개요
- Deep Learning 기반 추천 시스템을 실제 유튜브 서비스에 적용한 논문
- 실제 YouTube가 적용한 모델의 논문
유튜브 추천 시스템의 핵심 도전과제
- Scale
- 매우 다량의 유저와 아이템 정보(수백만 개의 동영상, 수억 명의 사용자 정보)를 보유하고 있음
- 하지만 컴퓨팅 파워는 제한적 → 효율적 서빙 및 이에 특화된 추천 알고리즘 필요(고도로 전문화된 분산 학습 알고리즘 필요)
- Freshness
- 매초마다 수많은 동영상이 업로드됨 → 새로운 콘텐츠를 빠르게 반영 + 기존 콘텐츠와의 균형이 필요함
- 실시간으로, 새로운 콘텐츠와 기존 콘텐츠 추천 비율을 적절히 조합해야 함
- Noise
- 유저 만족도에 관련한 실제 지표를 얻기 매우 어려움(데이터의 Sparsity와 다양한 외부 요인들 때문)
- 이에, Noise를 다량 포함한 Implicit Feedback 필요함
- 또한, 낮은 품질의 메타 데이터를 잘 활용해야 됨
모델 구조
개요 → 2단계 추천 시스템
-
“Candidate Generation” + “Ranking”
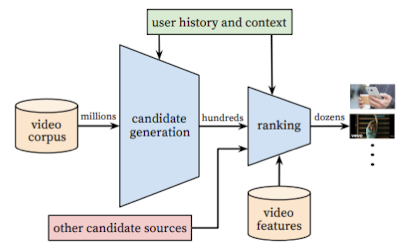
- Candidate Generation
- 목적 → “High Recall” → 수백만 개의 동영상에서 수백 개의 관련성 높은 후보 선별
- 개략적으로 후보군을 1차적으로 추리는 과정
- Ranking
- 목적: 선별된 후보들 중 상대적 중요도를 구분하여 최종 순위 결정
- 유저 및 비디오에 대한 feature를 좀 더 풍부하게 사용
- score를 산출해 최종 추천 리스트 제공
- Candidate Generation
1단계 : Candidate Generation
-
주어진 사용자에 대해 Top N 추천아이템 생성
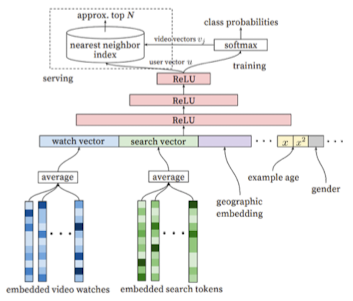
- 문제 정의(핵심 아이디어)
- “Extreme Multiclass Classification” → 추천을 Extreme Multiclass Classification로 재정의 하는 것
- 특정 시간 $t$에 유저 $u$가 $c$라는 context를 갖고 있을 때, 비디오($i$) 각각을 볼 확률 계산
- 비디오는 수백만 개 존재 → “Extreme”
- 결국 마지막에는, Softmax 함수를 사용하는 “분류 문제” → 결국 시청자가 시청하는 영상은 하나이므로
- $P(w_t = i \mid U, C) = \frac{e^{v_i^u}}{\sum_{j \in V} e^{v_j^u}}$
- $w_t=i$ : 시간 $t$에 동영상 $i$를 시청
- $U$, $C$: 사용자 정보, context 정보
- $u$ : 사용자와 context의 고차원 임베딩
- $v_j$ : 각 후보 동영상의 임베딩
- 모델 구조
- 다양한 Feature vector
- Watch Vector 및 Search Vector
- 사용자의 과거 행동을 요약한 두 가지 핵심 벡터
- 각각 과거 시청 이력 & 검색 이력 임베딩
- 과거 시청 이력
- 각 동영상 $i$는 사전 학습된 임베딩 $v_i$ 갖고 있음
- 사용자가 마지막으로 시청한 $K$개의 시청 이력 활용
- $K$: 시스템 성능 및 메모리 제약을 고려해 수십-수백개 수준으로 설정
- 최근 영상에 가중치 부여 가능
- 장르/카테고리가 편향되지 않도록 균등하게 샘플링
- 단순 평균치 계산
- 과거 검색 이력
- 사용자가 입력한 검색 쿼리들의 임베딩 집계한 벡터
- 각 쿼리들 토큰화 → 각 토큰들에 대한 임베딩 조회 → 임베딩 전체 평균
- 핵심 의미만 반영, 지나치게 일반적이거나 불용어 제거
- 토큰 중요도 가중치 적용 가능(TF-IDF, Attention 기반 가중치)
- 과거 시청 이력
- Demographic & Geographic features
- 인구통계(gender 등) 정보 / 지리적 정보를 feature로 포함
- Example Age features
- 앞서 언급한 ‘Freshness’ 문제 해결을 위한 핵심 기법
- 문제: 모델이 과거 데이터 위주로 편향되어 학습되는 문제
- 해결: 학습 시 각 예시에 대한 age을 feature로 추가 → Bootstraping 현상 방지 및 Freshness 제고
- 앞서 언급한 ‘Freshness’ 문제 해결을 위한 핵심 기법
- Watch Vector 및 Search Vector
- User Vector 생성
- 위와 같은 다양한 feature vector를 한번에 concat하여 생성
- Concat한 feature vector를 ReLU(MLP Layer)에 통과 → User Vector 생성
- Training
- Extreme Multiclass Classification 문제 by SoftMax Classification
- 모델이 학습하는 내용 ⇒ “이 사용자가 다음에 볼 동영상은 무엇인가?”
- 학습 과정
- User vector → 모든 video vector에 대해 내적
- 1번 과정에 따른 내적 결과(=점수) 전체를 Softmax 함수에 넣어 확률분포 생성 → 각 동영상이 선택될 확률 계산
- 실제 사용자가 본 동영상이 정답이 되도록 파라미터 업데이트(=확률값 최대화)
- Serving
- 최종 Top-N 후보 추천 → Ranking 과정으로 후보 넘기기
- 실제 서비스: 수백만 개 동영상 중 빠르게 상위 N개 추천해야 됨
- 유저(user vector)를 input으로 하여 상위 N개 비디오 추출
- Serving 과정
- 학습된 네트워크에 user의 최신 행동을 입력하여 user vector 생성
- 생성된 user vector를 Nearest Neighbor index에 넣음
- Nearest Neighbor index: 모든 video vector ↔ user vector 간 유사도를 빠르게 계산하는 구조
- user vector와 가장 유사한(=내적값이 가장 큰 순서대로) 동영상 Top-N개를 근사적으로 빠르게 찾아냄
- YouTube를 키면 우리가 흔히 아는 “알고리즘을 탄 동영상”들이 쭉 추천되어 나타나게 됨
- 최종 Top-N 후보 추천 → Ranking 과정으로 후보 넘기기
- 다양한 Feature vector
2단계: Ranking
-
Top-N개의 추천 내용에 대한 순위를 매기는 문제
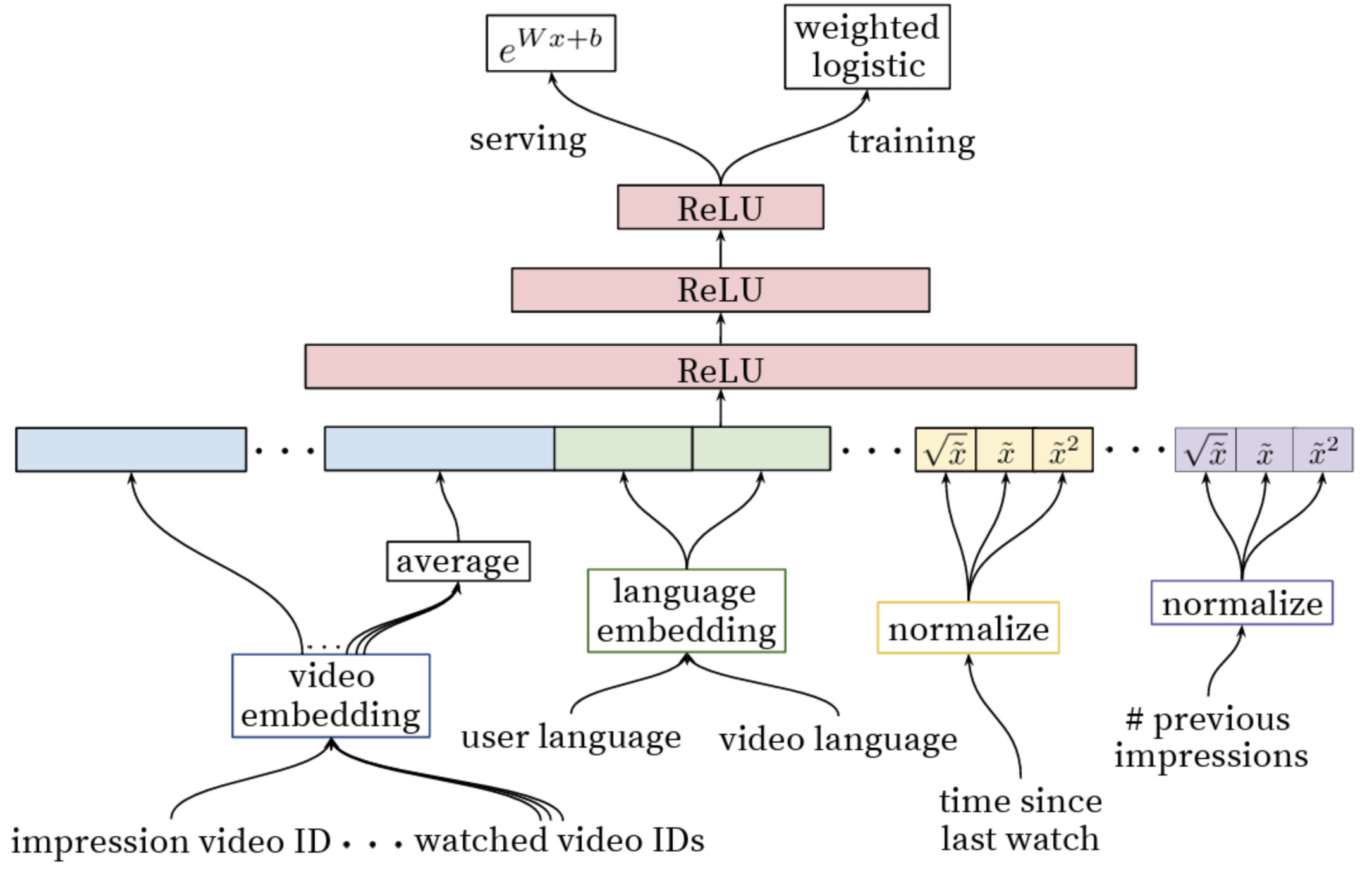
- 문제 정의
- 앞선 단계(Candidate Generation)에서 생성된 비디오 후보들을 input으로 넣어 최종 추천될 비디오의 순위를 매기는 문제
- Candidate Generation 단계를 통해 추려진 Top-N개의 비디오 벡터들만 입력받음
- DL 구조보다는, 도메인 전문가의 역량이 좌우하는 파트
- 서비스에 알맞는 Feature 선택이 중요
- 많은 Feature Selection, Feature Engineering 필요
- 모델 구조
- Concat feature
- 앞선 단계에서 전달받은 수백 개의 후보 영상에 대한 feature를 concat
- 논문에 나타난 Embedding 외에도, 실제 수십~수백개 feature를 함께 사용
- Feature 종류
- 행동 이력 기반 Embedding Feature
- Watched Video Embedding
- 사용자가 최근 시청한 동영상들의 ID를 임베딩 테이블에서 벡터로 변환
- 여러 개의 임베딩 벡터를 평균(pooling)하여 하나의 대표 벡터로 만듦
- 사용자의 취향과 최근 관심사를 요약
- Watched Video Embedding
- 개별 속성 Embedding Feature
- Language Embedding
- 범주형 속성(사용자 언어, 영상 언어 등)을 각각 임베딩 테이블에서 벡터로 변환
- 언어 선호 및 언어별 추천 최적화에 활용
- Impression Video ID Embedding
- 현재 추천 후보 영상의 ID를 임베딩 벡터로 변환
- 각 후보 영상의 고유 특성 반영
- Language Embedding
- 연속성 Feature 및 변환 Feature
- 시간 관련 Feature: ‘time since last watch’
- 원본 값 → 누적분포(CDF) 등으로 정규화(normalize)
- 정규화된 값($\sim x$), 제곱($\sim x^2$), 제곱근($\sim \sqrt{x}$) 등 다양한 변환값을 함께 입력
- 시간 관련 Feature: ‘time since last watch’
- 노출/빈도 관련 Feature: ‘# previous impressions’
- 해당 영상의 누적 노출 횟수
- 마찬가지로 정규화 및 다양한 수학적 변환값 함께 입력
- Context 및 환경 feature: 사용자 환경 정보
- 디바이스 종류, 지역, 세션 정보 등의 정보
- 범주형 값은 임베딩, 연속형 값은 정규화 후 입력
- 상호작용 및 관계 feature: 사용자-영상 상호 작용 Feature
- 과거에 해당 채널/카테고리에서 시청한 횟수, 마지막 시청 시점 등
- 정규화 또는 임베딩 후 입력
- 행동 이력 기반 Embedding Feature
- Feature 입력 방식
- 범주형 feature
-
각 고유값(예: 영상 ID, 언어, 카테고리 등)마다 에서 임베딩 테이블
고정 차원의 벡터를 조회
- 값의 종류가 많을수록(수십만~수백만) 임베딩 차원도 로그 스케일로 증가
- 여러 값이 있는 경우(예: 최근 시청 영상 K개)는 각 임베딩을 평균(pooling)해서 하나의 벡터로 만듦
-
- 연속형 feature
- 정규화 필수
- 누적분포함수(CDF), min-max, z-score 등을 통해 0~1 구간에 매핑
- 추가로, 정규화된 값의 제곱, 제곱근 등 다양한 변환값도 함께 입력(비선형 효과 학습을 위해)
- 신경망이 비선형 효과를 쉽게 학습하도록 feature space를 확장
- 정규화 필수
- 범주형 feature
- 실제 입력 벡터 구성
- 모든 임베딩 벡터와 정규화된 연속형 feature들을 한 줄로 concat, ReLU의 입력으로 사용
- Concat된 feature vector의 ReLU 통과
- 여러 임베딩(영상, 언어, 사용자 등) & 정규화된 연속형 feature(시간, 노출 횟수 등) ⇒ 하나의 긴 vector로 concat
- Concat된 vector는 MLP, 즉 여러 개의 Dense Layer(완전연결층)를 순차적으로 통과
- 여러 층을 거칠 수록, 점점 더 복잡하고 추상적인 특징을 뽑아낼 수 있음
- 마지막 Dense Layer의 출력이 각 후보 영상에 대한 최종 feature vector
- Training
- 목표: 각 후보 영상에 대해, 아래 2가지 예측하기
- “사용자가 실제로 시청 or 클릭할 확률”
- “예상 시청 시간(이 영상을 얼마나 오래 볼지)”
- 과정
- MLP 출력단
- 마지막 MLP Layer의 출력값을 Logistic Regression을 통과시킴으로서 값 변환
- Loss Function
- 클릭 예측
- “Binary CrossEntropy” (positive/negative example)
- 본 논문의 기본 가정: 주어진 user-item context에 대해, 해당 아이템 노출 시 클릭할 확률을 구하는 문제
- 시청 시간 예측
- “Weighted Logistic Regression” → 시청 시간으로 가중치 부여
- Loss Function을 통해, 단순 클릭여부 뿐 아니라 시청 시간을 가중치로 한 값을 반영해주기 위한 조치
- 이를 통해, 낚시성/광고성 콘텐츠를 업로드하는 abusing 현상 감소
- 클릭 예측
- 학습 데이터
- MLP를 통과한 데이터와 실제 데이터를 비교
- 실제 클릭/시청했으면 정답은 1, 보지 않았다면 정답은 0
- 예측값과 실제값 간 Loss 계산
- 가중치 업데이트
- 오차가 작아지도록 신경망의 모든 가중치(임베딩, MLP의 가중치 등)를 조금씩 조정
- 수십~수백만 번 반복, “어떤 상황에서 어떤 영상을 추천해야 할지” 점점 더 잘 배움
- MLP를 통과한 데이터와 실제 데이터를 비교
- MLP 출력단
- 목표: 각 후보 영상에 대해, 아래 2가지 예측하기
- Serving
- 실시간 추천목록 생성 과정
- Serving 과정 상세
- 실시간 입력 받기
- 사용자가 유튜브 앱을 켜고, 홈 화면에 들어옴
- 서버가 이 사용자의 최신 정보(시청 기록, 언어, 기기, 최근 클릭/노출 등)를 실시간으로 모읍니다.
- Embedding Vector 생성, MLP 통과
- 앞선 과정들과 동일하게, 모든 벡터 concat해서 embedding하고, MLP 통과해서 각 후보 영상 별 예상 점수(시청 확률, 예상 시청 시간) 계산
- 점수로 정렬, Top-N 추천
- 점수가 가장 높은 순서대로 후보 영상 정렬
- 상위 N개(예: 20~50개)를 뽑아 추천 리스트 생성
- 이 리스트가 사용자의 유튜브 홈 화면에 바로 표시
- 실시간 입력 받기
- Concat feature
요약 및 의의
- 처음으로 DL을 이용한 추천 시스템의 이론과 Serving의 문제까지 담아낸 점에서 의미
- DL 기반 2단계 추천을 처음으로 제안
- Candidate Generation: 유저에게 적합한 수백 개의 후보 아이템 추려냄
- Ranking: 더 Rich한 feature를 활용하여 CG 단계에서 추린 수백 개의 후보 아이템 중 최종 추천 아이템 10-20개 제공
- 1단계: Candidate Generation
- 기존 CF 아이디어 기반, 다양한 feature를 사용해 추천 성능 향상
- 유저 feature: watch/query history, demographic, geographic 등
- 아이템 feature: Example Age
- 기존 CF 아이디어 기반, 다양한 feature를 사용해 추천 성능 향상
- 2단계: Ranking
- 과거에는 선형/트리 기반 모델 위주 활용 → 해당 논문에서 기존 선형/트리 모델들 보다 더 뛰어난 성능을 보여줌
- Rich Feature: CG단계에서 사용한 feature + 이외에 더 많은 feature를 사용하여 Ranking 단계 수행
- 단순 CTR(Click to Rate) 예측이 아닌 “Expected Watch Time” 예측 → 실제로 “유저가 해당 영상을 클릭할까?” 라는 수준을 넘어서, “얼마나 해당 영상을 오래 시청할 것인가?”라는 지표를 예측 목표로 삼았다는 점에서 의의
chat_bubble 댓글남기기
댓글남기기