GRU4Rec: 개요 및 핵심 아이디어
- “지금” 고객이 원하는 상품 추천을 목표
- RNN을 추천시스템에 적용
- 논문 바로가기: Session-Based Recommendations with Recurrent Neural Network
- 핵심 아이디어 → Session 시퀀스를 GRU 레이어에 입력해서, 바로 다음에 올 확률이 가장 높은 아이템을 추천
GRU4Rec: 논문리뷰
개요
- 순환 신경망(RNN)을 세션 기반 추천 시스템에 최초로 적용한 선구적 연구
- 2016년 ICLR 발표, 4000회 이상 인용된 추천시스템 분야에서 영향력이 높은 논문
연구 배경 및 동기
세션 기반 추천의 필요성
- 세션(Session)이란?
- 추천 시스템에서 사용자가 일정 시간 동안 연속적으로 상호작용하는 단위
- 사용자가 웹사이트나 앱에서 짧은 시간 동안 남기는 클릭·뷰·구매 등과 같은 일련의 행동 시퀀스(sequence)
- ex)
- $s=[i_1,i_2,i_3,…,i_T]$
- $s$: 하나의 세션
- $i_t$: $i$번째 시점에 사용자가 클릭하거나 본 아이템
- $T$: 세션의 길이 (클릭 수)
- $s=[i_1,i_2,i_3,…,i_T]$
- 해결하고자 하는 문제
- 실제 추천 시스템, Netflix처럼 장기간의 사용자 히스토리를 가지지 못함
- 특히 다음과 같은 상황에서 문제 발생 → “실무적 문제”
- 소규모 이커머스 사이트의 경우 사용자 추적이 어려움
- 쿠키나 브라우저 핑거프린팅은 신뢰성이 낮고 개인정보 문제 발생
- 뉴스, 미디어 사이트에서는 익명 사용자가 대부분
- 많은 사용자가 1-2회만 방문하고 끝남
- GDPR 등 개인정보 규제로 장기간 추적이 제한됨
- 기존 방법론의 한계
- Matrix Factorization (행렬 분해)
- User Profile이 없어, 세션 기반 추천에 적용 불가능
- User-item Matrix를 저차원 벡터로 분해하는 방식 및 익명 세션에는 부적합
- Neighborhood Methods (이웃 기반 방법)
- Item-to-Item 유사도만 고려 (“이 상품을 본 사람은 이것도 봤습니다”)
- 마지막 클릭만 사용하고 이전 클릭 정보는 무시
- 세션의 전체적인 맥락을 파악하지 못함
- Markov Decision Processes (MDP)
- 상태 공간이 기하급수적으로 증가하여 관리 불가능
- 모든 가능한 시퀀스를 고려하기 어려움
- Matrix Factorization (행렬 분해)
핵심 기여사항
- 기존 추천 시스템 방법론(MF, 이웃기반, Markov 등)이 세션 맥락과 익명 사용자 데이터에 취약하다는 한계를 지적 → 이를 극복하기 위해 세션 기반 추천문제에 적합한, RNN 기반 접근법을 제시
- Session이라는 단기적·순차적 사용자의 행동 시퀀스를 효과적으로 모델링할 수 있는 RNN(GRU) 아키텍처 도입
- 세부 사항
- RNN의 추천 시스템 적용
- 순환 신경망을 세션 기반 추천 문제에 최초로 적용
- 전체 세션 모델링
- 마지막 클릭만이 아닌 세션 전체의 시퀀스를 고려
- 실용적 개선사항 제안
- Session-parallel mini-batches
- Output sampling
- Ranking loss functions (BPR, TOP1)
- 우수한 성능: 기존 방법 대비 20-30% 성능 향상 달성
- RNN의 추천 시스템 적용
모델 구조 상세
GRU4Rec의 기본 구조: GRU
- LSTM의 변형 중 하나, output gate가 따로 없음
- 성능 면에서는 LSTM과 비교해서 우월하다고 할 수 없지만 학습할 파라미터가 더 적은 것이 장점
- Cell state와 Hidden state를 하나의 벡터로 통합
- Vanishing Gradient 문제 해결을 위해 고안된 구조
-
GRU 구성 Gate
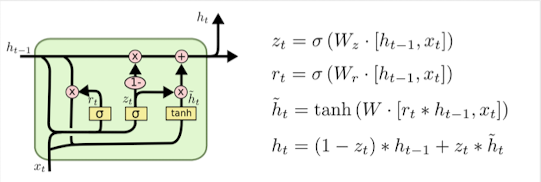
- Update gate
- 새로운 정보를 얼마나 반영할지 제어
- $z_t = \sigma(W_zx_t+U_zh_{t-1})$
- $W_z, U_z$: 학습 파라미터
- Reset gate
- 과거 정보를 얼마나 forget할지 제어
- $r_t = \sigma(W_rx_t+U_rh_{t-1})$
- $W_r, U_r$: 학습 파라미터
- $\sigma$: 시그모이드(activation function)
- Candidate activation
- 현재 입력 정보를 반영한 latent representation
- $\hat{h_t} = tanh(Wx_t+U(r_t \odot h_{t-1})$
- 최종 Hidden state 업데이트
- $h_t = (1-z_t)h_{t-1}+z_t\hat{h_t}$ → “지금까지의 클릭 히스토리를 압축한 representation vector”
- Update gate
GRU를 채택하는 이유
- LSTM보다 파라미터가 적어 학습이 빠름
- 성능도 LSTM과 Vanila RNN보다 성능이 우수함(실험결과)
모델의 입출력 구조
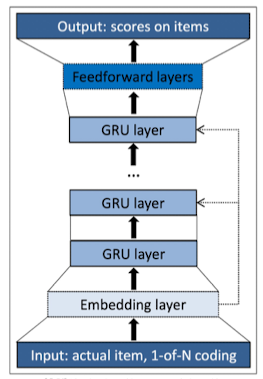
- 입력 단계: 세션 데이터의 시퀀스 표현
- 하나의 Session으로 입력 → “사용자의 행동 순서”
- 세션 $s = [i_1, i_2, i_3,…,i_T]$
- $i_t$: $t$번째 클릭된 아이템
- 입력 벡터화 과정
- 각 아이템 $i_t$는 one-hot vector로 표현
- 아이템의 총 갯수 $N$ → 입력 벡터는 길이가 N인 벡터 / 클릭한 아이템의 인덱스 위치만 1(나머지는 0)
- 그렇게 $i_t$를 입력 벡터 $x_t$로 변환 → 모델에 입력
- ex) 아이템이 [신발, 가방, 모자]라면,
- 신발 클릭 → $x_1$ 벡터로 표현 → 모델 입력
- 가방 클릭 → $x_2$벡터로 표현 → 모델 입력
- Embedding Layer
- 이렇게 변환된 one-hot vector $x_t$가 Embedding Layer 통과
- Embedding layer는 이 one-hot vector를 저차원으로 매핑함으로서
- 입력 벡터 $x_t$의 복잡도를 줄임과 동시에
- 의미적으로 비슷한 아이템들이 임베딩 공간 내에서 가까워짐
- GRU Layers
- 임베딩 레이어를 통과한 벡터들은 GRU 계층을 통과하게 됨
- 각 GRU 계층은 시퀀스 데이터를 받아 세션의 시간 정보와 맥락을 압축
- 각 GRU는 앞 단계의 hidden state와 현재의 input embedding을 받아 새로운 hidden state 생성
- 일반적으로, 다층 GRU 구조는 긴 시퀀스 혹은 복잡한 패턴을 다루는 경우에 사용됨
- 첫 번째 GRU Layer: 저수준(로컬) 시퀀스 패턴을 잡음
- 이후 상위 GRU Layers: 더 복잡하고 추상적인(글로벌한) 행동 패턴까지 포착
- 하지만, GRU4Rec 모델을 제안하는 해당 논문에서는 실제로 단일 Layer만 사용하는 것이 최적이라고 밝힘
- 여러 층의 GRU를 실험했지만, **세션 기반 데이터의 길이가 짧고 단순하기 때문에 **오히려 한 층이 가장 좋은 성능
- 다층 구조(2~3층): 훈련 손실과 Recall, MRR 지표 모두 악화됨
- 단일 GRU Layer: 모든 지표에서 최고의 성능
- 여러 층의 GRU를 실험했지만, **세션 기반 데이터의 길이가 짧고 단순하기 때문에 **오히려 한 층이 가장 좋은 성능
- 임베딩 레이어를 통과한 벡터들은 GRU 계층을 통과하게 됨
- Feedforward(Fully-connected) layers
- 맨 마지막 GRU Layer의 hidden state → Feedforward Layer(= Fully-connected Layer)로 전달
- hidden state를 통해 모든 아이템(전체 inventory)의 점수(score) 예측
- Output Layer
- 각 아이템별 점수 벡터로 Feedforward layer에서 추출된 뒤, 보통 softmax 등으로 정규화
- 각 아이템의 점수 → “다음 클릭될 가능성/선호도” 나타냄, 상위 N개가 추천 리스트 구성
- 이를 통해 최종적으로, GRU4Rec은 “지금까지 세션의 시퀀스를 보면, 다음에 클릭/구매할 아이템은 무엇일까?”를 예측하게 됨
모델의 핵심 혁신사항 3가지
- Session-parallel Mini-batches
- 도입 배경
- 기존 RNN 학습 방식(NLP에서 주로 사용) → 고정된 길이의 시퀀스를 잘라 batch로 묶음
- 그러나 세션 데이터는:
- 세션마다 길이가 다르고 (2~100 클릭 등)
- 한 세션을 잘라내면 맥락이 끊기고, 세션 전체 흐름이 손상됨
⇒ 즉, 일반적인 batch 구성법으로는 세션 단위의 의미와 순서를 보존하기 어려움 / GPU 효율 또한 낮음
- 도입 상세
-
위와 같은 문제를, 논문은 “Session-parallel Mini-batch”라는 새로운 구조를 제안하여 해결
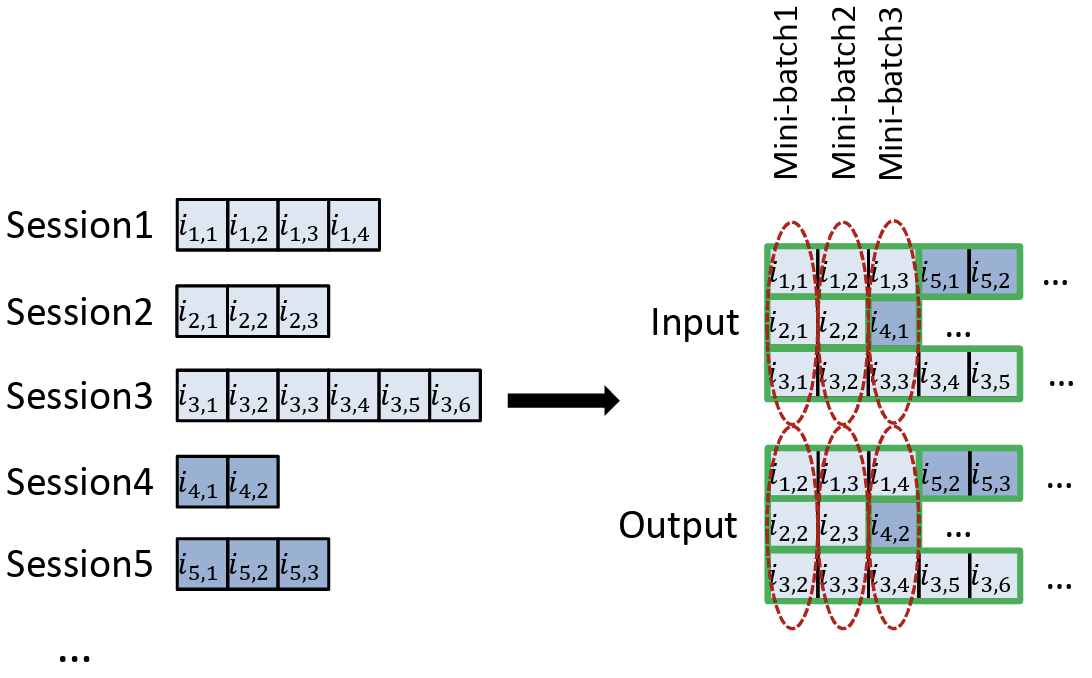
- 각 mini-batch는, 동일한 시점(index t)에 여러 세션의 동일 단계 이벤트로 구성
- GPU에서는 batch 차원을 세션 단위로 유지
- 이렇게 세션 배치를 구조화하는 주체 → “데이터로더(DataLoader) 혹은 미니배치 생성 모듈”
- 학습 데이터의 “batching 함수를 구현한 코드
- 미니 배치의 사이즈가 정해져 있고(위 예시에서는 size 3), 이를 뒤따르는 세션들이 병렬적으로 채우면서 “Input-Output” 쌍을 구성
-
-
구조적 장점
문제 Session-parallel 방식으로의 해결 세션 길이 불균형 세션별 단계 진행 → 길이가 달라도 병렬 처리 가능 세션 의미 손상 세션마다 hidden state 유지로 문맥 보존 GPU 활용 비효율 세션 swap을 통해 constant batch size 유지 → 효율 향상 일반 RNN 훈련 대비 논리적 단위(세션)를 그대로 반영하므로 추천 맥락과 일관성 유지 - 세션 기반 데이터에선, ‘사용자’ 대신 ‘세션’을 병렬 학습 단위로 취급 → 독립적인 세션의 맥락을 각자 유지하면서 여러 세션을 효율적으로 학습 가능
- 도입 배경
- Output Sampling
- 도입 배경
- RNN의 마지막 출력은 모든 아이템(N)에 대한 점수를 계산함
- 여기서, N이 수만~수십만이라면, 매 타입스텝 별로 N차원의 점수를 계산해야 하므로 메모리 요구량 폭증
- 특히, softmax/cross-entropy는 전체 아이템 공간을 필요로 하기에 더욱 치명적
- N이 늘어날수록, N개 아이템을 점수(확률값)로 변환하여 정답을 맞추는 softmax와 N개 아이템 모두에 대한 loss값을 구하는 cross-entropy는 당연히 치명타
- 도입 상세 - “Negative Sampling”
- 매 batch마다 ‘모든 아이템’을 대상으로 하지 않고, 일부는 negative sample만 사용
- GRU4Rec은, negative sample을 현재 학습 중인 mini-batch 안에서 등장한(정답이 아닌) 아이템들로 정의
- 현재(한 mini-batch에서) 학습 중인 세션들 중 정답이 아닌 아이템들을 negative sample로 간주
- ex) 배치 크기는 3, 각 세션에서 현재 클릭한 아이템이 각각 A, B, C → 특정 세션의 정답이 A일 때 negative sample로 B, C 사용
- 논문에서는 추가로 “인기(popularity) 기반” negative sampling도 시도
- 다른 사용자들 사이에서 인기있는 아이템이지만, 해당 유저의 세션에는 등장하지 않은 것
- 아이템의 인기가 높은데도 상호작용이 없었다면, 해당 아이템은 사용자가 아예 관심이 없는 아이템이라고 가정
- Negative Sampling 도입에 따른 장점
- 연산이 훨씬 빠름 → 추가 샘플링/검색과정 없이 batch 내 연산만으로 끝남
- 계산 효율 → 실제 epoch당 수만~수십만 negative 샘플링 효과
- popular item 등 더 강력한 negative를 자연스럽게 활용 가능
- 도입 배경
- Ranking-based Loss
- 도입 배경
- 추천의 본질은 분류가 아니라 순위 결정(ranking) → 모델은 정답 아이템의 점수가 다른 아이템들보다 높은지를 학습해야함
- 기존 Cross-Entropy loss → 정답을 맞히는 것(즉, 가장 점수가 높은 1등 선정)에 초점 → 하지만 추천은 올바른 순서를 매기는 것이 더 중요
- 제안된 해결책 → Pairwise / Ranking Loss 도입
- Pairwise-based loss
- 추천의 상대적 순서를 고려할 수 있도록, 두 아이템 간 비교(pairwise) 기반 손실을 사용
- 적용된 Pairwise 기반 방법론
- BPR Loss
- Positive item $i$의 점수가 Negative item $j$에 비해 높게 학습되도록
- Positive item > Negative item으로 학습, 순위에 직접 영향
- $L_{BPR} = -\frac{1}{N_S} \sum_{j=1}^{N_S} \log(\sigma(\hat{r}{s,i} - \hat{r}{s,j}))$
- TOP1 Loss
- Positive item $i$의 점수가 Negative item $j$에 비해 높으면서, Negative item 점수를 0 근처로 정규화
- 안정화 및 수렴성 향상의 효과
- $L_{TOP1} = \frac{1}{N_S} \sum_{j=1}^{N_S} \sigma(\hat{r}{s,j} - \hat{r}{s,i}) + \sigma(\hat{r}_{s,j}^2)$
- Margin loss(왼쪽 항): Positive item이 Negative item보다 점수가 높도록
- Regularization term(오른쪽 항): Negative item 점수 과도화 제어 장치
- BPR Loss
- Pairwise-based loss
- 도입 배경
-
1~3번 종합 구조 요약
단계 문제 해결책(혁신 사항) 입력 처리 세션 길이가 제각각, CPU/GPU 효율 저하 Session-parallel mini-batch로 세션병렬 처리 출력 효율 아이템 수가 너무 많아 output 계산량 폭증 Output sampling으로 계산효율 개선 학습 목적 분류 손실의 불안정, 비효율적 순위 표현 Pairwise ranking loss (BPR, TOP1)로 순위 기반 학습
Experiments
데이터셋
RSC15 (RecSys Challenge 2015)
- 이커머스 클릭스트림 데이터
- 학습: 6개월, 7,966,257 세션, 31,637,239 클릭, 37,483 아이템
- 테스트: 1일, 15,324 세션, 71,222 이벤트
VIDEO (YouTube-like OTT platform)
- 비디오 시청 데이터 (일정 시간 이상 시청)
- 학습: ~3백만 세션, ~13백만 이벤트, 330천 비디오
- 테스트: 마지막 날, ~37천 세션, ~180천 이벤트
평가 지표
Recall@20
- 상위 20개 추천 중, 정답 아이템이 포함된 비율
(실제 추천 시스템은 소수의 아이템만 추천 가능) - Click-Through Rate(CTR)와 높은 상관관계
MRR@20 (Mean Reciprocal Rank)
- 정답 아이템의 순위를 고려
- 순위가 중요한 경우 사용하는 지표(스크롤 필요 등)
- 20위 이하면 0으로 처리
실험 결과
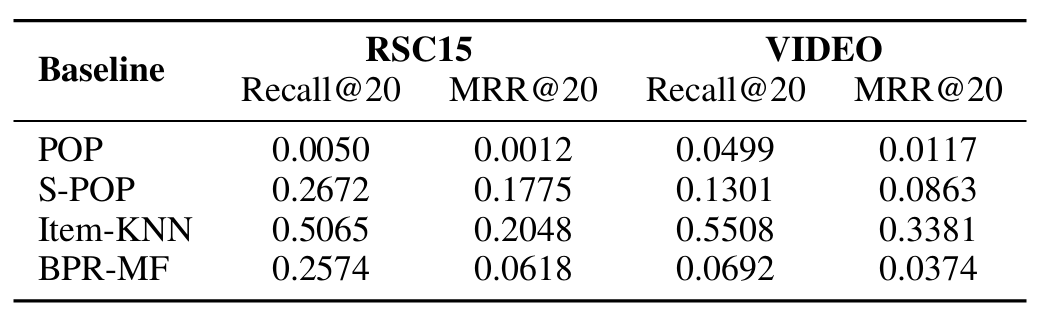
Baseline(POP, S-POP, Item-KNN, BPR-MF)의 실험 결과
- 간략한 모델 소개
- POP (Popularity-based)
- 전체 데이터에서 “가장 많이 클릭(혹은 구매)된 아이템”을 단순히 추천
- 동작: 최신 세션의 개별 행동과 무관하게, 모든 사용자에게 똑같이 인기 아이템만 추천
- 장점/한계: 매우 단순, 빠름. 그러나 개인화 없음.
- S-POP (Session-based Popularity)
- 해당 세션 내에서 가장 많이 등장한 아이템 또는 최근 많이 클릭된 아이템을 추천
- 동작: 현재 세션에 한정된 인기 상품만을 제시
- 장점/한계: 세션 기반이지만, 시퀀스/맥락은 고려하지 않고 단순 카운트만 사용
- Item-KNN (Item-to-Item k-Nearest Neighbor)
- 사용자가 마지막에 클릭한 아이템과 “유사한(other users also viewed/bought)” 아이템 추천
- 동작: 각 아이템 간 [동시 클릭/구매] 빈도(혹은 유사도 거리)를 계산해서, 가장 가까운 k개의 아이템을 추천
- 장점/한계: 세션 시퀀스 중 “마지막 행동”만 반영, 시퀀스 패턴 전체는 미반영
- 실무(아마존 등)에서 많이 쓰임
- BPR-MF (Bayesian Personalized Ranking - Matrix Factorization)
- Matrix Factorization 기반의 개인화 추천 방식, 사용자와 아이템을 벡터로 임베딩하여 BPR(순위 기반) loss로 학습
- 동작: 각 사용자-아이템 쌍에 대해, 사용자가 실제로 클릭한 아이템(positive)의 score가 임의 negative 아이템보다 높아지도록 학습
- 장점/한계: 사용자 프로파일이 필요하고, 세션/익명 사용자 데이터에는 부적합
- 장기 사용자 데이터에서는 뛰어나지만 세션 단기 정보엔 한계
- POP (Popularity-based)
- 실험 결과
- Item-KNN이 전반적으로 Baseline중에서는 가장 강력(table 1)
GRU4Rec의 성능(table 3 → BPR, TOP1)
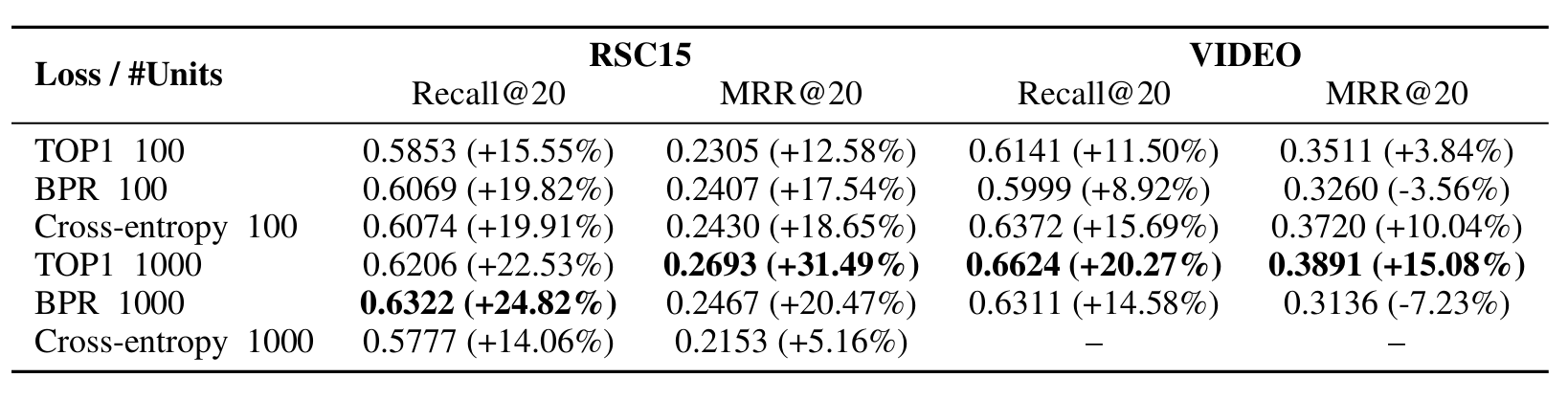
- 실험 결과
- Hidden unit을 100에서 1000으로 증가시키면 성능이 크게 향상됨
- 최대 24.82% (RSC15) 및 20.27% (VIDEO) Recall 향상(위 표에 Bold 글씨 참조)
- TOP1과 BPR 모두 우수한 성능 (데이터셋에 따라 다름)
- GPU에서 몇 시간 내 학습 가능 / 학습 시키기에 그렇게 무겁지 않음
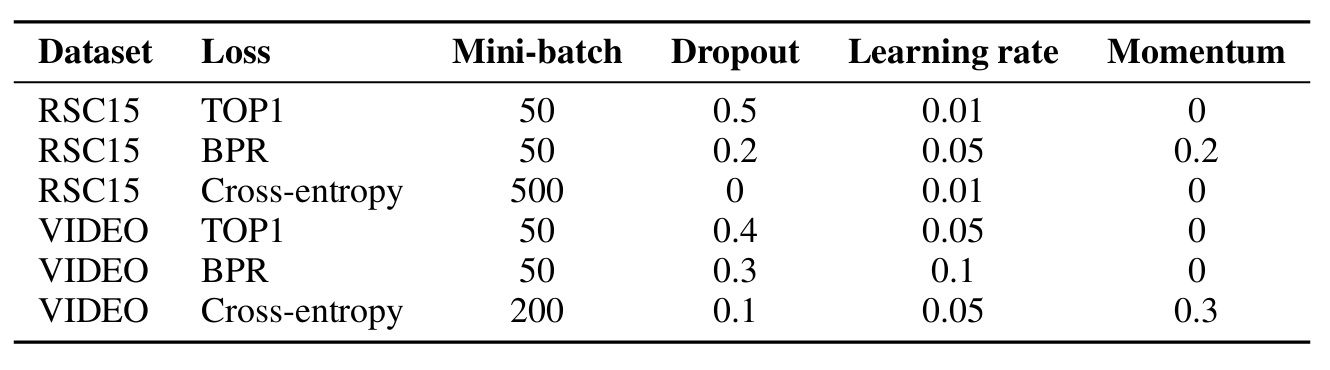
하이퍼 파라미터 설정
-
데이터셋 및 loss function에 따라 다름(table2)
GRU4Rec의 영향력 및 후속 연구
세션 기반 추천 연구의 기초 / GRU를 추천시스템에 적용한 최초 논문
- GRU4REC v2 (2018):
- Loss function 개선 (TOP1-max, BPR-max)
- Cross-entropy의 수치 안정성 개선
- 샘플 수 증가로 최대 53% 성능 향상
- SR-GNN → Graph Neural Network (GNN) 기반
- 세션을 그래프 구조로 모델링
- 아이템 간 복잡한 전이(transition) 포착
- Attention Mechanism 적용
- SR-SAN (Self-Attention Networks)
- 거리에 관계없이 모든 아이템 간 global dependency 포착
- Transformer 구조 적용
- 단일 latent vector로 현재 관심사와 전역 관심사 통합
- TNARM (Time-aware Neural Attentive Recommendation Model)
- GNN + Attention mechanism 결합
- 클릭 시간 정보 활용
- 사용자의 일반적 관심사와 주요 목적 모두 모델링
- SR-SAN (Self-Attention Networks)
- Transformer 기반 모델
- Transformers4Rec (NVIDIA Merlin):
- HuggingFace Transformers와 통합
- Sequential 및 session-based 추천에 특화
- 프로덕션 환경에 최적화
- TRON (2023):
- Top-K negative sampling + listwise loss
- SASRec 대비 18.14% CTR 증가 (A/B 테스트)
- 확장성과 성능 모두 개선
- Transformers4Rec (NVIDIA Merlin):
chat_bubble 댓글남기기
댓글남기기