고 가정
- 여기서 문제가 발생함 → user 4를 latent space에 표현 시 모순이 발생
- user 4는 user 1과 가장 가까우니, 우측 그림의 latent space에서 파란 점선과 같이 표현됨
- 하지만, user 4는 user 1 다음으로 user 4와 유사한 user 3와 가까워야 하는데 user 3보다 user 2와 더 가까이 위치하게됨 → 모순 발생
- 결론적으로, user 4는 user 1과 가까워도 user 2보다 user 3에 가까울 수 없음
- latent space의 차원을 높여서 해결이 가능하기도 함 → 하지만 이는 비효율적이고 Overfitting 발생 가능성이 있음 → 이를 NCF는 MLP를 통한 비선형성 추가로 해결하고자 했음
- NCF : MF에 MLP를 결합하여 MF의 한계점을 보완하고자 시도한 모델(General MF + MLP)
모델 구조
-
MLP 파트
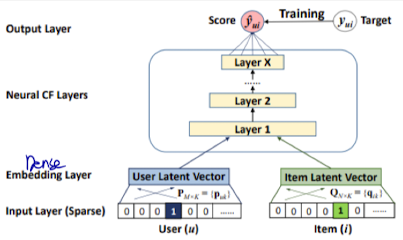
- Input Layer
- user, item 벡터를 One-hot encoding 시킴
- $v_u$, $v_i$
- Embedding Layer
- Input Layer에서 변환한 One-hot encoding → $(v_u, v_i)$
- 기존에 존재하던 user, item에 대한 Embedding Matrix → $(P, Q)$
- $v_u, v_i$와 $P, Q$를 각각 곱해 고정된 크기의 임베딩 벡터(실수)로 변환
- 위 과정을 통해, Sparse한 One-hot encoding vector 대신 Dense한 embedding vector로 정보를 압축해서 표현
- User : $P^Tv_u$ / Item : $Q^Tv_i$
- Neural CF Layers
- Embedding Layer에서 만들어진 두 Latent vector를 concat하여 첫 번째 Layer 생성
- 그 위로 Layer를 계속 쌓아 다층 신경망을 형성해줌 → 상호작용 학습
- $\phi_{MLP}=\phi_X(\cdots\phi_2(\phi_1(P^Tv_w,Q^Tv_i))\cdots)$
- $\phi_X$ : x번째 neural network
- Output Layer
- Activation Function을 통해, 예측값을 0~1 범위의 확률로 변환해줌
- user-item 간 관련도 표현
- $\hat{y}{ui} = $ $\phi{out}(\phi_X ( \cdots \phi_2 ( \phi_1 (P^T v_u, Q^T v_i) ) \cdots ) )$
- $\hat{y}_{ui} \in [0, 1]$
- Input Layer
- 최종 결합 모델(GeneralMF + MLP)
-
GMF와 MLP를 앙상블하여 사용
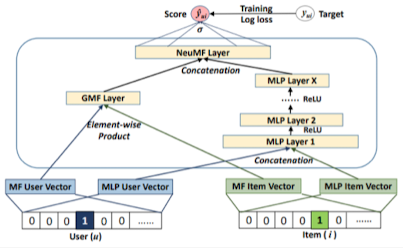
- GMF(General MF) : MF를 일반화한 모델
- Input Layer / Embedding Layer
- MLP와 생성방식 동일
- 하지만, Embedding Matrix는 MLP 파트와 다른 독립적인 파라미터를 사용함
- 같은 user ID / item ID라도 GMF와 MLP에서 뽑아내는 임베딩 벡터 값은 서로 다름
- 차원이 다를 경우에는, concat 연산이 불가능 → “차원 불일치에 주의”
- GMF Layer
- General MF 파트에서 생성된 User Vector 및 Item Vector를 연산(Element-wise Product)하여 생성
- $\phi_{GMF}=(p^G_u)^Tq^G_i$
- Input Layer / Embedding Layer
- NeuMF Layer
- MLP Layer와 GMF Layer를 Concat하여 생성
- 이렇게 결합된 NeuMF Layer에 → 학습 가능한 가중치 벡터 $h$를 곱해 스칼라 값으로 변환
- Output Layer
- NeuMF를 통해 변환한 값에 Logistic function(or Probit function)을 통과하여 0~1 범위의 $\hat{y}_{u, i}$생성
- $\hat{y}_{u, i} = \sigma(h^T[\phi^{GMF}\phi^{MLP}])$
- $\hat{y}_{u, i}$ → 사용자 $u$와 아이템 $i$가 상호작용할 확률
-
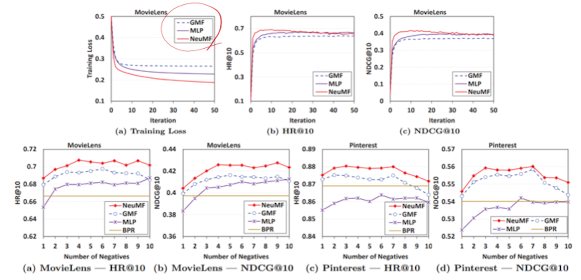
- 모델 성능 결과
- 실험 대상 데이터셋 : MovieLens / Pinterest 데이터셋
-
결과 : NCF 추천 성능이 기존 MF나 MLP 모델보다 높음
- 의의
- 성능적인 측면보다는, MLP를 기존 MF에 처음 추가한 논문이라는 점에서 의미
- RecSys 모델에도 DNN이 효과가 있다는 것을 보여준 사례
chat_bubble 댓글남기기
댓글남기기