AutoEncoder란?
-
Input data를 Output data로 다시 복원(reconstruction)하는 비지도(unsupervised) 학습 모델
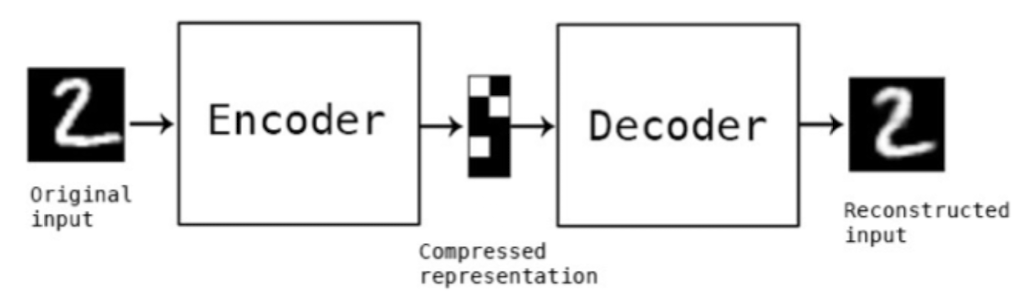
- RecSys에서의 활용도: “차원축소의 알고리즘” → 중요한 것은 남기고, 중요하지 않은 것은 날리는 비선형적인 차원감소를 통한 학습 방식
- Hidden Layer를 Input Data의 feature representation으로 활용
-
Denoising AutoEncoder(DAE)
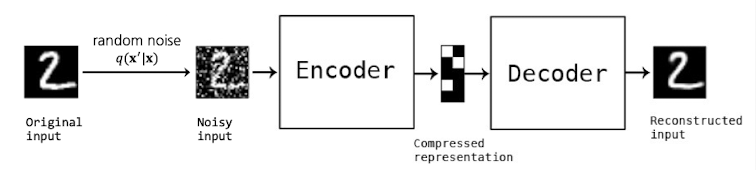
- Input data에 인위적으로 random noise나 dropout을 추가하여 학습
- 이를 통해, 모델은 데이터 중에서도 더 중요한 특징을 더 잘 학습하게 됨
- noise input을 더 잘 복원할 수 있도록 robust한 모델이 학습되어 전체적 성능 향상 (일반화 성능 향상)
AutoEncoder를 활용한 추천시스템 1: AutoRec
개요 및 핵심 아이디어
- CF(Collaborative Filtering)에 AutoEncoder를 적용하여, Representation은 향상시키고 Complexity는 감소시킨 모델
- 배경
- CF → 사용자들의 아이템에 대한 선호도 정보를 활용하여 개인화된 추천을 제공하는 기술
- Netflix Challenge 이후 다양한 CF 모델 제안
- AutoRec 연구팀 → CV 및 음성인식 분야에서 성공을 거둔 DL 기술인 AE를 적용하고자 함
- 차용 근거: 기존 신경망 기반 CF 모델들에 비해 AutoEncoder가 Representation 및 Computational 측면에서 장점을 지님
- CF → 사용자들의 아이템에 대한 선호도 정보를 활용하여 개인화된 추천을 제공하는 기술
- AutoRec 핵심 원리
- Rating Vector를 입출력으로 하여 Reconstruction 과정 수행
- user 및 item 벡터를 저차원의 latent feature로 표현 → 이를 사용해 평점 예측
- AutoEncoder의 Representation Learning을 item과 user에 각각 적용
- Encoder가 input vector를 latent space로 압축 → 이 과정에서 사용자나 아이템의 특징을 집약한 latent feature를 자동으로 학습
- AutoRec vs. MF
- MF: Linear, low-order interaction을 통한 representation 학습
- AutoRec: Non-linear activation function 활용 → 더 복잡한 interaction 표현 가능
- Rating Vector를 입출력으로 하여 Reconstruction 과정 수행
모델 구조
- Item과 User, 각각에 대해 임베딩을 따로 진행
-
한 번에 하나씩만 임베딩을 진행(아래 그림은 아이템 임베딩)
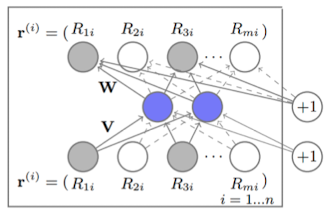
- 아이템 기반 AutoRec (I-AutoRec, 위 그림): Item에 대한 Rating Vector $r_i$ 입력
- 사용자 기반 AutoRec (U-AutoRec): User에 대한 Rating Vector $r_u$ 입력
- 동작 원리(I-AutoRec 기준)
- 부분적으로 관측된 아이템 벡터 $r^i$를 입력으로 받음
- 인코더를 통해 → 저차원의 latent space으로 투영
- 디코더를 통해 → 원래 차원으로 복원 / missing rating 예측
- Missing rating: 아직 사용자가 평점을 남기지 않은 평점 값(관측되지 않은 평점 값)
- 복원된 벡터의 각 원소는 “해당 사용자가 이 아이템에 매길 것으로 예상되는 평점” 의미
- 초기에 입력되는 $r^i$는 대부분 값이 비어있거나(미관측), 일부 값만 실제 평점으로 채워져 있음 → AutoRec을 통과하면서 채워나가는 과정
학습
- 입력 데이터 준비
- 평점 행렬(Rating Matrix) : User-item Matrix 활용 ⇒ 95% 이상 비어있는 Sparse한 행렬
- Item 기반 AutoRec일 경우 → 각 아이템에 대한, 모든 사용자의 rating vector를 입력으로 사용
- 평점 행렬(Rating Matrix) : User-item Matrix 활용 ⇒ 95% 이상 비어있는 Sparse한 행렬
- 네트워크 구조
- Encoder : 입력받은 벡터(부분적으로 관측된 rating)를 저차원 latent space로 압축
- Decoder : 압축된 latent feature → 원래 차원(user 숫자)으로 복원
- Bias : 각 layer에 Bias 항이 더해짐
- Forward Pass(순전파)
- 순전파 과정 요약(2번과정)
Input Rating Vector → Encoder 통과 → latent vector로 변환(압축) → Decoder 통과 → 복원 - 수식: $h(r;\theta) = f(W \cdot g(Vr+\mu)+b)$
- $r$ : 기존 rating
- $V$ : Encoder 가중치
- $\mu$ : Encoder의 bias vector
- $g(\cdot)$ : Encoder의 non-linear activation function
- $W$ : Decoder 가중치
- $f(\cdot)$: Decoder의 output activation function
- $b$: Decoder의 bias vector
- 순전파 과정 요약(2번과정)
- Loss Function(손실함수)
- 목표 : “관측된 평점(실제 값)-복원된 평점(예측 값)” 간 오차 최소화
- 손실 함수 종류 : 평균 제곱 오차(MSE)
- 수식 : $\min_{\theta} \sum_{\mathbf{r} \in S} \Vert \mathbf{r} - h(\mathbf{r}; \theta) \Vert_2^2$
- Backpropagation(역전파) / 파라미터 업데이트
- 역전파 → Loss Function 바탕으로, 가중치 및 bias 파라미터에 대해 그래디언트 계산
- 역전파의 진행은, 실제로 평점이 있는(관측된 위치) 아이템에 대해서만 이루어짐 → 미관측 값은 학습에 관여하지 않음
-
- 최적화 알고리즘: Adam, SGD, RProp 등(일반적으로 딥러닝에서 널리 쓰이는 기법 사용)
- 역전파 → Loss Function 바탕으로, 가중치 및 bias 파라미터에 대해 그래디언트 계산
- 반복학습(Epoch)
- 1~5의 과정을 여러 번 반복 → 네트워크 파라미터가 관측된 평점을 더 잘 복원하는 방향으로 계속 업데이트 → 과정을 여러 번 거칠수록 missing rating에 대한 예측값의 신뢰도도 점점 상승
모델의 실험 결과 및 의의
- 실험 데이터셋: MovieLens 및 Netflix 데이터셋
- 성능 비교 결과: RBM, MF 보다 좋은 성능
- Item based vs User based: User based method보다 Item based method가 일반적으로 더 좋은 성능 보임
- 아이템당 평균 평점 수가 사용자당 평균 평점 수보다 많기 때문
- 데이터 갯수가 많기 때문
- Activation Function의 중요성: Hidden Layer에서의 비선형성($g(\cdot)$)이 I-AutoRec의 우수한 성능에 영향 → MF와 비교했을 때 장점
- Hidden Unit 갯수의 영향: Hidden Layer 내 Unit 갯수가 증가할수록 성능은 향상, 수익은 감소 효과
- 수익 감소 효과: 유닛 수를 계속 늘리면 어느 순간부터는 성능 향상 폭이 점점 줄어듦
- 50개에서 100개로 늘릴 때는 성능이 많이 좋아지지만
- 400개에서 500개로 늘릴 때는 성능 개선이 미미해짐
- 수익 감소 효과: 유닛 수를 계속 늘리면 어느 순간부터는 성능 향상 폭이 점점 줄어듦
AutoEncoder를 활용한 추천시스템 2: CDAE
개요 및 핵심 아이디어
- 개요
- CDAE(Collaborative Denoising AutoEncoder)는 AutoRec과 다르게, AutoEncoder 대신 Denoising AutoEncoder를 CF에 적용한 모델
- 기존 CF 알고리즘보다 높은 유연성 확보 가능
- CDAE vs AutoRec
- AutoRec은 Rating Prediction에 초점
- CDAE는 “Ranking을 통해 유저에게 Top-N 추천 제공”에 초점
- CDAE(Collaborative Denoising AutoEncoder)는 AutoRec과 다르게, AutoEncoder 대신 Denoising AutoEncoder를 CF에 적용한 모델
- 핵심 아이디어
- Denoising 메커니즘 활용
- AutoRec의 AutoEncoder: 입력 데이터 그대로 원복하는 것이 목표
- CDAE의 Denoising AutoEncoder: 의도적으로, 입력 데이터에 노이즈 추가(사용자가 상호작용한 아이템 정보를 일정 확률 $q$로 제거)
- 관찰된 사용자-아이템 상호작용은 사용자의 실제 선호도의 일부만을 나타냄
- 노이즈 추가를 통해, 모델이 강건한(robust) 잠재 표현(latent representation)을 학습할 수 있도록 ⇒ 과적합 방지 및 일반화 성능 향상
- User-specific Node(사용자 특화 노드)
- 앞선 추천 모델들과 비교했을 때, 가장 중요한 차이점
- 이전의 추천 모델: User-Item 행렬 기반 / MF 기반 등
- 초기 AutoEncoder 계열 모델: 모든 사용자의 입력 구조가 동일(입력으로 user vector, item vector만 사용)
- CDAE: 입력 레이어에 explicit하게 user-specific node 포함 → 동일한 아이템 벡터를 가진 사용자라도 다른 사용자로 명확히 구분이 가능
- 앞선 추천 모델들과 비교했을 때, 가장 중요한 차이점
- Implicit Feedback 활용
- explicit한 평점 대신 이진(binary) 형태의 implicit feedback을 사용
- 사용자가 아이템과 상호작용했으면 1, 그렇지 않으면 0으로 표현 → 실제 추천시스템에서 자주 마주하는 상황 반영
- 기존 모델의 일반화
- CDAE는 여러 기존 협업 필터링 모델들을 일반화한 프레임워크 ⇒ 더 유연한 구조 지님, 다양한 추천 문제에 적용 가능
- Denoising 메커니즘 활용
모델 구조
-
전체 아키텍쳐는 AutoEncoder와 유사, 3개 레이어로 구성된 신경망 구조
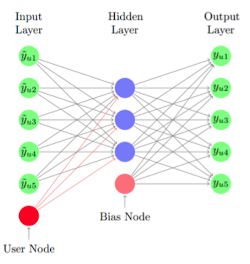
- Input Layer
- 전체 아이템에 대응하는 아이템 입력 노드
- 마지막 1개 노드: “user-specific node(위 그림의 빨간색 노드)” - 사용자 별로 고유
-
의도적인 Noise가 낀 입력값 생성
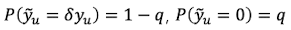
- $q$: dropout 확률
- $\tilde{y}_{u}$: $q$의 확률에 의해 0으로 dropout되는 벡터
- $\delta = 1/(1-q)$
- Hidden Layer
- Input Layer의 모든 노드들과 fully-connected
- 추가로, bias 모델링을 위한 bias node
- Encoding
- $z_u = h(W^\top \tilde{y}_{ui}+V_u+b)$
- $W$: 인코더 가중치 행렬
- $V_u$: 사용자 u에 대한 사용자 특화 벡터
- $b$: bias 벡터
- $h(\cdot)$: 인코딩 활성함수
- $z_u = h(W^\top \tilde{y}_{ui}+V_u+b)$
- Input Layer의 모든 노드들과 fully-connected
- Output Layer
- 각 아이템에 대한 사용자의 선호도 점수를 출력
- Hidden Layer와 fully-connected
- 출력된 결과는 곧 해당 아이템을 선호할 확률/점수를 나타냄
- Decoding
- $\tilde{y}_{ui} = f({W}^{\prime\top}_i z_u + b^{\prime}_i)$
- ${W}^{\prime}$: 디코더 가중치 행렬
- $b_i^{\prime}$: 아이템 i에 대한 bias
- $f(\cdot)$: 디코딩 활성함수
- $\tilde{y}_{ui} = f({W}^{\prime\top}_i z_u + b^{\prime}_i)$
- Input Layer
- Tied Weights vs Untied Weights
- 인코더와 디코더의 가중치 공유 여부
- Tied: 공유 O
- Untied: 공유 X
- CDAE는 실험 결과, untied weights일 때 더 좋은 성능 나타냄
(입출력간 비대칭성을 더 잘 포착할 수 있기 때문)
- 인코더와 디코더의 가중치 공유 여부
- 학습 목적 함수
-
Reconstruction Error 최소화 → MSE 활용
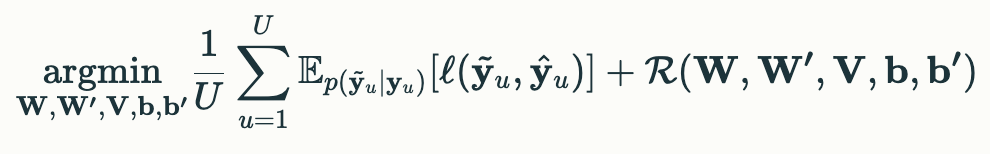
- $\ell(\cdot, \cdot)$: 손실 함수
- $\mathcal{R}(\cdot)$: 과적합 방지 by L2 normalized term
-
- 학습 알고리즘
- SGD 기반 학습
- AdaGrad를 통해 학습률 자동 조정
- 선택적으로 negative sampling 적용 → 계산 복잡도 감소
결과 및 의의
- 실험 대상 데이터셋
- MovieLens (100K, 1M)
- FilmTrust
- Epinions
- 평가지표
- MAP (Mean Average Precision): 추천 순서의 정확도
- Recall@K: 상위 K개 추천에서 관련 아이템의 재현율
- NDCG (Normalized Discounted Cumulative Gain): 순위를 고려한 평가
- Precision@K: 상위 K개 추천의 정밀도
- 실험 결과 요약
-
대체적으로 N값과 관계없이, 다른 top-N 추천 모델에 비해 더 높은 MAP 및 recall 값을 보임
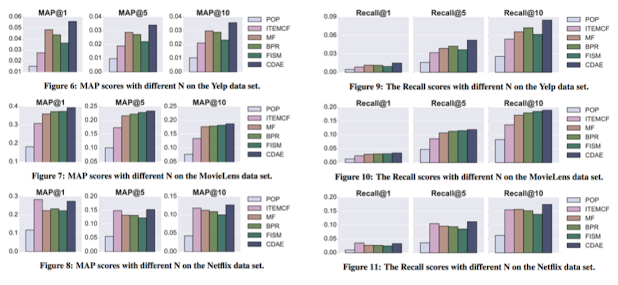
-
- 의의
- CDAE는 Denoising AutoEncoder를 Collaborative Filtering에 적용하여 Top-N 추천 문제를 해결한 첫 번째 모델
- 세 가지 핵심 아이디어(모델 일반화 및 성능 개선)
- 사용자 특화 노드의 도입
- 노이즈 추가를 통한 강건한 학습
- Implicit Feedback 활용
- 실험 결과도, CDAE가 여러 공개 데이터셋에서 기존의 협업 필터링 및 오토인코더 기반 모델들보다 일관되게 우수한 추천 성능을 보임
- 구조적 단순성으로 인한 빠른 학습 속도 및 높은 정확도 달성
- 실용적인 추천 시스템 구현에 적합한 모델
- 또한 많은 후속 연구의 기반이 됨
- VAE 기반 추천 모델(MultiVAE)
- Adversarial Training을 결합한 확장 모델 제안
chat_bubble 댓글남기기
댓글남기기